
LlamaIndex基本介绍!
LlamaIndex基本介绍!
月伴飞鱼
LlamaIndex是一个开源框架,旨在帮助开发者将外部数据与大型语言模型(LLM)进行高效连接和交互。它通过索引的方式,将文档或其他数据源与 LLM 结合,从而实现更精准的问答、检索增强生成(RAG)以及其他复杂的应用。
LlamaIndex官网:https://www.llamaindex.ai/
LlamaIndex 是一个由 Jerry Liu 创建的 Python 库,用于开发基于大模型的应用程序,类似于 LangChain。
- 但它更偏向于 RAG 系统的开发。
使用 LlamaIndex,开发人员可以很方便地摄取、结构化和访问私有或领域特定数据。
- 以便将这些数据安全可靠地注入大模型中,从而实现更准确的文本生成。
索引(Index)
索引(Index) 是 RAG 系统中,它是大模型和用户数据之间的桥梁。
无论是数据库类的结构化数据,还是文档类的非结构化数据,抑或是程序类的 API 数据,都是通过索引来查询的。
- 查询出来的内容作为上下文和用户的问题一起发送给大模型,得到响应。
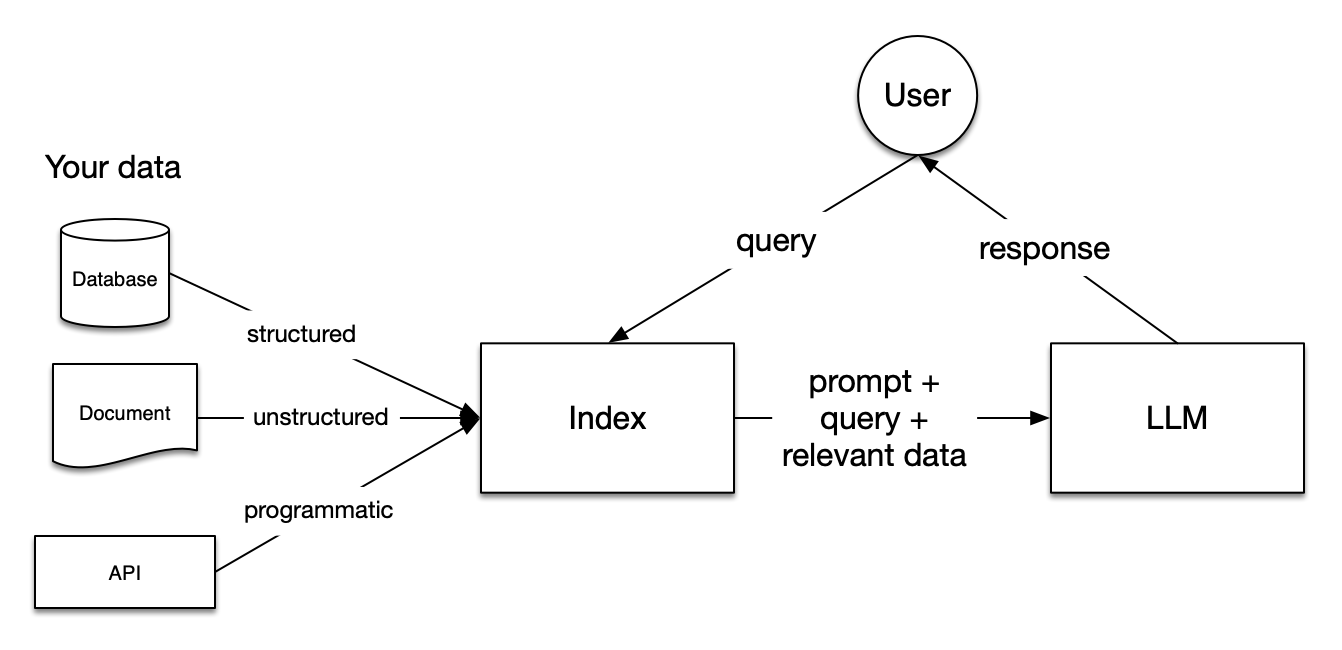
LlamaIndex 将 RAG 分为五个关键阶段:
加载(Loading):
- 用于导入各种用户数据,无论是文本文件、PDF、另一个网站、数据库还是 API。
- LlamaHub 提供了数百个的加载器。
索引(Indexing):
- 可以是 Embedding 向量,也可以是其他元数据策略,方便准确地找到上下文相关的数据。
存储(Storing):
- 对索引持久化存储,以免重复索引。
查询(Querying):
- 对给定的索引策略进行查询,包括子查询、多步查询和混合策略。
评估(Evaluation):
- 提供客观的度量标准,用于衡量查询响应的准确性、忠实度和速度。
这些阶段几乎都和索引有关,可参考 LlamaIndex 官方文档中的 Starter Tutorial 来快速入门。
首先,使用 pip 安装 LlamaIndex:
1 | $ pip3 install llama-index |
通过 LlamaIndex 提供的高级 API,初学者只需 5 行代码即可实现一个简单的 RAG 程序:
1 | from llama_index.core import VectorStoreIndex, SimpleDirectoryReader |
示例中使用了保罗·格雷厄姆的文章 What I Worked On 作为测试数据。
将其下载并保存到 data 目录,运行程序,得到下面的输出。
1 | The author worked on writing and programming before college. |
核心概念
Documents 对应任何数据源的容器,比如 PDF 文档,API 接口的输出,或从数据库中检索数据。
可以手动构造 Document 对象,也可以使用所谓的 数据连接器(Data Connectors) 来加载数据。
- 示例中使用的
SimpleDirectoryReader就是一个数据连接器。由于加载的数据可能很大,Document 通常不直接使用。
在 LlamaIndex 中,会将 Document 切分成很多很多的小块,这些文档的分块被称为 Node。
它是 LlamaIndex 中数据的原子单位,Node 中包含一些元数据,比如属于哪个文档,和其他 Node 的关联等。
将 Document 切分成 Nodes 是由 Node Parser 或 Text Splitters 完成的。
- 示例代码中并没有明确指定,用的默认的
SentenceSplitter,可以通过Settings.text_splitter来修改。一旦完成了数据的读取,LlamaIndex 就可以帮对数据进行索引,便于快速检索用户查询的相关上下文。
Index 是一种数据结构,它是 LlamaIndex 打造 RAG 的核心基础。
LlamaIndex 内置了几种不同的 Index 实现:
- 如 Summary Index,Vector Store Index、Tree Index 和 Keyword Table Index。
- How Each Index Works 这篇文档介绍了不同 Index 的实现原理。
可以看到示例代码中使用了 VectorStoreIndex,这也是目前最常用的 Index。
默认情况下
VectorStoreIndex将 Index 数据保存到内存中。
- 可以通过
StorageContext的persist()方法将 Index 持久化到本地磁盘。或指定 Vector Store 将 Index 保存到向量数据库中,LlamaIndex 集成了大量的 Vector Store 实现。
LlamaIndex 有一套完善的存储体系,除了 Vector Store。
- 还支持 Document Store、Index Store、Graph Store 和 Chat Store 等,具体内容可以参考 官方文档。
此外,在使用
VectorStoreIndex生成向量索引时,会使用 Embeddings 模型。它使用复杂的向量来表示文档内容,通过向量的距离来表示文本的语义相似性。
- 默认的 Embedding 模型为
OpenAIEmbedding,可以通过Settings.embed_model来修改。加载完文档,构造完索引,就来到 RAG 中最重要的一环:Querying。
根据用户的问题,或者是一个总结请求,或者一个更复杂的指令,检索出相关文档从而实现对数据的问答和聊天。
查询引擎(Query Engines) 是最基础也是最常见的检索方式。
通过 Index 的
as_query_engine()方法可以构建查询引擎,查询引擎是无状态的,不能跟踪历史对话。如果要实现类似 ChatGPT 的对话场景,可以通过
as_chat_engine()方法构建 聊天引擎(Chat Engines)。LlamaIndex 将查询分为三个步骤:
第一步 Retrieval 是指从 Index 中找到并返回与用户查询最相关的文档。
第二步 Node Postprocessing 表示后处理,这是在检索到结果后对其进行重排序、转换或过滤的过程。
第三步 Response Synthesis 是指将用户查询、最相关的文档片段以及提示组合在一起发送到大模型以生成响应。
查询的每个步骤 LlamaIndex 都内置了多种不同的策略,也可以完全由用户定制。
LlamaIndex 还支持多种不同的查询结合使用:
- 它通过 路由器(Routers) 来做选择,确定要使用哪个查询,从而满足更多的应用场景。
可以结合官网的 Learn、Use Cases 和 Component Guides 等文档学习 LlamaIndex 的更多功能。
查询转换(Query Transformations)
RAG 系统面临的第一个问题就是如何处理用户输入。
RAG 的基本思路是根据用户输入检索出最相关的内容,但是用户输入是不可控的,可能存在冗余、模糊或歧义等情况。
如果直接拿着用户输入去检索,效果可能不理想。
查询转换(Query Transformations) 是一组旨在修改用户输入以改善检索的方法,使检索对用户输入的变化具有鲁棒性。
查询扩展(Query Expansion)
假设你的知识库中包含了各个公司的基本信息,考虑这样的用户输入:微软和苹果哪一个成立时间更早?
要获得更好的检索效果,可以将其拆解成两个用户输入:
- 微软的成立时间 和 苹果的成立时间。
这种将用户输入分解为多个子问题的方法被称为 查询扩展(Query Expansion)。
再考虑另一个用户输入:哪个国家赢得了 2023 年的女子世界杯?该国的 GDP 是多少?
和上面的例子一样,也需要通过查询扩展将其拆分成两个子问题,只不过这两个子问题是有依赖关系的。
- 需要先查出第一个子问题的答案,然后才能查第二个子问题。
也就是说,上面的例子中可以并行查询,而这个例子需要串行查询。
查询扩展有多种不同的实现,比如:多查询检索器(Multi Query Retriever)。
MultiQueryRetriever是 LangChain 中的一个类,可根据用户输入生成子问题。
- 然后依次进行检索,最后将检索到的文档合并返回。
MultiQueryRetriever不仅可以从原始问题中拆解出子问题,还可以对同一问题生成多个视角的提问。比如用户输入:What are the approaches to Task Decomposition?大模型可以对这个问题生成多个角度的提问。
MultiQueryRetriever 默认使用的 Prompt 如下:
1 | You are an AI language model assistant. Your task is |
可以在此基础上稍作修改,就可以实现子问题拆解:
1 | 你是一个 AI 语言助手,你的任务是将用户的问题拆解成多个子问题便于检索,多个子问题以换行分割,保证每行一个。 |
在 LlamaIndex 中可以通过 Multi-Step Query Engine 或 Sub Question Query Engine 实现类似的多查询检索。
RAG 融合(RAG Fusion)
RAG Fusion和MultiQueryRetriever基于同样的思路,生成子问题并检索。它对检索结果执行 倒数排名融合(Reciprocal Rank Fusion,RRF) 算法,使得检索效果更好。
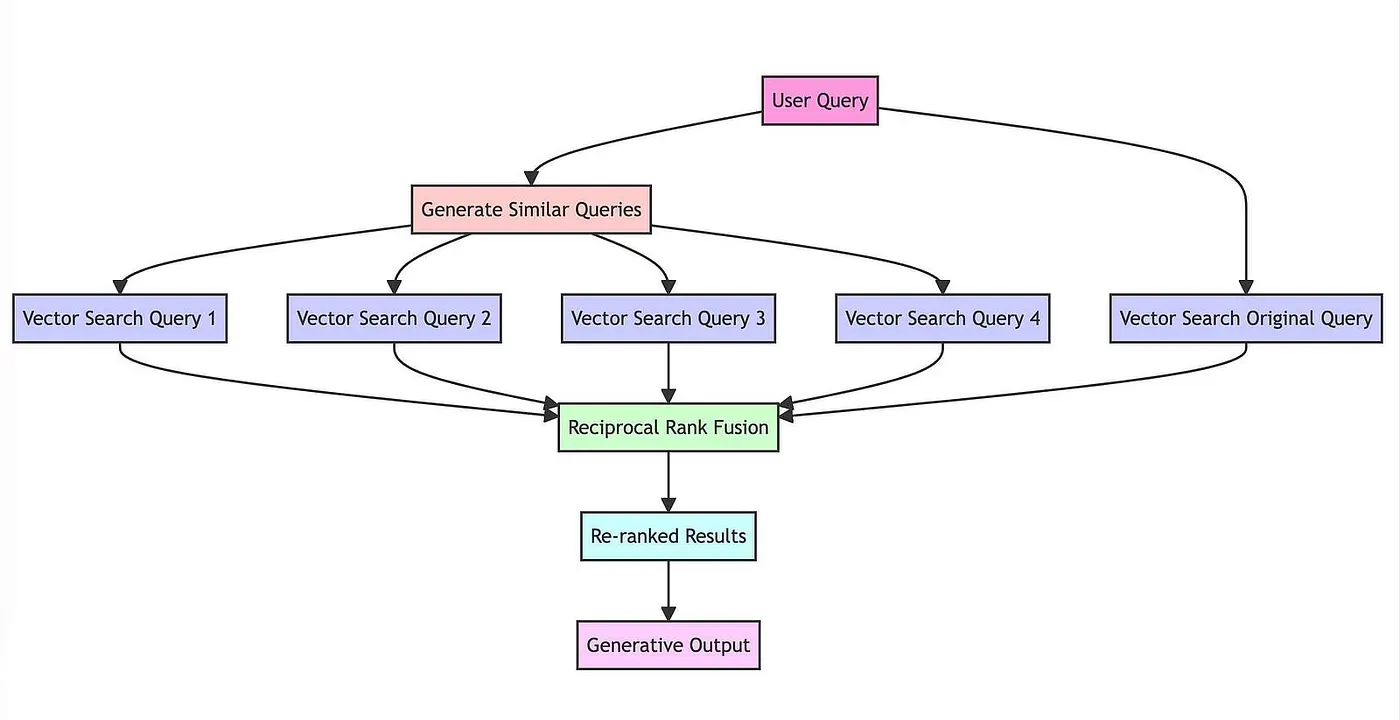
可以分为四个步骤:
首先,通过大模型将用户的问题转换为相似但不同的问题。
- 例如,气候变化的影响生成的问题可能包括 气候变化的经济后果、气候变化和公共卫生 等角度。
其次,对原始问题和新生成的问题执行并发的向量搜索。
接着,使用 RRF 算法聚合和细化所有结果。
最后,将所有的问题和重新排序的结果丢给大模型,引导大模型进行有针对性的输出。
后退提示(Step-Back Prompting)
它基于用户的原始问题生成一个后退问题,后退问题相比原始问题具有更高级别的概念或原则,从而提高解决复杂问题的效果。
例如一个关于物理学的问题可以后退为一个关于该问题背后的物理原理的问题,然后对原始问题和后退问题进行检索。
很显然,后退提示也可以在 RAG 中作为一种查询扩展的方法。
这里 是基于后退提示实现 RAG 问答的一个示例,其中生成后退问题的 Prompt 如下。
1 | You are an expert of world knowledge. I am going to ask you a question. \ |
假设性文档嵌入(Hypothetical Document Embeddings,HyDE)
当使用基于相似性的向量检索时,在原始问题上进行检索可能效果不佳。
- 因为它们的嵌入可能与相关文档的嵌入不太相似。
但是,如果让大模型生成一个假设的相关文档,然后使用它来执行相似性检索可能会得到意想不到的结果。
这就是 假设性文档嵌入(Hypothetical Document Embeddings,HyDE) 背后的关键思想。
它的思路非常有意思,首先通过大模型为用户问题生成答案,不管答案是否正确,然后计算生成的答案的嵌入,并进行向量检索。
生成的答案虽然可能是错误的,但是通过它却可能比原问题更好地检索出正确的答案片段。
这里 是 LangChain 通过 HyDE 生成假设性文档的示例。
LlamaIndex 也提供了一个类 HyDEQueryTransform 来实现 HyDE。
这里 是示例代码,同时文档也提到了使用 HyDE 可能出现的两个失败场景。
在没有上下文的情况下,HyDE 可能会对原始问题产出误解,导致检索出误导性的文档。
- 比如用户问题是 What is Bel?由于大模型缺乏上下文,并不知道 Bel 指的是 Paul Graham 论文中提到的一种编程语言。
因此生成的内容和论文完全没有关系,导致检索出和用户问题没有关系的文档。
- 对开放式的问题,HyDE 可能产生偏见。
比如用户问题是 What would the author say about art vs. engineering?
这时大模型会随意发挥,生成的内容可能带有偏见,从而导致检索的结果也带有偏见。
通过查询扩展不仅可以将用户冗余的问题拆解成多个子问题,便于更精确的检索。
而且可以基于用户的问题生成更多角度的提问,这意味着对用户问题进行全方位分析,加大了搜索范围。
- 所以会检索出更多优质内容。
但是查询扩展的最大缺点是太慢,而且费钱,因为需要大模型来生成子问题,这属于时间换效果。
- 而且生成多个问题容易产生漂移,导致大模型输出的内容过于详细甚至偏题。
查询重写(Query Rewriting)
用户输入可能表达不清晰或措辞不当,一个典型的例子是用户输入中包含大量冗余的信息,看下面这个例子:
1 | hi there! I want to know the answer to a question. is that okay? |
想要回答的真正问题是 who is maisie peters?但用户输入中有很多分散注意力的文本。
如果直接拿着原始文本去检索,可能检索出很多无关的内容。
为解决这个问题,我们可以不使用原始输入,而是从用户输入生成搜索查询。
Xinbei Ma 等人提出了一种 Rewrite-Retrieve-Read 的方法。
- 对用户的输入进行改写,以改善检索效果,这里是论文地址。
实现方法其实很简单,通过下面的 Prompt 让大模型基于用户的输入给出一个更好的查询。
1 | template = """Provide a better search query for \ |
具体实现可以参考 LangChain 的这个 cookbook。
除了处理表达不清的用户输入,查询重写还经常用于处理聊天场景中的 后续问题(Follow Up Questions)。
比如用户首先问 合肥有哪些好玩的地方?接着用户又问 那里有什么好吃的?
如果直接用最后一句话进行嵌入和检索,就会丢失 合肥这样的重要信息。
- 这时就可以用大模型来做问题重写来解决这个问题。
在开源网页搜索助手 WebLangChain 中,使用了如下的 Prompt 来实现问题重写:
1 | Given the following conversation and a follow up question, rephrase the follow up \ |
查询压缩(Query Compression)
在一些 RAG 应用程序中,用户可能是以聊天对话的形式与系统交互的。
- 为了正确回答用户的问题,需要考虑完整的对话上下文。
为了解决这个问题,可以将聊天历史压缩成最终问题以便检索,可以 参考这个 Prompt。
简单例子
1 | # 加载环境变量 |
1 | 正在运行步骤 f31bcb07-c5c0-43a2-95b9-8b4e75a1d9e8。步骤输入:比较两家公司的销售额。 |
















{kind=link}