
HuggingFace基本介绍!
HuggingFace基本介绍!
月伴飞鱼HuggingFace 可以理解为对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库。
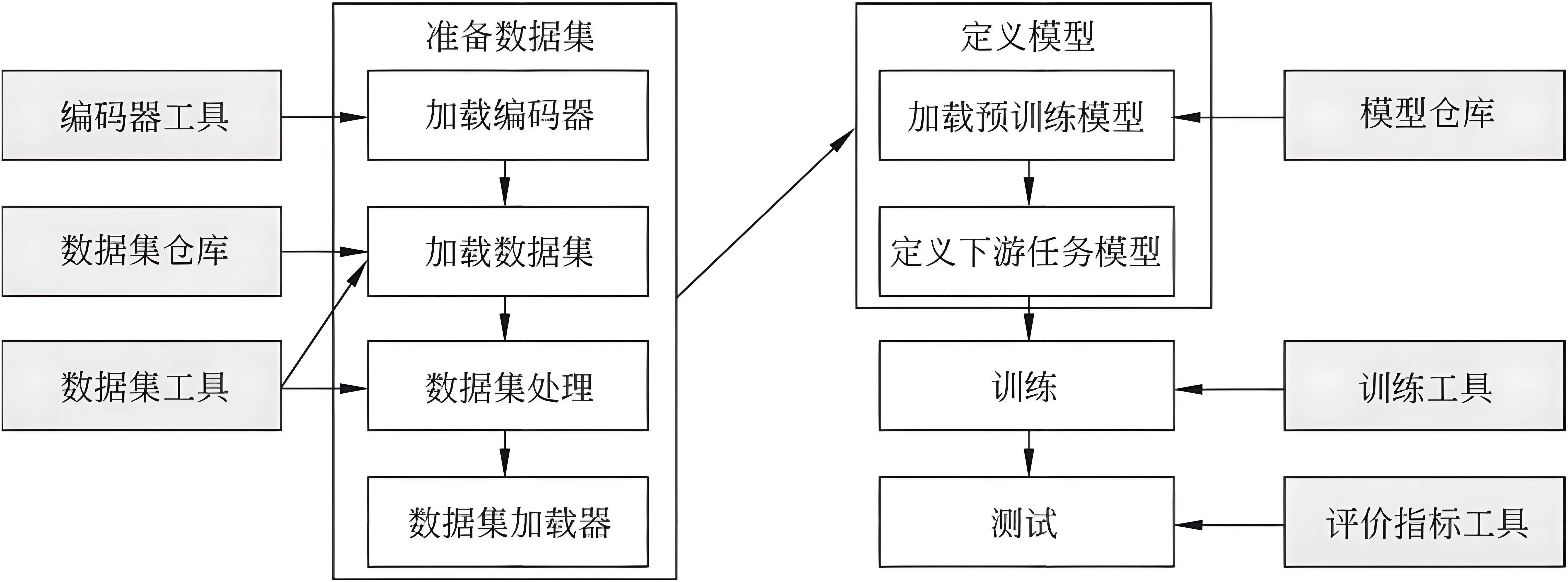
HuggingFace把AI项目的研发流程标准化,即准备数据集、定义模型、训练和测试。
Hugging Face GitHub:https://github.com/huggingface/
Hugging Face博客:https://huggingface.co/blog/zh
HuggingFace社区
HuggingFace是一个高速发展的社区。
包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。
使用官方代码快速加载模型
通过 Hugging Face 提供的
transformers库直接加载预训练模型。
BertTokenizer会自动处理文本的分词工作,BertModel则负责加载模型并初始化其权重。
1 | from transformers import BertModel, BertTokenizer |
手动下载并导入模型
在 Hugging Face 官网找到需要的模型,下载文件。
config.json(模型配置)pytorch_model.bin(模型权重)tokenizer_config.json(分词器配置)tokenizer.json(分词器的词表)vocab.txt(BERT的词汇表)
创建 model 文件夹,将这些文件放入该目录,并通过以下代码加载模型。
1 | import transformers |
模型构建
通过
BertForQuestionAnswering类初始化模型,专门用于问答任务。该模型会输出两个重要分数:
start_position(答案的起始位置)和end_position(答案的结束位置)。
1 | from transformers import BertTokenizer, BertForQuestionAnswering |
模型输入与输出
例如,给定问题李明是谁?和文章李明是个学生,模型的输出应该是学生。
1 | # 输入问题和上下文 |
解码答案:
通过
start_position和end_position提取对应的 token,从而得到答案。
1 | # 将token ID转换为词 |
















{kind=link}