
Embedding基本介绍!
Embedding基本介绍!
月伴飞鱼打造私有领域的知识库助手对于企业和个人来说是一个非常重要的应用场景,可以实现个性化定制化的问答效果。
要实现这个功能,一般有两种不同的方式:Fine Tuning 和 Embedding
Fine Tuning
Fine tuning 又被称为微调,它可以在不改动预训练模型的基础上,对特定任务进一步训练,以适应特定数据和要求。
不过官方已经不推荐使用这种方式来做知识问答任务。
因为 Fine tuning 更适合于学习新任务或新模式,而不是接受新信息。
比如可以使用 Fine Tuning 让模型按特定的语气或风格来回答问题,或者让模型按固定的格式来回答问题。
Embedding
Embedding 更适合知识问答任务,而且 Embedding 技术还顺便解决了大模型的一个问题,那就是上下文限制。
比如 OpenAI 的 GPT-3.5 模型,它的限制在 4k - 16k 个 Token,就算是 GPT-4 模型,最多也只支持 32k 个 Token。
- 所以,如果你的知识库内容长度超出了限制,就不能直接让 ChatGPT 对其进行总结并回答问题。
通过 Embedding 技术,可以使用语义搜索来快速找到相关的文档,然后只将相关的文档内容注入到大模型的上下文窗口中。
- 让模型来生成特定问题的答案,从而解决大模型的限制问题。
这种做法比 Fine Tuning 速度更快,而且不需要训练,使用上也更灵活。
使用它可以将单词表示成一个数字向量,同时可以保证相关或相似的词在距离上很接近。
Embedding 技术已经可以将任意对象向量化,包括文本、图像甚至音视频,在搜索和推荐等业务中有着广泛的应用。
使用 Embedding 实现本地知识问答处理流程
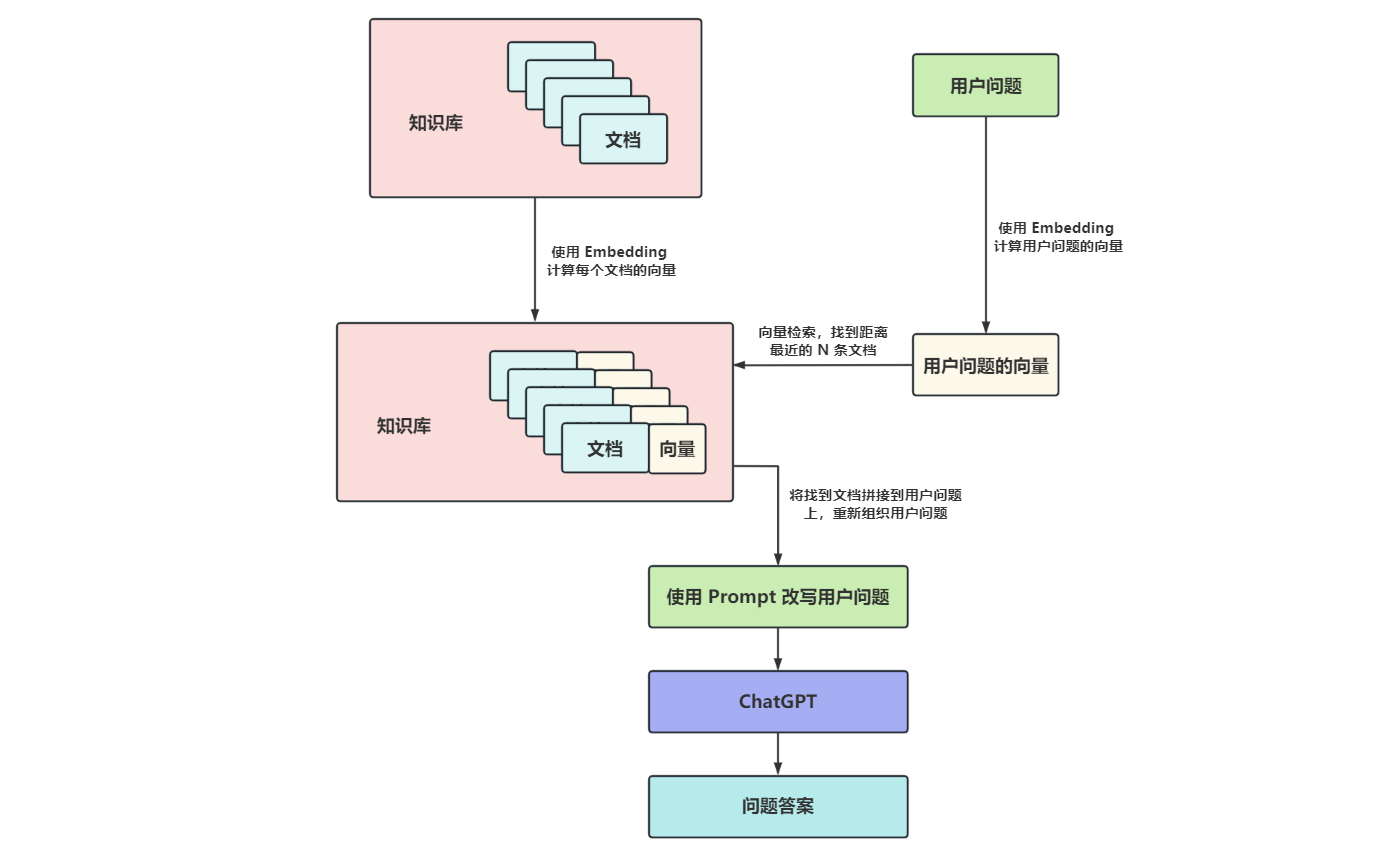
如何计算文档的向量?
对我们这种普通用户来说,可以直接使用一些训练好的模型。
开源项目 Sentence-Transformers 它封装了 大量可用的预训练模型。
另外开源项目 Towhee 不仅支持大量的 Embedding 模型,而且还提供了其他常用的 AI 流水线的实现。
- 这里是它支持的 Embedding 模型列表。
不过在本地跑 Embedding 模型对机器有一定的门槛要求,也可以直接使用一些公开的 Embedding 服务。
- 比如 OpenAI 提供的 /v1/embeddings 接口。
它使用的
text-embedding-ada-002模型是 OpenAI 目前提供的效果最好的第二代 Embedding 模型。相比于第一代的
davinci、curie和babbage等模型,效果更好,价格更便宜。
使用 OpenAI 的 Python SDK 调用该接口如下:
1 | import os |
输出的是一个长度为 1536 的数组,也可以说是一个 1536 维的向量:
1 | [ |
如何存储文档的向量?
向量数据库的公司或项目,比如 Pinecone、Weaviate、Qdrant、Chroma、Milvus 等。
很多老牌数据库厂商也纷纷加入向量数据库的阵营,比如 ElasticSearch、Cassandra、Postgres、Redis、Mongo 等。
使用 Qdrant 作为示例,首先通过 Docker 在本地启动 Qdrant 服务:
1 | $ docker run -p 6333:6333 -v $(pwd)/data:/qdrant/storage qdrant/qdrant |
然后通过下面的代码创建一个名为 kb 的向量库:
1 | from qdrant_client import QdrantClient |
注意我们指定向量维度为 1536,这是 OpenAI Embedding 输出的维度。
另外指定距离为
COSINE,它决定如何度量向量之间的相似度。
将一个文件 kb.txt 作为本地知识库,文件中的每一行代表一条知识,比如:
1 | 小红的好朋友叫小明,他们是同班同学。 |
然后读取该知识库文件,依次计算每一行的向量,并将其保存在 kb 库中:
1 | with open('kb.txt', 'r', encoding='utf-8') as f: |
在保存向量时,可以通过 payload 带上一些元数据,比如这里将原始的文本内容和向量一起保存。
这样可以方便后面检索时知道向量和原始文本的对应关系。
如何检索知识?
通过 Embedding 技术可以将任何事物表示成一个向量。
它可以保证相关或相似的事物在距离上很接近,或者说有着相似的语义。
提供了一种新的检索方式:语义搜索(Semantic Search)。
怎么计算两个向量之间的距离呢?
除了
COSINE,Qdrant 还支持使用EUCLID或DOT等方法。
COSINE:余弦相似度,计算两个向量之间的夹角,夹角越小,向量之间越相似。
EUCLID:欧几里得距离,计算两个向量之间的直线距离,距离越近,向量之间越相似。
这种度量方法简单直接,在 2 维或 3 维等低维空间表现得很好。
但是在高维空间,每个向量之间的欧几里得距离都很靠近,无法起到度量相似性的作用。
DOT:点积相似度,点积是两个向量的长度与它们夹角余弦的积,点积越大,向量之间就越相似。在语义搜索中,用的最多的是余弦相似度。
当计算出用户问题的向量之后,就可以遍历知识库中的所有向量,依次计算每个向量和问题向量之间的距离,然后按距离排序。
- 取距离最近的几条数据,就能得到和用户问题最相似的文档了。
这里存在一个问题:
如果知识库中的向量比较多,这种暴力检索的方法就会非常耗时。
为了加快检索向量库的速度,提出了很多种 ANN(Approximate Nearest Neighbor,相似最近邻)算法。
算法的基本思路是:
- 通过对全局向量空间进行分割,将其分割成很多小的子空间。
- 在搜索的时候,通过某种方式,快速锁定在某一个或某几个子空间,然后在这些子空间里做遍历。
- 可以粗略地将这些子空间认为是向量数据库的索引。
常见的 ANN 算法可以分为三大类:
基于树的方法、基于哈希的方法、基于矢量量化的方法。
比如 Annoy、KD 树、LSH(局部敏感哈希)、PQ(乘积量化)、HNSW 等。
Qdrant 针对负载数据和向量数据使用了不同的 索引策略,其中对向量数据的索引使用的就是 HNSW 算法。
通过 client.search() 搜索和问题向量最接近的 N 个向量:
1 | question = '小明家的宠物狗叫什么名字?' |
搜索出来的结果类似于下面这样,不仅包含了和问题最接近的文档,而且还有对应的相似度得分。
1 | [ |
如何向 ChatGPT 提问?
下面是一个简单的 Prompt 模板:
1 | 你是一个知识库助手,你将根据我提供的知识库内容来回答问题 |
组装好 Prompt 之后,通过 openai.ChatCompletion.create() 调用 ChatGPT 接口:
1 | completion = openai.ChatCompletion.create( |
得到 ChatGPT 的回复:
1 | 小明家的宠物狗叫毛毛。 |
















{kind=link}