MongoDB之集群!
MongoDB之集群!
月伴飞鱼
MongoDB副本集群源自于主从集群,但在主从的基础上做了很大拓展,其中总共有三种节点角色:
Primary主节点:拥有读写能力,为集群内的副本节点,提供数据拷贝的支持。Replicate副本节点:拥有读能力,数据完全拷贝自主节点,即主从概念中的从节点。Arbiter仲裁节点:不具备读写能力,用于故障恢复,提供故障检测、选举投票能力。仲裁节点作用等同于哨兵节点,但它并不是副本集群必须存在的节点。
- 因为主节点、副本节点都拥有投票能力,它的存在只是为了维护集群内的平衡。
- 如集群节点为偶数时,可以添加一个仲裁节点,让集群保持奇数特性,确保每轮选举一次就能推出新主。
- 避免多轮无效竞选的现象出现。
分片机制
以往的副本集会受到硬件配置的限制,如果写性能出现瓶颈,只能依靠拉高
CPU、内存配置来提升性能,而分片集群无需考虑这点。整个集群都是由不同节点组合对外服务,如果性能出现瓶颈,只需要继续增加分片节点即可。
- 相较于副本集群,分片集群的上限更高。
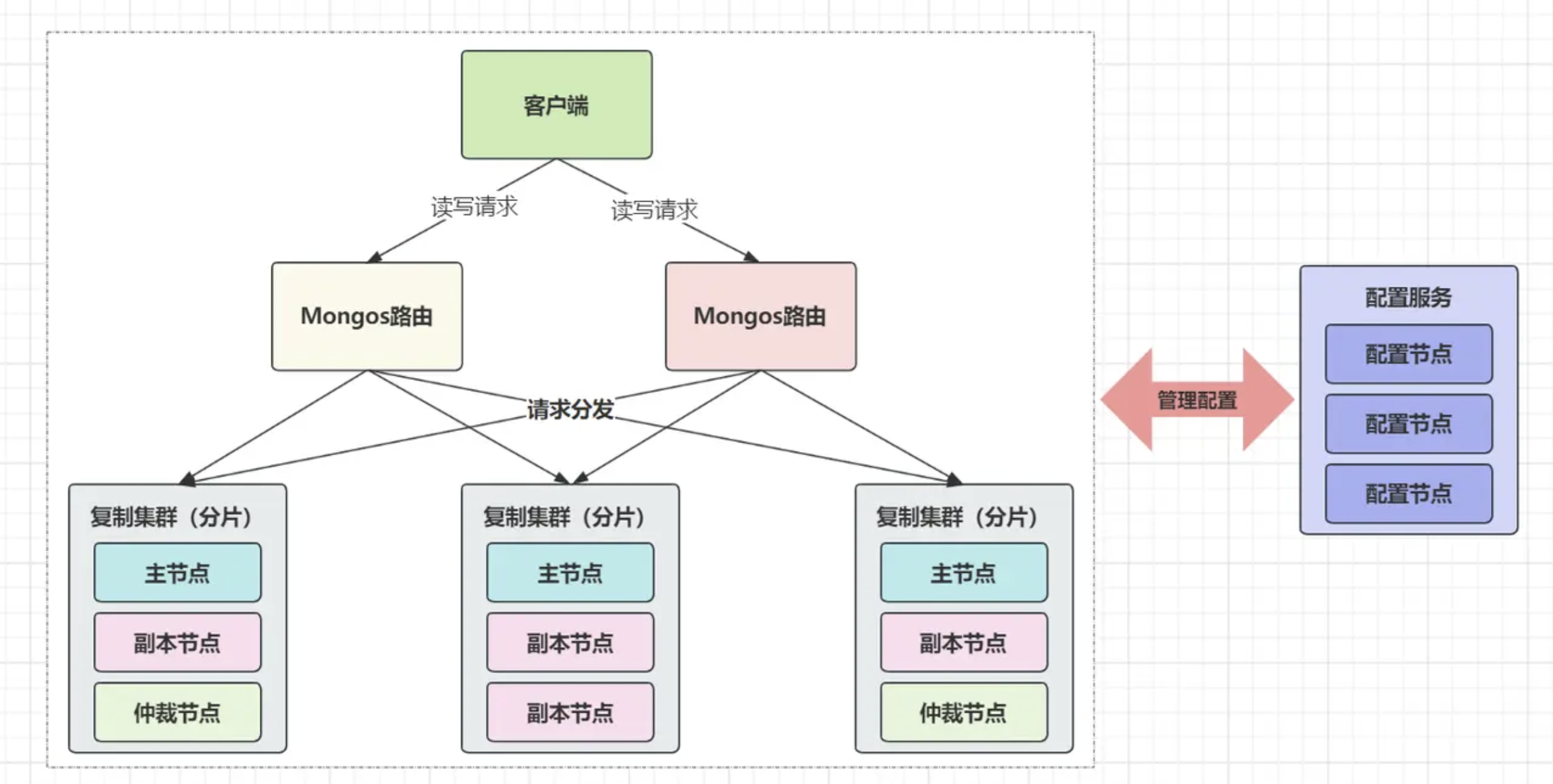
分片集群总共有三种角色:
Router路由:负责接收、分发客户端的读写请求,类似于代理中间件。Shard分片:存储数据、处理读写请求的具体节点。Config配置:存储路由、分片节点的元数据和配置信息。路由可以由一或多个
mongos节点组成,config同理。
- 而
shard则并非单独的mongodb节点,而是一个个的replicaSet复制集(副本集群)。当一个写入请求出现时,
Mongos会找到配置的分片键,再使用已配置的分片规则进行计算。
- 从而得出本次数据要落入的分片,最后将该写入请求分发到对应的分片即可。
在集群的分片动态伸缩(数量发生变化)时,会自动触发数据迁移机制。
- 由
MongoDB内部来自动维护数据的平衡,无需任何外力介入。这个功能,无论在
Redis、还是分库分表中,都需要开发者手动完成数据迁移,维护成本特别高。
集群原理
自动切主:
成为主节点的依据是:获得集群内大多数节点的投票(节点数量一半以上的票数)。
集群初始化时:
由于其他节点还未添加进集群,所以集群内只有执行初始化的这一个节点,它会给自己投一票,此时就只有它自己。
所以它会理所当然的成为集群内的第一代主节点,如果集群后续期间一直正常,则不会触发新一轮的选举。
整个集群内部的工作阶段:
故障检测:当一个节点感知到其他节点不可用时,会先发起通信向其他可用节点进行二次确认。
故障处理:如果检测到主节点不可用,从节点会将自己转换为候选人,并向其他成员宣布。
选举开始:轮次号加一,开启一轮新的选举,每个候选人节点开始向其他成员发送拉票请求。
投票开始:在一个新的选举轮次中,每个节点只能投一票,可以投给自己或者其他节点。
投票结束:所有节点已投票,或抵达本轮选举的时间限制后,将获得大多数投票的节点立为新主。
主从切换:新主会向其他节点发送 上位 消息,其他节点更新自己的配置,接受新主上位。
数据同步:完成主从切换后,从节点以新主为数据基准,校验自身数据是否完整,有缺失则同步。
上述每一步都是由
MongoDB集群自动完成,无需任何外力介入。
故障检测:
检测出一个集群节点是否故障,主要依靠心跳机制来完成,集群每个成员会以
10s一次为频率,定期向其他成员发出心跳包。
- 从而告知其他节点自己还活着。
当某个节点不再发出心跳时,其他节点将无法收到心跳包,此时会有一或多个节点率先发现问题。
- 将会判定这个没有心跳的节点出现故障。
为了避免网络波动、延迟、故障带来的误判,率先发现问题的节点,会向集群内的其他成员发起通讯。
- 从其他成员那里二次确认,是否收到了 故障节点 的心跳?
如果其他成员收到了,当前节点不会进行额外处理。
- 如果其他成员也未收到,当前节点会通知所有成员,故障节点已经下线。
- 如果其他节点均未回复,当前节点会认为自己网络出现了问题,或者整个集群不可用,当前节点会停止工作,尝试重连恢复。
还有一种情况
当从节点去主节点同步数据时,如果发现自己无法连接到主节点时。
- 这时从节点也会试图向其他节点发起通信,二次确认主节点是否故障。
故障处理:
其余节点收到故障节点下线的通知后,集群内所有存活的节点,会判断此次下线的节点身份。
- 如果是从节点或仲裁节点,存活节点只会修改自身的集群配置,将下线的节点从集群中剔除。
如果此次下线的是主节点,集群内的所有从(副本)节点,会将自己转换为候选人角色,并通知其他节点自己想成为新主。
如果集群内有仲裁节点,仲裁节点收到主节点下线的消息后,并不会将自己转变为候选人,因为仲裁节点只有投票权,没有竞选权。
选举机制
当主节点下线、并且集群内出现候选人时,整个集群会开启新的选举轮次(
term),每个轮次都会拥有一个唯一的轮次号(标识)集群内第一个成为候选人的节点,会递增轮次号,同时率先向其他节点发出选举请求,并把自己的票投给自己。
新一轮的选举可能由好几种原因触发:
- 通过心跳机制,检测到主节点不可用、并向其余节点已确认主节点下线的情况。
- 从节点同步数据,无法正常连接主节点。
- 主节点优先级降低,或具有较高优先级的新节点加入集群。
- 开发者在主节点上手动执行
rs.stepDown()命令时。
投票开始
新一轮的选举开始后,当集群内的其他从节点收到拉票请求时,可以选择给其他节点投票,或者把票投给自己。
- 向集群宣布自己也想成为新主,并向其余节点发出拉票请求。
如果收到拉票请求的节点,角色属于仲裁节点,它无法将票投给自己,只能选择投给其他节点。
集群内存在多个候选人时,仲裁节点投票时,会遵循先到先得的原则,先收到谁的拉票请求,就把自己的票投给对应节点。
如果同时收到多个候选人拉票时,此时则会通过
oplog操作日志来判断哪个节点的数据最新,该值越高的节点享有越高的竞票权。并不是所有从节点,在收到其他从节点拉票时,会把票投给自己、转变为新的候选人开始拉票。
- 只有当收到的拉票请求,其数据比自己老时,才会将票投给自己。
oplog:从节点的操作日志,用于记录主节点的写操作,一个从节点的操作日志越新,说明数据和旧主越接近。
投票结束
当集群内所有存活节点都已投票后,投票阶段将会结束,但如果集群内有节点迟迟不投票。
- 此时选举会陷入僵局,所以每轮选举都有时间限制,如果超出了该限制还未投票的节点,将会被视为弃权。
投票阶段结束后,集群各个从节点会交换各自的票数。
只有当获得大多数节点投票的从节点,才有资格成为新主,具体的数字为:集群节点数量的一半+1。
如果集群的可用节点小于数量的一半时,整个集群将会陷入不可写入状态,只处理读请求。
某些情况下,投票结束后的状况会更极端一点,比如两个从节点,获得的票数相同,推选谁成为新主?
- 此时则会比对两个从节点的
oplog,也就是看谁的数据更完整,谁就会成为新主。如果两个节点的票数、
oplog一模一样,谁作为新主?
MongoDB给每个节点设计了priority优先级的概念,每个节点的优先级默认为1,仲裁节点的为0,表示没有竞选权。特殊情况,有
A、B两个节点票数相同,但A的oplog最新,B的priority值最高,谁会成为新的主节点?
- 是
A,因为如果数据落后的B成为了新主,那么数据比它更新的A节点,还需要把多出来的那部分数据删掉,显然并不合理。如果两个节点的票数、
oplog、priority完全相同,谁会成为新主?
- 都不会,而是会触发一轮新的选举过程,重复前面的步骤,直到选出新主为止。
- 这也是为什么建议集群节点数量保持在奇数的原因,节点数量为奇数时,几乎不会出现票数持平的现象。
如果集群从节点数量为偶数,得加入一个仲裁节点,或者将某个节点的优先级调高。
- 保证极端情况下,不会由于票数持平而触发重新选举。
主从切换
新主会向其他成员发送:自己成为新主,以及选举轮次号,其余节点收到后,会先对比轮次号,是不是自己投票过的那轮选举。
如果不是,说明期间触发过新的选举,而自己没有参与进去,此时该节点会否定这次的新主,又会触发新的选举。
如果轮次号与自己投票的相同,收到信息的节点则会认可新主,接着变更自己的配置。
- 将原本的旧主标为下线状态,竞选胜利的从节点标为新主。
数据同步
在主从切换完成后,新的主节点会向所有从节点发送
oplog,以此来同步数据,其余从节点会拿自身的oplog与之比对。如果发现不完整,则会主动去新主上拉取缺少的数据,从而确保集群内所有节点的数据一致性。
如果触发了选举过程,集群将会陷入不可用状态,只有当选举、数据同步完成后,才会恢复对外部的数据读写服务。













{kind=link}