
RAG的场景及技术原理!
RAG的场景及技术原理!
月伴飞鱼大模型问题

RAG模型的核⼼思想在于通过检索与⽣成的有机结合,弥补⼤模型在处理领域问题和实时任务时的不⾜。
为什么选择RAG而不是直接将所有知识库数据交给大模型处理?
主要是因为模型能够处理的Token数有限,输入过多Token会增加成本。
更重要的是,提供少量相关的关键信息能够带来更优质的回答。
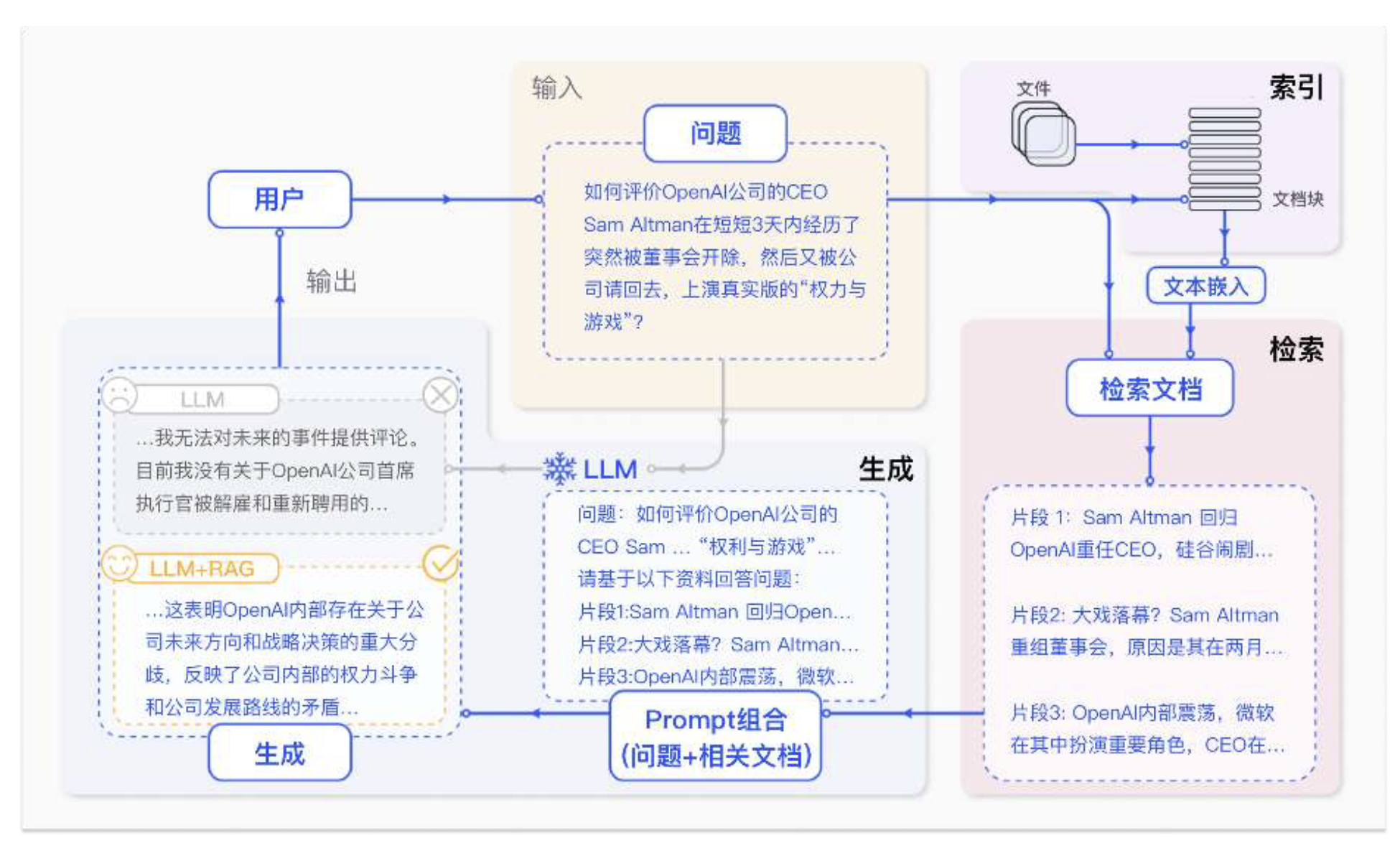
RAG标准技术流程
RAG标准流程由索引、检索和生成三个核心阶段组成:
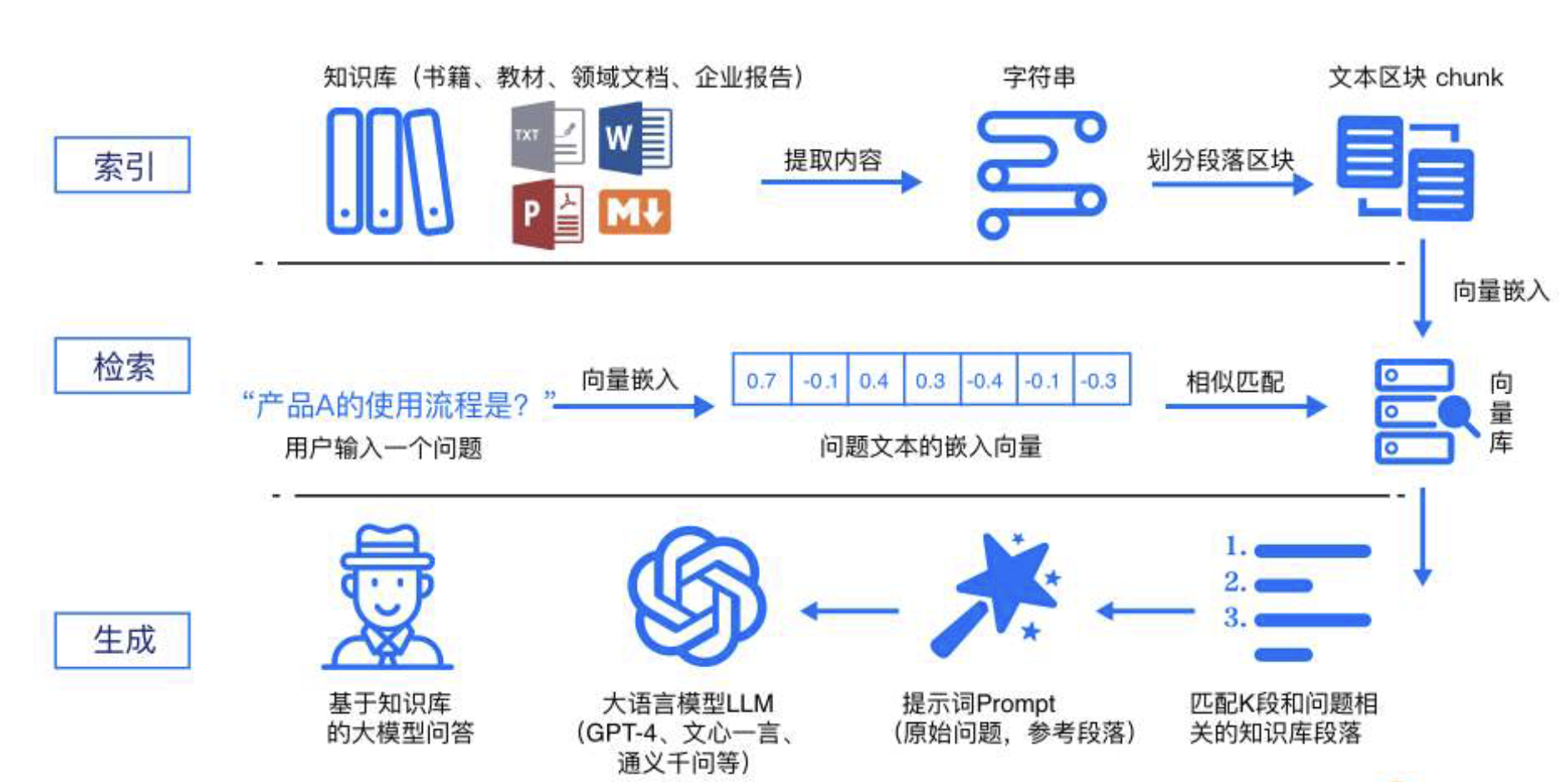
索引阶段
通过处理多种来源多种格式的文档提取其中文本,将其切分为标准⻓度的文本块,并进行嵌入向量化。
- 向量存储在向量数据库中。
检索阶段
用户输入的查询被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
最后生成阶段
检索到的相关文本与原始查询共同构成提示词,输入大语言模型,生成精确且具备上下文关联的回答。
索引
首先,将各类数据源及其格式(如书籍、教材、领域数据、企业文档等格式)统一解析为纯文本格式。
接着,根据文本的语义或文档结构,将文档分割为小而语义完整的文本块,确保系统能够高效检索和利用这些块中包含的信息。
然后,使用文本嵌入模型,将这些文本块向量化,生成高维稠密向量,转换为计算机可理解的语义表示。
最后,将这些向量存储在向量数据库中,并构建索引,完成知识库的构建。
这一流程成功将外部文档转化为可检索的向量,支撑后续的检索和生成环节。
检索
首先,用户输入的问题通过同样的文本嵌入模型转换为向量表示,将查询映射到与知识库内容相同的向量空间中。
通过相似度度量方法,检索模块从向量数据库中筛选出与查询最相关的前K个文本块,这些文本块将作为生成阶段输入的一部分。
通过相似性搜索,检索模块有效获取了与用户查询切实相关的外部知识,为生成阶段提供了精确且有意义的上下文支持。
生成
将检索到的相关文本块与用户的原始查询整合为增强提示词,并输入到大语言模型中。
LLM基于这些输入生成最终的回答,确保生成内容既符合用户的查询意图,又充分利用了检索到的上下文信息。
- 使得回答更加准确和相关,充分使用到知识库中的知识。
通过这一过程,RAG实现了具备领域知识和私有信息的精确内容生成。
RAG与微调的选择
RAG更适用于需要动态响应、频繁更新外部知识的场景,而微调则适合固定领域内的深度优化与推理。
当应用场景中既需要利用最新的外部知识,又需要保持高水平的领域推理能力时,可以考虑结合使用RAG和微调。
















{kind=link}