
从0到1快速搭建RAG应⽤!
从0到1快速搭建RAG应⽤!
月伴飞鱼技术框架与选型
技术框架:LangChain
LangChain是专为开发基于大型语言模型(LLM)应用而设计的全面框架。
其核心目标是简化开发者的构建流程,使其能够高效创建LLM驱动的应用。
索引流程:文档解析模块:pypdf
pypdf是一个开源的Python库,专⻔用于处理PDF文档。
pypdf支持PDF文档的创建、读取、编辑和转换操作,能够有效提取和处理文本、图像及⻚面内容。
索引流程:文档分块模块:RecursiveCharacterTextSplitter
采用LangChain默认的文本分割器:RecursiveCharacterTextSplitter。
该分割器通过层次化的分隔符(从双换行符到单字符)拆分文本,旨在保持文本的结构和连贯性,优先考虑自然边界如段落和句子。
索引/检索流程:向量化模型:bge-small-zh-v1.5
bge-small-zh-v1.5是由北京人工智能研究院(BAAI,智源)开发的开源向量模型。
虽然模型体积较小,但仍然能够提供高精度和高效的中文向量检索。
- 该模型的向量维度为512,最大输入⻓度同样为512。
索引/检索流程:向量库:Faiss
Faiss全称Facebook AI Similarity Search,由Facebook AI Research团队开源的向量库。
因其稳定性和高效性在向量检索领域广受欢迎。
生成流程:大语言模型:通义千问 Qwen
通义千问Qwen是阿里云推出的一款超大规模语言模型,支持多轮对话、文案创作、逻辑推理、多模态理解以及多语言处理。
在模型性能和工程应用中表现出色。
- 采用云端API服务,注册有1,000,000token的免费额度。
上述选型在RAG流程图中的应用如下所示:
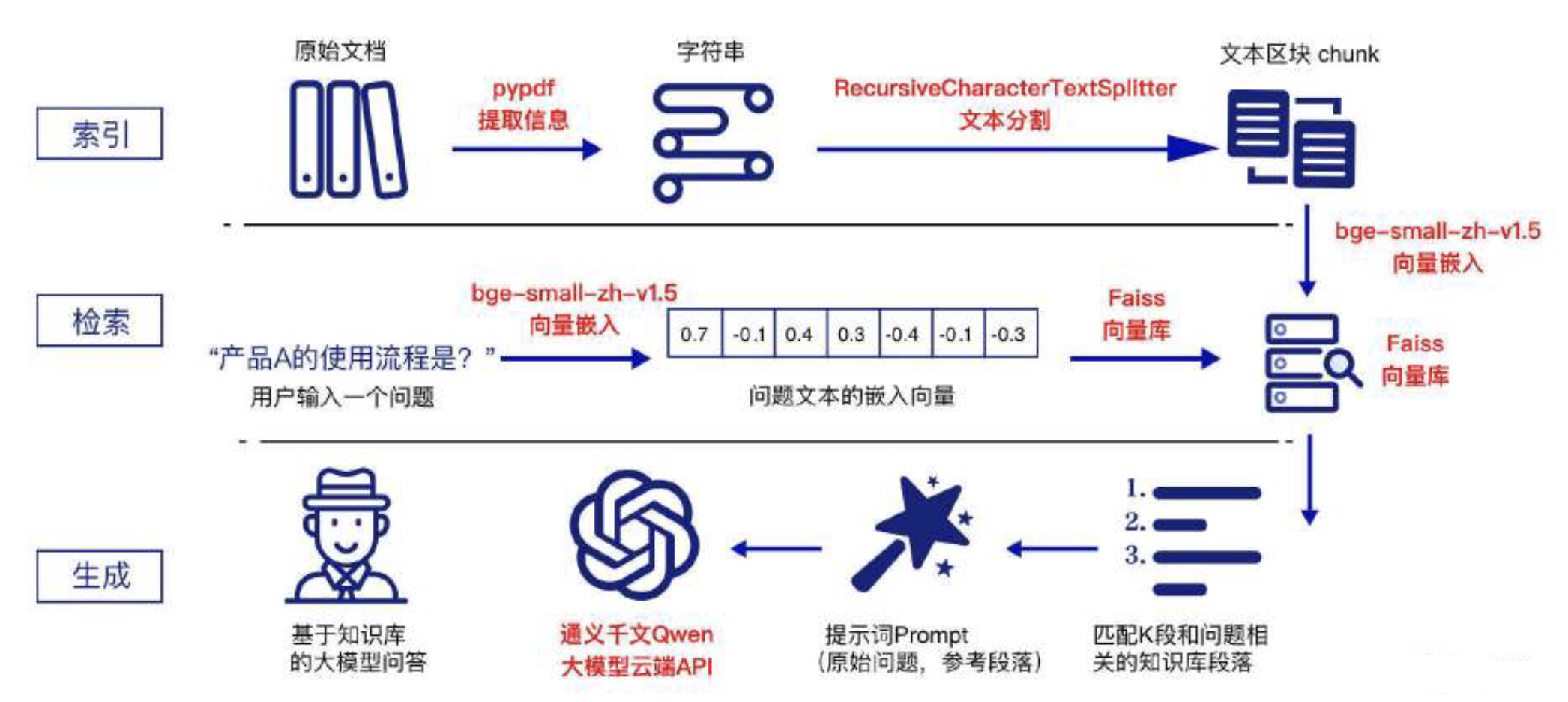
LangChain提供用于构建LLM RAG的应用程序框架。
使用pypdf对文档进行解析并提取信息。
随后,采用RecursiveCharacterTextSplitter对文档内容进行分块。
最后,利用bge-small-zh-v1.5将分块内容进行向量化处理,并将生成的向量存储在Faiss向量库中。
使用bge-small-zh-v1.5对用户的查询进行向量化处理。
然后,通过Faiss向量库对查询向量和文本块向量进行相似度匹配,从而检索出与用户查询最相似的前top-k个文本块。
通过设定提示模板,将用户的查询与检索到的参考文本块组合输入到Qwen大模型中,生成最终的 RAG 回答。
















{kind=link}