
RAG⽣成之⼤模型与Prompt提示⼯程!
RAG⽣成之⼤模型与Prompt提示⼯程!
月伴飞鱼经过RAG索引流程外部知识的解析及向量化,RAG检索流程语义相似性的匹配及混合检索,系统进入RAG生成流程。
生成流程中,首先需要组合指令,指令将携带查询问题及检索到的相关信息输入到大模型中。
- 由大模型理解并生成最终的回复,从而完成整个应用过程。
大模型原理
与传统的循环神经网络(RNN)相比,Transformer模型不依赖于序列顺序。
- 而是通过自注意力(Self-Attention)机制来捕捉序列中各元素之间的关系。
Transformer由多个堆叠的编码层(Encoder)和解码层(Decoder)组成,每一层包括自注意力层、前馈层和归一化层。
- 这些层协同工作,逐步捕捉输入数据信息特征,从而预测输出,实现强大的语言理解和生成能力。
Transformer模型的核心创新在于位置编码和自注意力机制:
位置编码帮助模型理解输入数据的顺序信息,而自注意力机制则允许模型根据输入的全局上下文。
- 为每个词元分配不同的注意力权重,从而更准确地理解词与词之间的关联性。
这种机制使得Transformer特别适用于语言模型。
- 因为语言模型需要精确捕捉上下文中的细微差别,生成符合语义逻辑的文本。
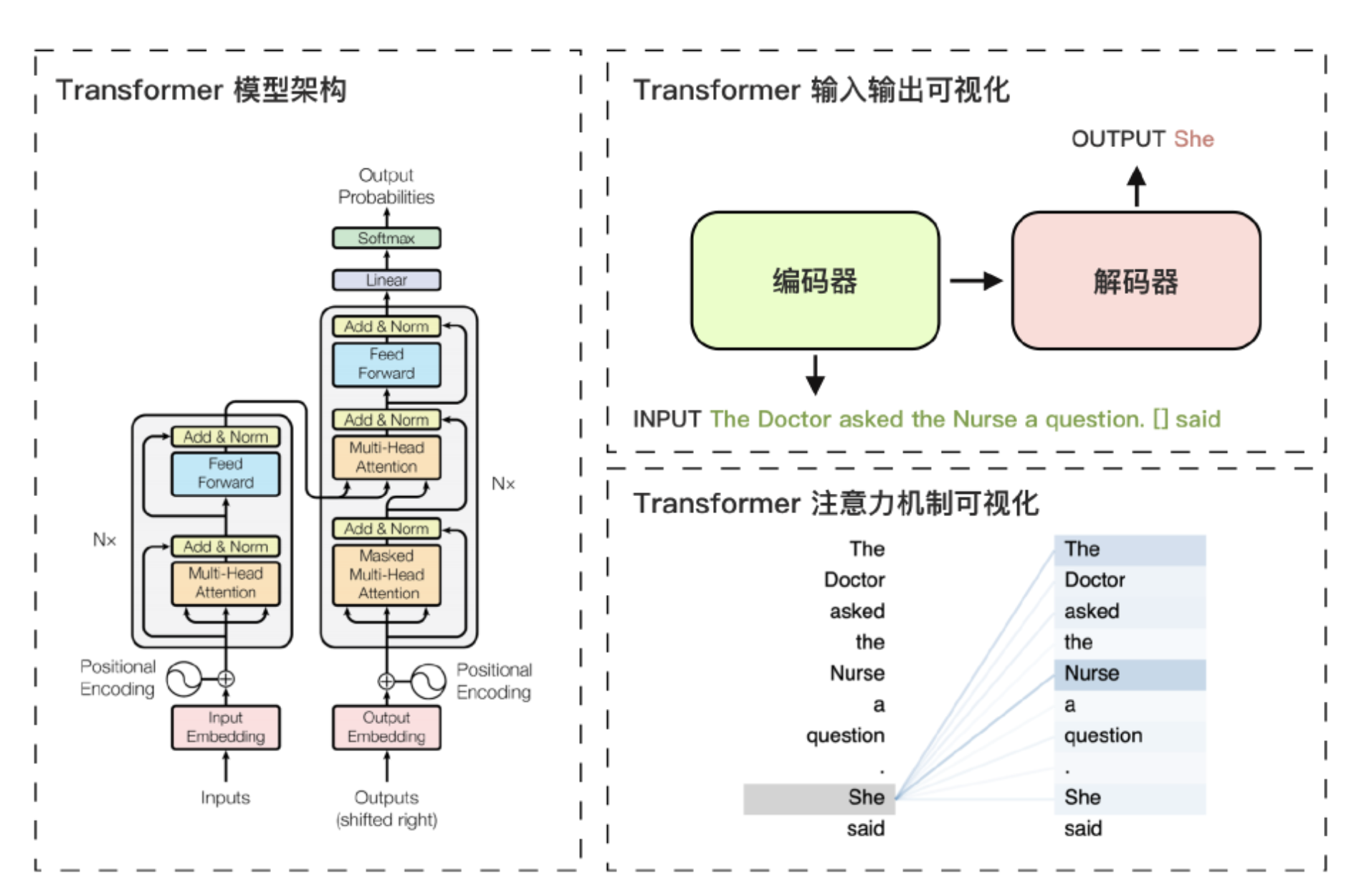
上图展示了Transformer模型的架构及其核心机制的可视化示例。
左图中,Transformer模型由编码器和解码器两部分组成。
编码器负责理解输入信息的顺序和语义,解码器则输出概率最高的词元。
右上图中的示例显示了输入句子中的填空任务。
- 解码器依据输入句子的特征和已生成的部分句子,生成了She作为模型的预测结果。
生成She的核心原因在于右下图所示的注意力机制。
其中需要填空的部分对输入句子中的词元The Doctor和Nurse分配了较高的注意力权重。
- 从而提高了She作为输出词元的生成概率。
基于Transformer模型通过预测下一个词元的原理:
大语言模型在分析了海量的语料库后,能够在逻辑上精准补全不完整的句子,甚至生成新的句子。
这一推理模式赋予了大语言模型生成连贯且上下文相关文本的能力。
- 使其在文本生成、翻译、问答系统等多个领域得到广泛应用。
RAG中如何选择大模型?
需要关注的是SuperCLUE-RAG 检索增强生成测评,在RAG场景中,大模型的检索能力表现是核心。
提示⼯程
提示⼯程(Prompt Engineering)是为⽣成式 AI 模型设计输⼊以获取最佳输出的实践。
这些输⼊被称为提示(Prompt),⽽编写这些提示的过程就是提示⼯程。
⼀个提示通常包含以下⼏类元素:
指令(Instruction):
- 指明模型要执⾏的特定任务或操作。
上下⽂(Context):
- 为模型提供额外信息或背景,可以帮助引导模型⽣成更准确的响应。
输⼊数据(Input Data):
- 我们希望模型回答的问题或感兴趣的输⼊内容。
输出指示符(Output Indicator):
- 指定模型的输出类型或格式,例如格式、是否要求⽣成代码、总结⽂本或回答具体问题。

RAG中提示⼯程的技巧
具体指令法:
通过向⼤模型提供具体、清晰的指令,能够提⾼输出的准确性。
模糊的指示往往导致模型产⽣不理想的结果,⽽具体指令则有助于模型明确任务⽬标,⽣成更符合预期的内容。
示例学习:
通过给模型提供多个参考示例,模型可以基于这些示例进⾏模式识别,进⽽模仿、思考并⽣成类似的答案。
这种⽅法在⽆需对模型进⾏进⼀步训练的情况下,有效提升了模型的输出质量。
1 | 以下是两个关于银⾏业的分析示例,请按照这种格式对新的报告进⾏分析: |
默认回复策略:
当模型⽆法从⽂档中获取⾜够信息时,通过设定默认回复策略,避免模型产⽣幻觉,即⽣成虚假的答案。
这可以确保模型仅基于⽂档中的事实进⾏回答。
1 | 如果⽂档中没有⾜够的事实回答问题,请返回{⽆法从⽂档中获得相关内容},⽽不是进⾏推测。 |
任务⻆⾊设定:
通过为模型设定特定的⻆⾊身份,可以帮助模型更好地理解任务要求和⻆⾊责任,从⽽输出更加⼀致、专业的内容。
1 | 你的⻆⾊: 知识库专家 |
解释理由法:
在编写提示时,向模型解释为什么某些任务需要特定的处理⽅式。
这样可以帮助模型更好地理解任务背景,从⽽提⾼输出的质量和相关性。
1 | 请⽣成⼀份简明扼要的银⾏业报告摘要,不要逐字重复段落内容。 |
⽂档基础说明:
为模型提供⽂档的背景信息和⽂本来源可以帮助奠定任务基础,让模型更好地进⾏任务推理和回答。
1 | 以下是关于银⾏业政策变化的相关规则,它们将⽤于回答有关政策对银⾏业影响的问题。 |
















{kind=link}