
RAG检索之混合检索与重排序技术!
RAG检索之混合检索与重排序技术!
月伴飞鱼当前主流的 RAG 检索方式主要采用向量检索,通过语义相似度来匹配文本切块。
混合检索
通过结合关键词检索和语义匹配的优势,可以首先利用关键词检索精确定位到订单12345的信息。
- 然后通过语义匹配扩展与该订单相关的其他上下文或客户操作的信息,例如12开头的订单、包装破损严重等。
这样不仅能够获取精确的订单详情,还能获得与之相关的额外有用信息。
索到的结果还需要经过优化排序:
重排序的目的是将混合检索的结果进行整合,并将与用户问题语义最契合的结果排在前列。
混合检索(多路召回)
混合检索,又称融合检索/多路召回,是指在检索过程中同时采用多种检索方式,并将各类检索结果进行融合。
- 从而得到最终的检索结果。
混合检索的优势在于能够充分利用不同检索方式的优点,弥补各自的不足,从而提升检索的准确性和效率。
为什么要使用重排序技术?
尽管向量检索技术能够为每个文档块生成初步的相关性分数,但引入重排序模型仍然至关重要。
向量检索主要依赖于全局语义相似性,通过将查询和文档映射到高维语义空间中进行匹配。
- 然而,这种方法往往忽略了查询与文档具体内容之间的细粒度交互。
重排序模型大多是基于双塔或交叉编码架构的模型:
在此基础上进一步计算更精确的相关性分数,能够捕捉查询词与文档块之间更细致的相关性,从而在细节层面上提高检索精度。
因此,尽管向量检索提供了有效的初步筛选,重排序模型则通过更深入的分析和排序。
- 确保最终结果在语义和内容层面上更紧密地契合查询意图,实现了检索质量的提升。
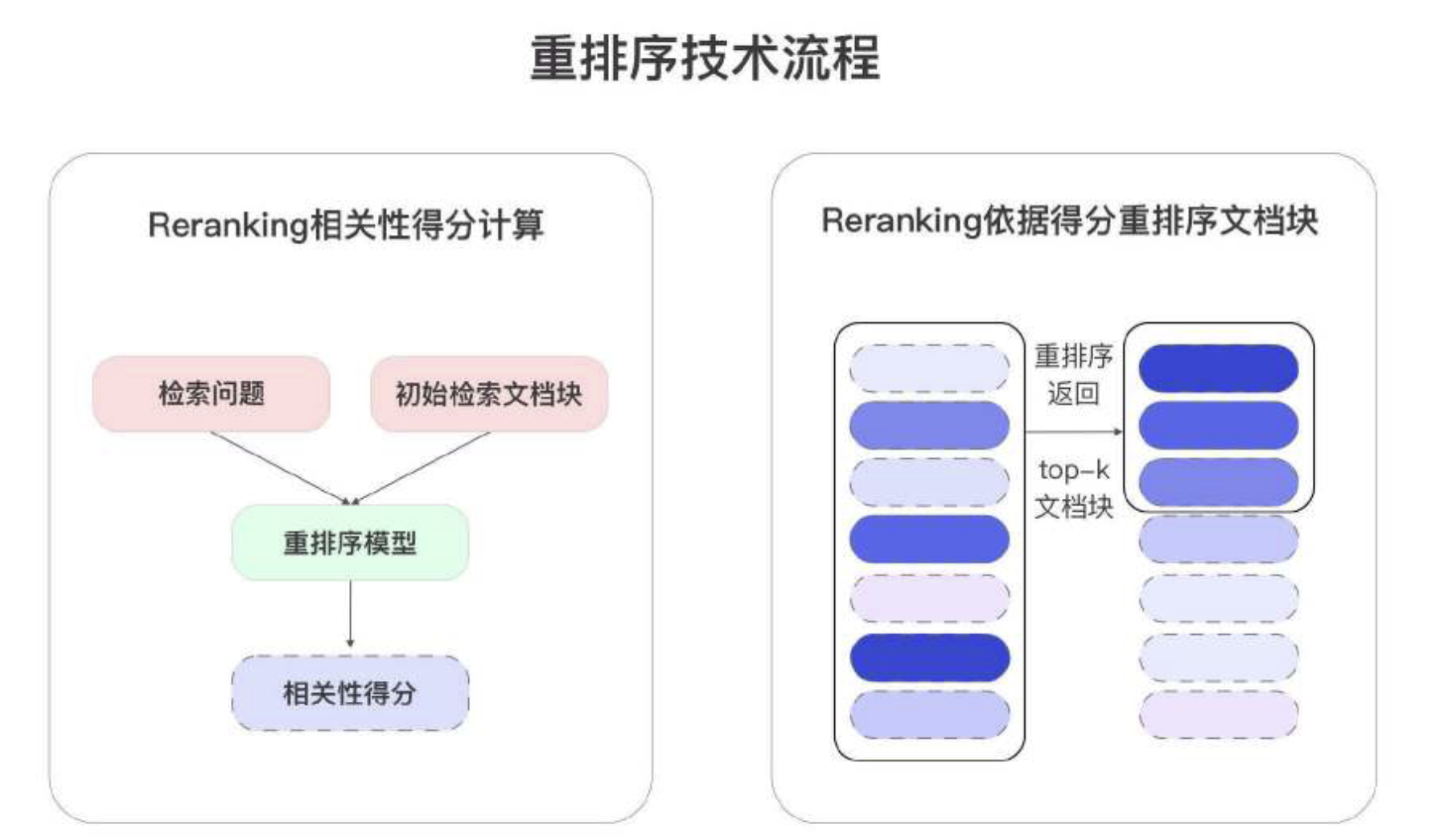
重排序模型RerankingModel
RAG流程有两个概念,粗排和精排:
粗排检索效率较快,但是召回的内容并不一定强相关。
精排效率较低,因此适合在粗排的基础上进行进一步优化。
精排的代表就是重排序。
重排序模型查询与每个文档块计算对应的相关性分数,并根据这些分数对文档进行重新排序。
- 确保文档按照从最相关到最不相关的顺序排列,并返回前Top-K个结果。
















{kind=link}