
RAG索引基本介绍!
RAG索引基本介绍!
月伴飞鱼LangChain Document Loaders文档加载器
LangChain提供了一套功能强大的文档加载器,帮助开发者轻松地将数据源中的内容加载为文档对象。
LangChain定义了BaseLoader类和Document类,其中BaseLoader类负责定义如何从不同数据源加载文档。
- 而 Document类则统一描述了不同文档类型的元数据。
分块策略与Embedding技术
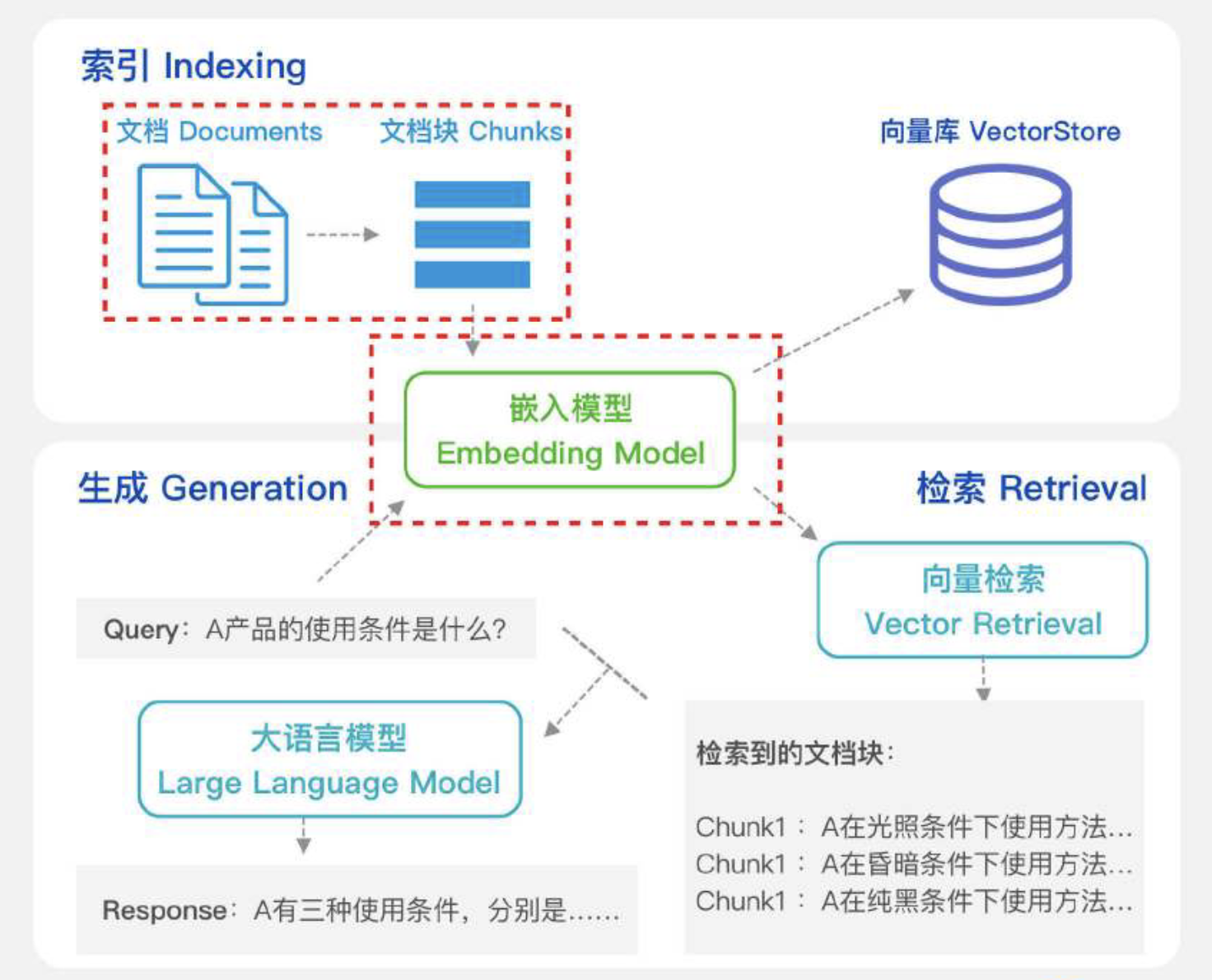
文档数据经过解析后,通过分块技术将信息内容划分为适当大小的文档片段。
- 从而使RAG系统能够高效处理和精准检索这些片段信息。
分块的本质在于依据一定逻辑或语义原则,将较⻓文本拆解为更小的单元。
嵌入模型(Embedding Model):
负责将文本数据映射到高维向量空间中,将输入的文档片段转换为对应的嵌入向量。
- 这些向量捕捉了文本的语义信息,并被存储在向量库中,以便后续检索使用。
用户查询同样通过嵌入模型的处理生成查询嵌入向量。
- 这些向量用于在向量数据库中通过向量检索匹配最相似的文档片段。
根据不同的场景需求,评估并选择最优的嵌入模型,以确保RAG的检索性能符合要求。
分块策略
分块策略最大的挑战在于确定分块的大小。
如果片段过大,可能导致向量无法精确捕捉内容的特定细节并且计算成本增加。
若片段过小,则可能丢失上下文信息,导致句子碎片化和语义不连贯。
较小的块适用于需要细粒度分析的任务,例如情感分析,能够精确捕捉特定短语或句子的细节。
更大的块则更为合适需要保留更广泛上下文的场景,例如文档摘要或主题检测。
因此,块大小的确定必须在计算效率和上下文信息之间取得平衡。
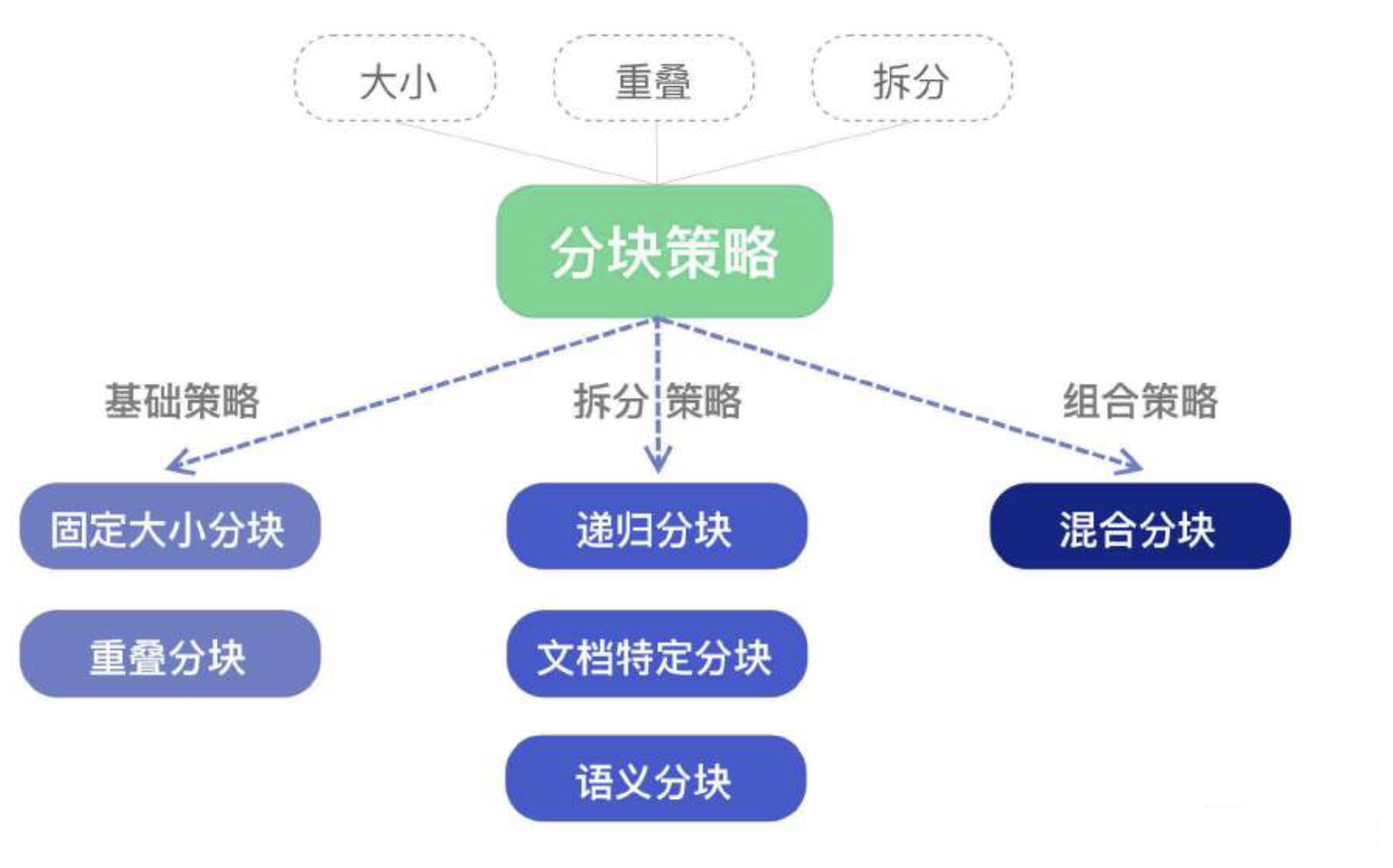
多种分块策略从本质上来看,由以下三个关键组成部分构成:
大小:每个文档块所允许的最大字符数。
重叠:在相邻数据块之间,重叠字符的数量。
拆分:通过段落边界、分隔符、标记,或语义边界来确定块边界的位置。
固定大小分块(Fixed Size Chunking)
最基本的方法是将文档按固定大小进行分块,通常作为分块策略的基准线使用。
Chunk切分可视化呈现链接:https://chunkviz.up.railway.app/
重叠分块(Overlap Chunking)
通过滑动窗口技术切分文本块,使新文本块与前一个块的内容部分重叠,从而保留块边界处的重要上下文信息。
- 增强系统的语义相关性。
虽然这种方法增加了存储需求和冗余信息,但它有效避免了在块之间丢失关键语义或句法结构。
递归分块(Recursive Chunking)
通过预定义的文本分隔符(如换行符,句号、逗号、感叹号、空格等)迭代地将文本分解为更小的块。
- 以实现段大小的均匀性和语义完整性。
此过程中,文本首先按较大的逻辑单元分割(如段落),然后逐步递归到较小单元(如句子和单词)。
- 确保在分块大小限制内保留最强的语义片段。
文档特定分块(Document Specific Chunking)
根据文档的格式(如Markdown、Latex、或编程语言如Python等)进行定制化分割的技术。
此方法依据文档的特定格式和结构规则。
- 例如Markdown的标题、列表项,或Python代码中的函数和类定义等,来确定分块边界。
通过这种方式,确保分块能够准确反映文档的格式特点,优化保留这些语义完整的单元,提升后续的处理和分析效果。
语义分块(Semantic Chunking)
基于文本的自然语言边界(如句子、段落或主题中断)进行分段的技术,需要使用NLP技术根据语义分词分句。
- 旨在确保每个分块都包含语义连贯的信息单元。
语义分块保留了较高的上下文保留,并确保每个块都包含连贯的信息,但需要更多的计算资源。
常用的分块策略有SpaCy和 NLTK 的NLP库,SpaCy适用于需要高效、精准语义切分的大规模文本处理。
- NLTK更适合教学、研究和需要灵活自定义的语义切分任务。
混合分块(Mix Chunking)
混合分块是一种结合多种分块方法的技术,通过综合利用不同分块技术的优势,提高分块的精准性和效率。
- 例如,在初始阶段使用固定⻓度分块快速整理大量文档,而在后续阶段使用语义分块进行更精细的分类和主题提取。
根据实际业务场景,设计多种分块策略的混合,能够灵活适应各种需求,提供更强大的分块方案。
















{kind=link}