HDFS是存储的王者!
HDFS是存储的王者!
月伴飞鱼
Hadoop分布式文件系统HDFS的设计目标是管理数以千计的服务器、数以万计的磁盘。将这么大规模的服务器计算资源当作一个单一的存储系统进行管理。
- 对应用程序提供数以PB计的存储容量,让应用程序像使用普通文件系统一样存储大规模的文件数据。
HDFS如何实现大数据高速、可靠的存储和访问
HDFS是在一个大规模分布式服务器集群上,对数据分片后进行并行读写及冗余存储。
因为HDFS可以部署在一个比较大的服务器集群上,集群中所有服务器的磁盘都可供HDFS使用。
- 所以整个HDFS的存储空间可以达到PB级容量。
核心原理
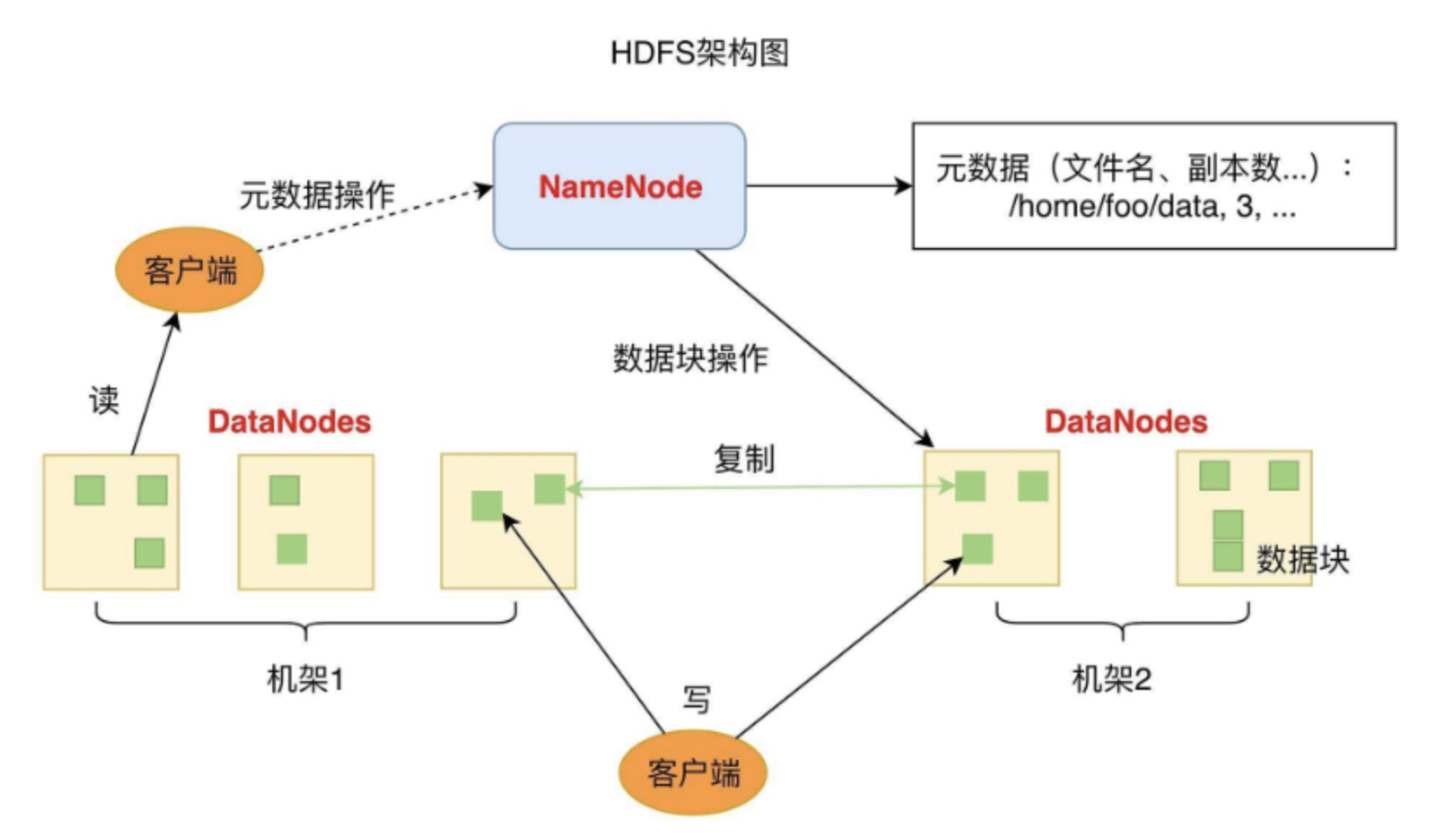
DataNode负责文件数据的存储和读写操作,HDFS将文件数据分割成若干数据块(Block)。
- 每个DataNode存储一部分数据块,这样文件就分布存储在整个HDFS服务器集群中。
应用程序客户端可以并行对这些数据块进行访问。
- 从而使得HDFS可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。
在实践中,HDFS集群的DataNode服务器会有很多台。
- 一般在几百台到几千台这样的规模,每台服务器配有数块磁盘,整个集群的存储容量大概在几PB到数百PB。
NameNode负责整个分布式文件系统的元数据管理。
- 也就是文件路径名、数据块的ID以及存储位置等信息,相当于操作系统中文件分配表(FAT)的角色。
HDFS为了保证数据的高可用,会将一个数据块复制为多份(缺省情况为3份)。
- 并将多份相同的数据块存储在不同的服务器上,甚至不同的机架上。
这样当有磁盘损坏,或者某个DataNode服务器宕机,甚至某个交换机宕机。
- 导致其存储的数据块不能访问的时候,客户端会查找其备份的数据块进行访问。
HDFS的高可用设计
常用的保证系统可用性的策略有冗余备份、失效转移和降级限流。

















{kind=link}