
大模型的微调和预训练!
大模型的微调和预训练!
月伴飞鱼Transformer是几乎所有预训练模型的核心底层架构。
- 基于Transformer预训练所得的大规模语言模型也被叫做基础模型(Foundation Model 或Base Model)。
在预训练模型出现的早期,BERT毫无疑问是最具代表性的,也是影响力最大的模型。
- BERT通过同时学习文本的前向和后向上下文信息,实现对句子结构的深入理解。
BERT之后,各种大型预训练模型如雨后春笋般地涌现,自然语言处理(NLP)领域进入了一个新时代。
这些模型推动了NLP技术的快速发展,解决了许多以前难以应对的问题。
- 比如翻译、文本总结、聊天对话等等,提供了强大的工具。
预训练+微调的模式
大型预训练模型的确是工程师的福音。
因为,经过预训练的大模型中所习得的语义信息和所蕴含的语言知识,能够非常容易地向下游任务迁移。
NLP应用人员可以对模型的头部或者部分参数根据自己的需要进行适应性的调整。
- 这通常涉及在相对较小的有标注数据集上进行有监督学习,让模型适应特定任务的需求。
预训练模型的微调(Fine-tuning)。
微调过程相比于从头训练一个模型要快得多,且需要的数据量也要少得多。
- 这使得作为工程师的我们能够更高效地开发和部署各种NLP解决方案。
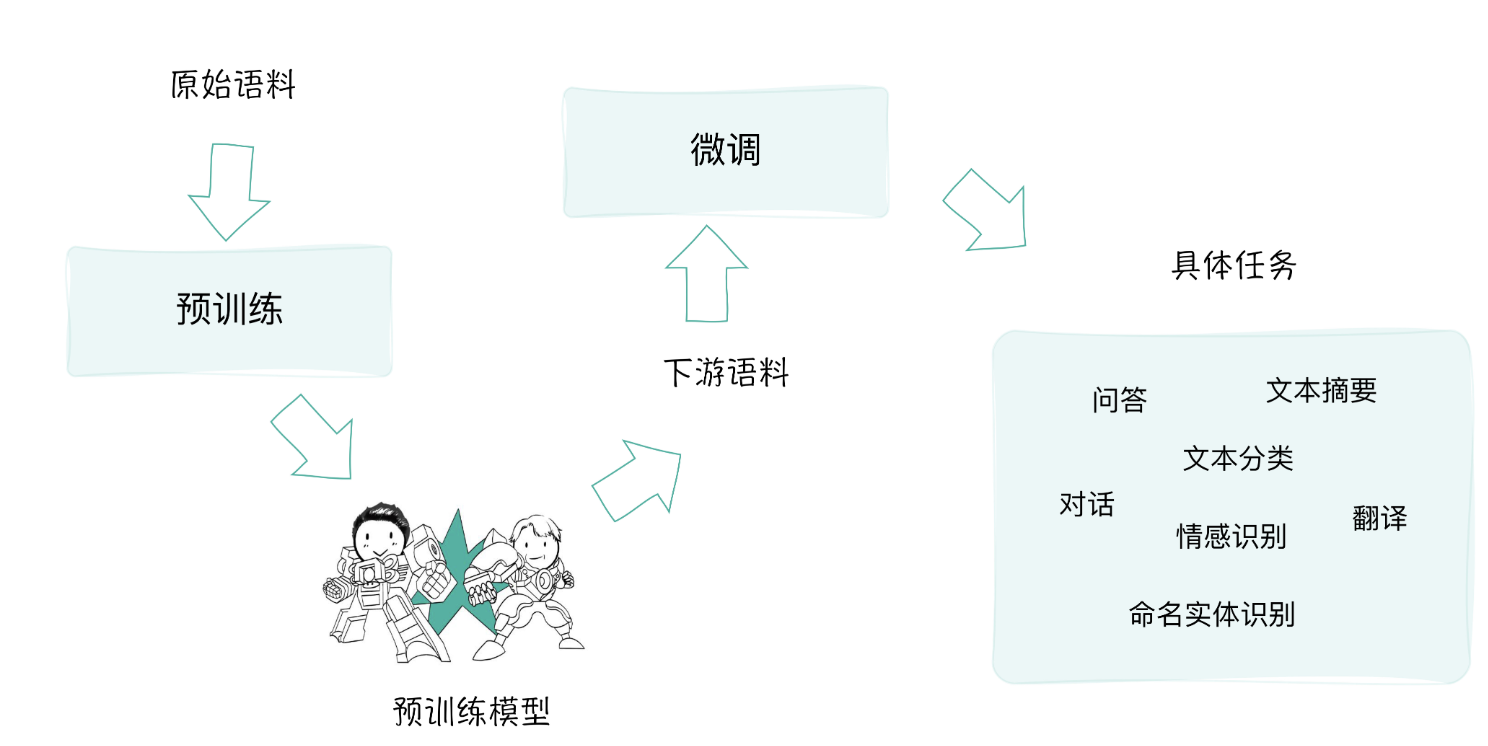
预训练:
在大规模无标注文本数据上进行模型的训练,目标是让模型学习自然语言的基础表达、上下文信息和语义知识。
- 为后续任务提供一个通用的、丰富的语言表示基础。
微调:
在预训练模型的基础上,可以根据特定的下游任务对模型进行微调。
















{kind=link}