什么是分库分表?
什么是分库分表?
月伴飞鱼分库分表是在海量数据下,由于单库、表数据量过大,导致数据库性能持续下降的问题,演变出的技术方案。
为什么分库分表
单机数据库的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。
当单表数据量千万以上时,数据库很多操作性能下降严重。
如何分库分表
垂直分库:
垂直分库一般来说按照业务和功能的维度进行拆分,将不同业务数据分别放到不同的数据库中。
垂直分表:
垂直分表针对业务上字段比较多的大表进行的,一般是把业务宽表中比较独立的字段。
- 或者不常用的字段拆分到单独的数据表中,是一种大表拆小表的模式。
水平分库:
水平分库是把同一个表按一定规则拆分到不同的数据库中,每个库可以位于不同的服务器上,以此实现水平扩展。
水平分表:
水平分表是在同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。
数据存在哪个库的表
取模算法:
以
t_order订单表为例,先给数据库从 0 到 N-1 进行编号。对
t_order订单表中order_no订单编号字段进行取模hash(order_no) mod N,得到余数i。
i=0存第一个库,i=1存第二个库,i=2存第三个库,以此类推。
优点:
实现简单,数据分布相对比较均匀,不易出现请求都打到一个库上的情况。
缺点:
对集群的伸缩支持不太友好。
如果机器数减少,算法发生变化
hash(user_id) mod N-1,同一用户数据落在了在不同数据库中。
- 等这台机器恢复,用
user_id作为条件查询用户数据就会少一部分。
范围限定算法:
用户表
t_user被拆分成t_user_1、t_user_2、t_user_3三张表。后续将
user_id范围为1 ~ 1000w的用户数据放入t_user_1,1000~ 2000w放入t_user_2,2000~3000w放入t_user_3,以此类推。
优点:
单表数据量是可控的。
水平扩展简单只需增加节点即可,无需对其他分片的数据进行迁移。
缺点:
由于连续分片可能存在
数据热点。比如按时间字段分片时,如果某一段时间(双11等大促)订单骤增,存11月数据的表可能会被频繁的读写。
- 其他分片表存储的历史数据则很少被查询,导致数据倾斜,数据库压力分摊不均匀。
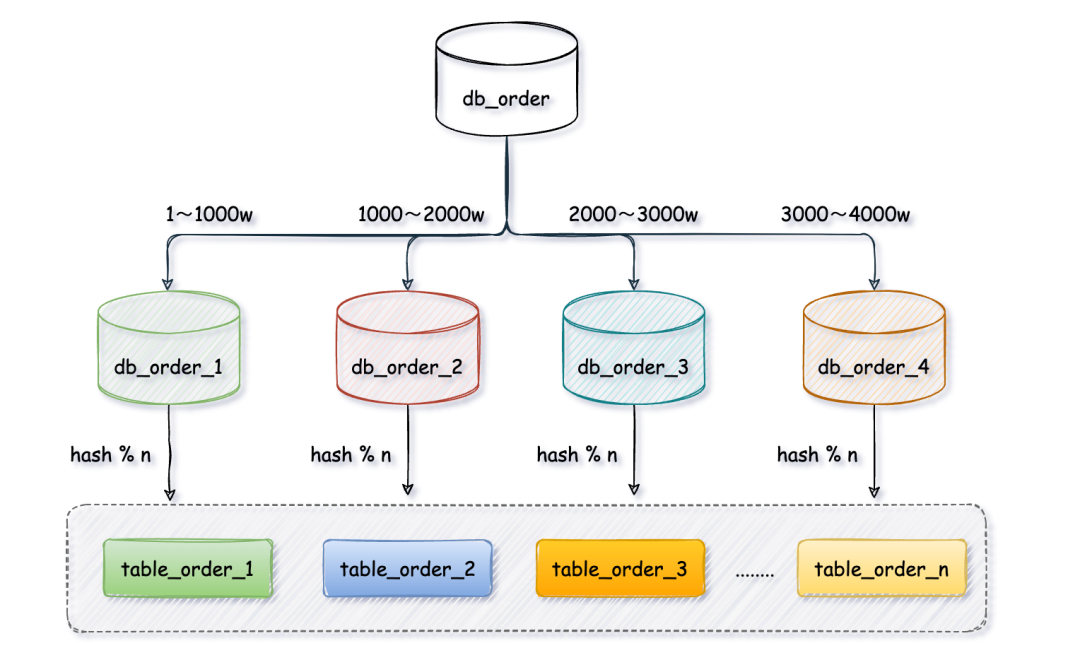
范围 + 取模算法
先通过范围算法定义每个库的用户表
t_user只存1000w数据。
- 第一个
db_order_1库存放userId从1 ~ 1000w,第二个库1000~2000w,第三个库2000~3000w,以此类推。每个库里再把用户表
t_user拆分成t_user_1、t_user_2、t_user_3等,对userd进行取模路由到对应的表中。有效的避免数据分布不均匀的问题,数据库水平扩展也简单,直接添加实例无需迁移历史数据。
分库分表出来的问题
分页、排序、跨节点联合查询。
事务一致性。
全局唯一的主键。
分库分表架构模式
客户端模式:
指分库分表的逻辑都在你的系统应用内部进行控制,应用会将拆分后的SQL直连多个数据库进行操作,然后本地进行数据的合并汇总等操作。
代理模式:
将应用程序与MySQL数据库隔离,业务方的应用不在需要直连数据库,而是连接
Proxy代理服务。
- 代理服务实现了
MySQL的协议,对业务方来说代理服务就是数据库,它会将SQL分发到具体的数据库进行执行,并返回结果。
如何部署上线
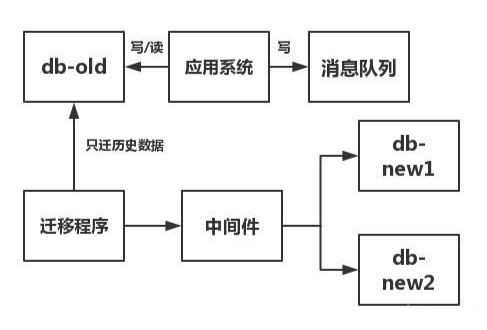
双写部署法:
假设一张叫
test_tb的表进行拆分,你要进行双写,系统里和test_tb表有关的业务会加入一段双写代码,同时往老库和新库中写,然后进行部署。
历史数据:在部署前,数据库表
test_tb的有关数据。增量数据:在部署后,数据库表
test_tb的新产生的数据。
迁移流程:
计算你要迁移的那张表的 max(主键) 。
在迁移过程中,只迁移
db-old中test_tb表里主键小等于该 max(主键) 的值:历史数据。与
test_tb有关的业务,多加一条往消息队列中发消息的代码,将操作的写SQL发送到消息队列中:增量数据。
如何选择分表键
分表键,即用来分库/分表的字段,你以哪个维度来分库分表的。
- 比如你按用户ID分表、按时间分表、按地区分表,这些用户ID、时间、地区就是分表键。
一般数据库表拆分的原则,需要先找到业务主题。
- 比如你的数据库表是一张企业客户信息表,就可以考虑用了客户号做为
分表键。
分库分表后非分片键如何查询
基因法:
将分片键的信息保存在想要查询的列中,这样通过查询的列就能直接知道所在的分片信息,叫做基因法。
- 基因法的原理理论:对一个数取余2的n次方,那么余数就是这个数的二进制的最后n位数。
这样实现的缺点是,主键值会变大一些,存储也会相应变大,这样空间换时间的设计。
- 实际上淘宝的订单号也是这样构建的。
假如现在根据
user_id进行分片,采用user_id % 16的方式来进行数据库路由,这里的user_id%16。
- 其本质是
user_id的最后4个bit位log(16,2) = 4决定这行数据落在哪个分片上,这4个bit就是分片基因。
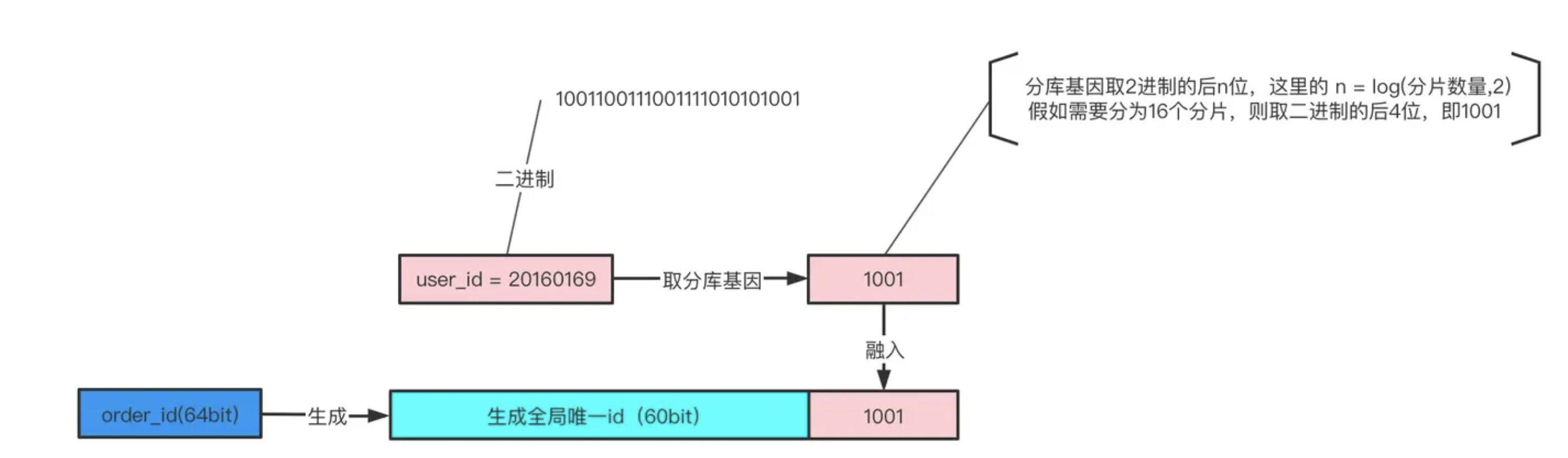
如上图所示,
user_id=20160169的用户创建了一个订单(20160169的二进制表示为:1001100111001111010101001)
- 使用
user_id%16分片,决定这行数据要插入到哪个分片中。- 分库基因是
user_id的最后4个bit,log(16,2) = 4,即1001。- 在生成
order_id时,先使用一种分布式ID生成算法生成前60bit(上图中绿色部分)。- 将分库基因加入到
order_id的最后4个bit(上图中粉色部分)。- 拼装成最终的64bit订单
order_id(上图中蓝色部分)。这样保证了同一个用户创建的所有订单都落到了同一个分片上,
order_id的最后4个bit都相同,于是:
- 通过
user_id %16能够定位到分片。- 通过
order_id % 16也能定位到分片。

















{kind=link}