
JVM三色标记算法!
JVM三色标记算法!
月伴飞鱼安全点
程序执行时并非在所有地方都能停顿下来开始GC,只有在特定的位置才能停顿下来开始GC,这些位置称为安全点(Safepoint)。
当JVM触发GC时,首先会让所有的用户线程到达安全点SafePoint时阻塞,也就是STW,然后枚举根节点。
即找到所有的GC Roots,然后就可以从这些GC Roots向下搜寻,可达的对象就保留,不可达的对象就回收。
三色标记算法
根据
CMS的运行过程来看,它的低停顿是在并发标记、并发收集阶段,做成并行,而没有STW但是这样做会带来一个问题:
- 由于用户程序的执行,对象的状态很容易发生变化,原本有
GC Roots引用的对象
- 现在没有
GC Roots引用了或者原本是垃圾对象,后面又复活了,又不是垃圾对象了
- 引用状态的改变,对JVM来说是很不可控的一种行为。
为了解决这个问题,JVM引入了三色标记这个解决方案。
GCRoot如果想查找到存活对象,会根据可达分析算法分析,遍历整个引用链。
按照是否访问过该对象分成三种不同的颜色:
- 白色、灰色、黑色。
白色:
对象没有被访问过 (没有被
GCRoot扫描过,有可能是为垃圾对象)。
灰色:
对象已经被访问过(被
GCRoot扫描过)
- 且对象中的属性没有被GCRoot扫描,该对象就是为灰色对象。
如果该对象的属性被扫描的情况下,从灰色变为黑色。
黑色:
对象已经被访问过(被
GCRoot扫描过),且本对象中的属性已经被GCRoot扫描过。
- 该对象就是为黑色对象。
三色标记算法原理:
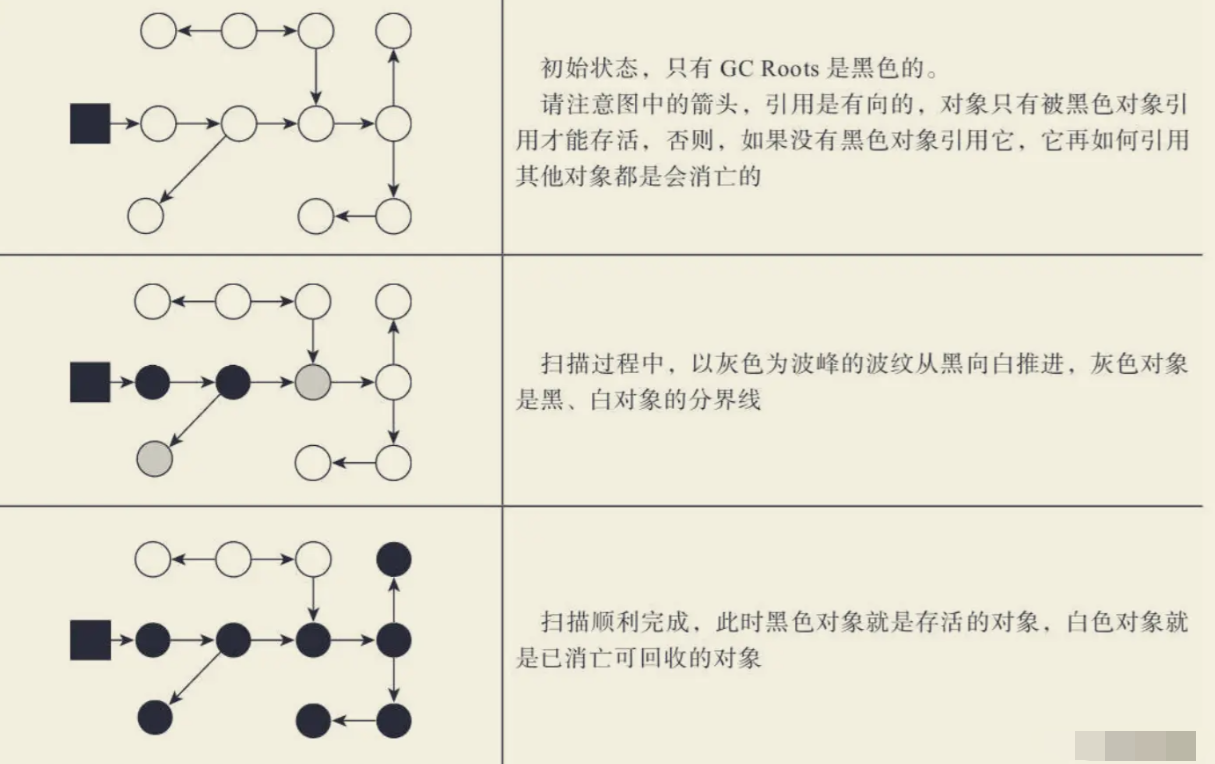
在初始阶段的时候,所有的对象都是存放在白色容器中。
初始标记阶段,
GCRoot标记直接关联对象置为灰色。并发标记阶段,扫描整个引用链,有子节点的话,则当前节点变为黑色,子节点变为灰色。
在白色盒子剩下的对象都是为没有被
GCRoot关联的对象,可能会被垃圾回收机制清理。下次
GCRoot起点从灰色节点开始计算。
三色标记算法缺陷:
在并发标记阶段的时候,因为用户线程与GC线程同时运行,有可能会产生多标或者漏标。
多标:
- 在并发标记阶段,把一个
GC Roots引用链上的对象已经标记了
- 但是用户线程没有停止,当方法结束的时候,这个对象链上可能都是垃圾对象,称为浮动垃圾。
漏标:
- 在并发标记阶段,原先已经被扫描过的对象重新有了新的引用,导致无法被扫描。
CMS解决漏标问题:增量更新方式:
当黑色对象插入新的指向白色对象的引用关系的时候,就将这个新插入的引用记录下来
等并发标记结束之后,等到重新标记阶段,会
stop the world
- 再将这些记录过的引用关系中的黑色对象为根,重新扫描一次。
G1如何解决漏标问题:原始快照STAB方式:
当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用关系记录下来
在并发标记结束之后,等到重新标记阶段
- 会
stop the world再讲这些记录过的引用关系中的灰色对象为根,重新扫描一次这样就能扫描到白色对象,将这些白色对象标记成黑色对象
- 目的就是让这种对象在本次GC中存下来,等待下一轮GC的时候重新扫描,这个对象也有可能是浮动垃圾。
增量更新针对的是新增,原始快照针对的是删除。
无论是插入和删除,JVM的记录操作都是通过写屏障实现的,STAB是写前屏障,增量更新是写后屏障。
跨代引用
跨代引用是指年老代空间中的对象引用了新生代的对象,或者新生代中的对象引用了年老代中的对象。
面对这种情况,在进行可达性分析扫描存活对象时,不可能从新生代一直扫描至年老代的,因为这样就会出现整堆扫描的情况,效率必然会很低。
在HotSpot虚拟机中,为了解决跨代引用的问题,会专门在内存中开辟一块小空间用于维护这些特殊的引用,从而达到让GC不必扫描整个堆空间的目的,而开辟的这块小空间则被称为记忆集、卡表。
记忆集(Remember Set):
为了解决跨代引用的问题,在新生代引入了记录集的数据结构,记录从非收集区到收集区的引用指针集合,避免在通过根可达算法判断对象存活时把整个老年代加入扫描范围。
GC时,GC收集器只需通过记忆集判断出某一块非收集区域是否存在指向收集区域的指针即可,无需进行详细的根搜索过程。
卡表(Card Table):
卡表是HotSpot虚拟机中记忆集的实现方式,卡表中记录中记忆集的记录精度、与堆内存区域的映射关系等。
如果有年老代的对象引用了新生代的对象,那么该新生代对象所在区域对应的卡页元素设置为1,反之则为0。
G1以后的GC收集器不分代,所以G1以后的记忆集不是通过数组实现的,而是通过哈希表结构实现。
- JVM对于卡页的维护也是通过写屏障的方式。
Remembered Set:
G1中实现的一种新的数据结构:简称为
RSet,也被称为双向卡表。在每个
Region区中都存在一个RSet,其中记录了其他Region中的对象引用当前Region中对象的关系,也就是记录着谁引用了我的对象,属于points-into结构。之前的卡表则是属于
points-out结构,记录着我引用了谁的对象,在卡表中存在多个卡页,每个卡页记录着一定范围(512KB)的堆。
RSet也好,CardTable也好,都是记忆集的一种具体实现,你也可以将RSet理解成一种CardTable的进阶实现方式。G1中的
RSet本质上就是一个哈希表结构(HashTable),Key为其他引用当前区内对象的Region起始地址,Value则是一个集合,里面的元素为其他Region中每个引用当前区内对象的地址。实际上G1中的
RSet对内存的开销也并不小,当JVM中分区较多且运行时间较长的情况下,这块的内存开销可能会占用到20%以上。
















{kind=link}