Java内存模型!
Java内存模型!
月伴飞鱼JMM抽象结构划分为线程本地缓存与主存,每个线程均有自己的本地缓存,本地缓存是线程私有的,主存则是计算机内存,它是共享的。
为什么需要 JMM(Java Memory Model,Java 内存模型)
程序最终执行的效果会依赖于具体的处理器,而不同的处理器的规则又不一样,不同的处理器之间可能差异很大。
因此同样的一段代码,可能在处理器 A 上运行正常,而在处理器 B 上运行的结果却不一致。
- 在没有 JMM 之前,不同的 JVM 的实现,也会带来不一样的 翻译 结果。
如果达成一致后,就可以很清楚的知道什么样的代码最终可以达到什么样的运行效果,让多线程运行结果可以预期。
主内存和工作内存的关系
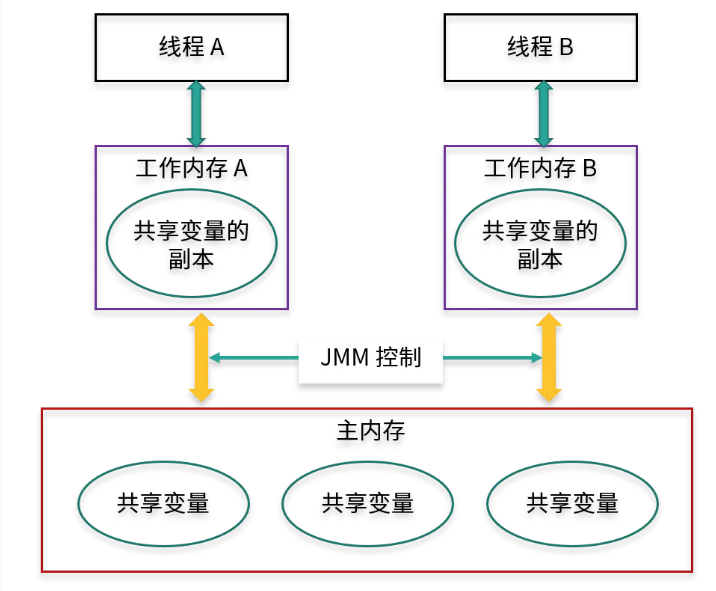
JMM 有以下规定:
所有的变量都存储在主内存中,同时每个线程拥有自己独立的工作内存,而工作内存中的变量的内容是主内存中该变量的拷贝。
线程不能直接读/写主内存中的变量,但可以操作自己工作内存中的变量,然后再同步到主内存中。
- 这样,其他线程就可以看到本次修改。
主内存是由多个线程所共享的,但线程间不共享各自的工作内存,如果线程间需要通信,则必须借助主内存中转来完成。
可见性
当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。
能够保证可见性的措施:
volatile 关键字。
synchronized、Lock、并发集合等一系列工具。
原子性
原子性是指一个或者多个操作在CPU执行的过程中不被中断的特性,要么执行,要不执行,不能执行到一半。
比如 i++ 这一行代码在 CPU 中执行时,可能会从一行代码变为以下的 3 个指令:
第一个步骤是读取。
第二个步骤是增加。
第三个步骤是保存。
所以 i++ 是不具备原子性的,也不是线程安全的。
有序性
有序性指禁止指令重排序,即保证程序执行代码的顺序与编写程序的顺序一致(程序执行顺序按照代码的先后顺序执行)。
重排序的3种情况:
编译器优化:
- 编译器(包括 JVM、JIT 编译器等)出于优化的目的,例如当前有了数据 a,把对 a 的操作放到一起效率会更高。
- 避免读取 b 后又返回来重新读取 a 的时间开销,此时在编译的过程中会进行一定程度的重排。
CPU重排序:
- CPU 同样会有优化行为,这里的优化和编译器优化类似,都是通过乱序执行的技术来提高整体的执行效率。
内存的重排序:
- 由于内存有缓存的存在,在 JMM 里表现为主存和本地内存,而主存和本地内存的内容可能不一致。
- 所以这也会导致程序表现出乱序的行为。
重排需要遵循as-if-serial原则,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。
重排序的好处:提高处理速度。
1 | int i = 10 |
Happens Before规则
Happens Before关系是用来描述和可见性相关问题的:
如果第一个操作 happens before 第二个操作,那么我们就说第一个操作对于第二个操作一定是可见的。
也就是第二个操作在执行时就一定能保证看见第一个操作执行的结果。
不具备 happens before 关系的例子:
如果有两个线程,分别执行 write 和 read 方法,那么由于这两个线程之间没有相互配合的机制。
所以 write 和 read 方法内的代码不具备 happens-before 关系,其中的变量的可见性无法保证。
1 | public class Visibility { |
单线程规则:
- 在一个单独的线程中,按照程序代码的顺序,先执行的操作 happen before 后执行的操作。
volatile 变量规则:
- 对一个 volatile 变量的写操作 happen before 后面对该变量的读操作。
线程启动规则:
- Thread 对象的 start 方法 happen before 此线程 run 方法中的每一个操作。















{kind=link}