MySQL索引机制!
MySQL索引机制!
月伴飞鱼索引分类
单列索引:基于单个字段建立的索引。
唯一索引:
- 指索引中的索引节点值不允许重复,一般配合唯一约束使用。
主键索引:
- 一种特殊的唯一索引,和普通唯一索引的区别在于不允许有空值。
普通索引:
- 通过
KEY、INDEX关键字创建的索引。
多列索引:由多个字段组合建立的索引。
聚簇索引和非聚簇索引:
聚簇索引(主键索引):
- 叶子节点存放的是实际数据,所有完整的用户数据都存放在聚簇索引的叶子节点。
非聚簇索引(二级索引):
- 叶子节点存放的是主键值,而不是实际数据。
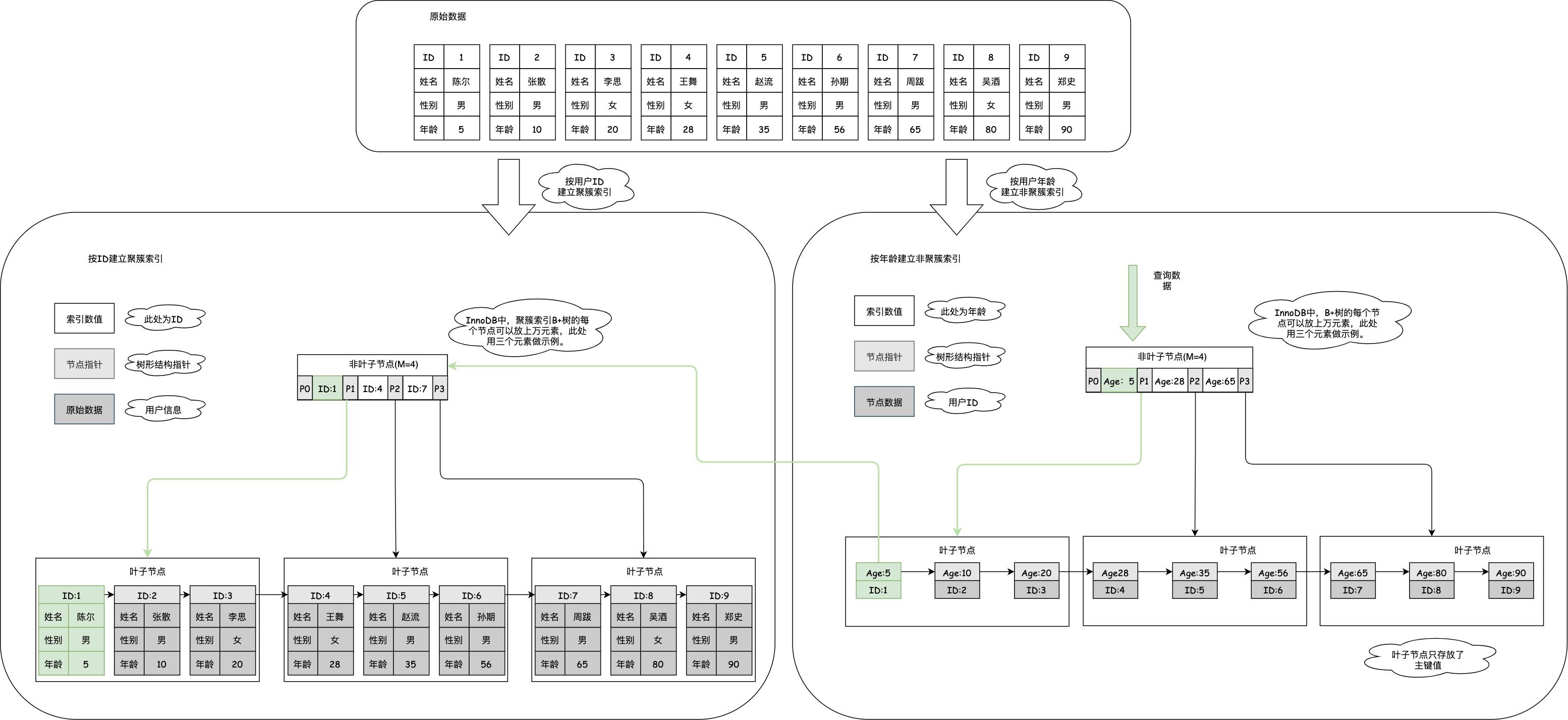
二级索引:
使用 二级索引 字段作为条件查询的时候,如果要查询的数据都在 聚簇索引 的叶子节点里,需要检索两颗B+树:
- 先在 二级索引 的 B+ 树找到对应的叶子节点,获取主键值。
- 然后用上一步获取的主键值,在 聚簇索引 中的 B+ 树检索到对应的叶子节点,然后获取要查询的数据。
这个过程叫做回表。
全文索引:
类似于
ES、Solr搜索中间件中的分词器。只能创建在
CHAR、VARCHAR、TEXT等这些文本类型字段上,而且使用全文索引查询时,条件字符数量必须大于3才生效。
哪些情况下适合建索引
作为where条件语句查询的字段。
关联字段需要建立索引。
排序字段可以建立索引。
分组字段可以建立索引。
统计字段可以建立索引,如
count(),max()。
哪些情况下不适合建索引
频繁更新的字段不适合建立索引。
where条件中用不到的字段不适合建立索引。
表数据比较少的不需要建索引。
数据重复且发布比较均匀的的字段不适合建索引。
参与列计算的列不适合建索引。
索引覆盖
要查询的列,在使用的索引中已经包含,这种情况称之为索引覆盖。
索引区分度
索引的区分度等于:
count(distinct 具体的列)/count(*),表示字段不重复的比例。唯一键的区分度是1,而对于一些状态值,性别等字段区分度往往比较低,在数据量比较大的情况下,甚至有无限接近0。
索引结构
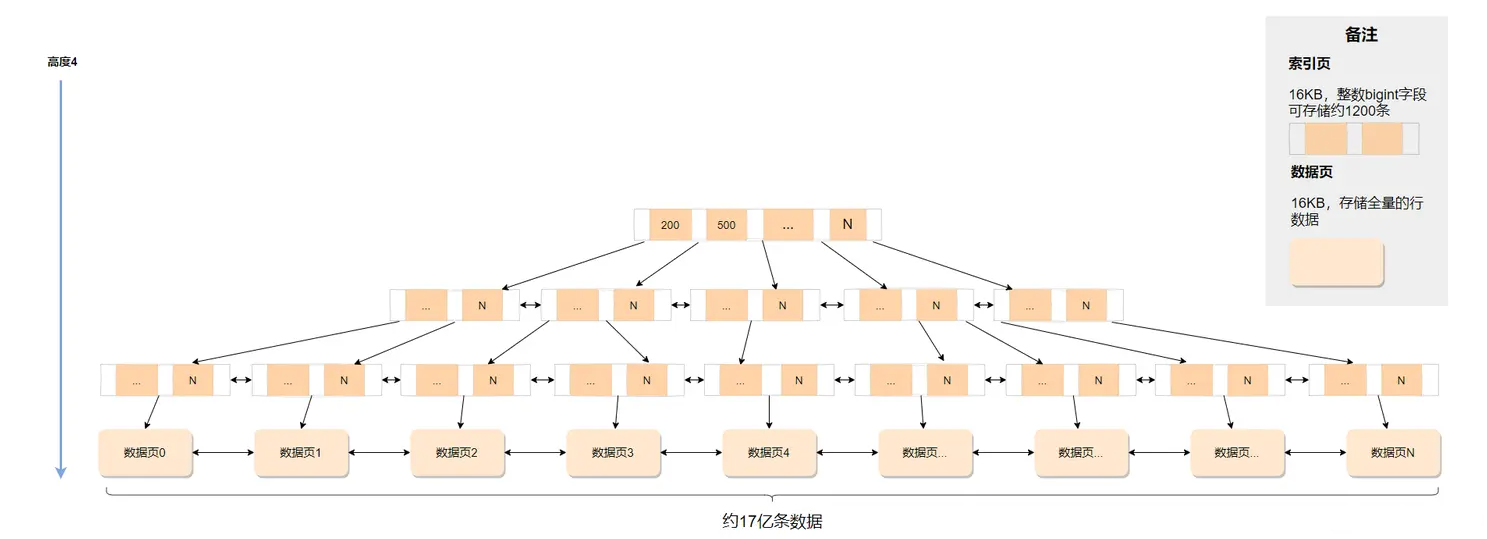
InnoDB中使用了B+树来实现索引。
- 所谓的索引就是一颗 B+ 树,一个表有多少个索引就会有多少颗 B+ 树。
InnoDB的整数字段建立索引为例:
- 一个页默认
16kb,整数(bigint)字段的长度为8B,另外还跟着6B的指向其子树的指针,这意味着一个索引页可以存储接近1200条数据(16kb/14B ≈ 1170)。- 如果这颗B+树高度为
4,就可以存1200的3次方的值,差不多17亿条数据。考虑到树根节点总是在内存中的,树的第二层很大概率也在内存中,所以一次搜索最多只需要访问
2次磁盘IO。假设
1亿数据量的表,根据主键id建立了B+树索引,搜索id=2699的数据,流程如下:
- 内存中直接获取树根索引页,对树根索引页内的目录进行二分查找,定位到第二层的索引页。
- 内存中直接获取第二层的索引页,对索引页内的目录进行二分查找,定位到第三层的索引页。
- 从磁盘加载第三层的索引页到内存中,对索引页内的目录进行二分查找,定位到第四层数据页。
- 从磁盘加载第四层的数据页到内存中,数据页变成缓存页,对缓存页中的目录进行二分查找,定位到具体的行数据。
B+树
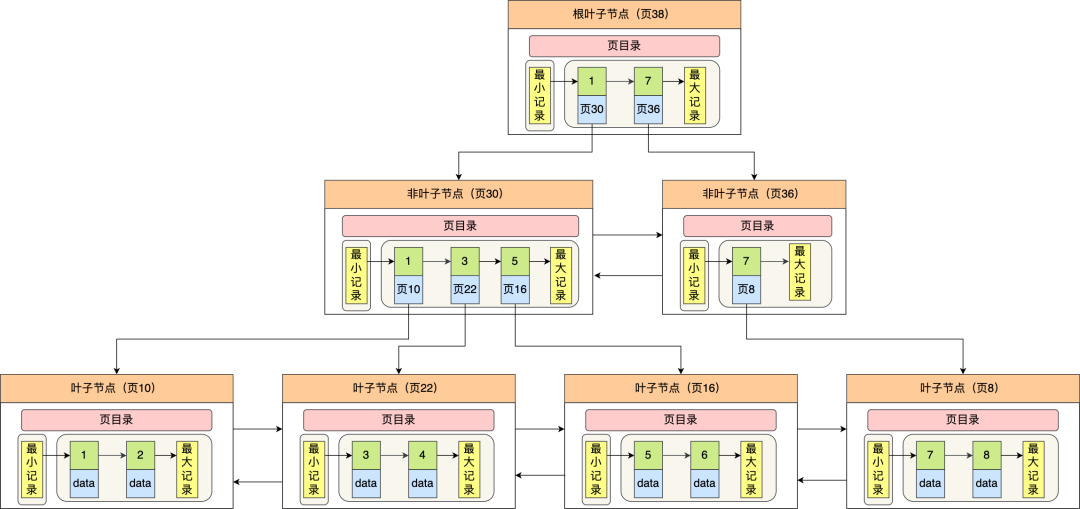
B+ 树与 B 树差异点:
叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引。
所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表。
- Innodb 的 B+ 树的叶子节点之间是用 双向链表 进行连接,既能向右遍历,也能向左遍历。
非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
非叶子节点中有多少个子节点,就有多少个索引。
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引。
- 因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引。
因此 B+ 树可以比 B 树更 矮胖 ,查询底层节点的磁盘 I/O次数会更少。
MyISAM 存储引擎:
- B+ 树索引的叶子节点保存数据的物理地址,即用户数据的指针。
InnoDB 存储引擎:
- B+ 树索引的叶子节点保存数据本身。
为什么使用B+树而不使用跳表?
B+树 是多叉树结构,每个结点都是一个16k的数据页,能存放较多索引信息。
- 三层左右可以存储
2kw左右的数据,查询一次数据,如果这些数据页都在磁盘里,最多需要查询三次磁盘IO。跳表是链表结构,一条数据一个结点,如果最底层要存放
2kw数据,且每次查询都要能达到二分查找的效果。
2kw大概在2的24次方左右,所以,跳表大概高度在24层左右。最坏情况下,这24层数据会分散在不同的数据页里,也即是查一次数据会经历24次磁盘IO。
针对写操作,B+树需要拆分合并索引数据页,跳表则独立插入,并根据随机函数确定层数,没有旋转和维持平衡的开销。
因此跳表的写入性能会比B+树要好。
为什么Redis有序集合底层选择跳表而非B+树
Redis是基于内存的数据库,因此不需要考虑磁盘IO。
- B+树在数据写入时,存在拆分和合并数据页的开销,目的是为了保持树的平衡。
- 跳表在数据写入时,只需要通过随机函数生成当前节点的层数即可,然后更新每一层索引,往其中加入一个节点。
- 相比于B+树而言,少了旋转平衡带来的开销。
由于跳表的查询复杂度在O
(logn),因此Redis中Zset数据类型底层结合使用skiplist和hash,用空间换时间。利用跳表支持范围查询和有序查询,利用Hash支持精确查询。
为什么建议使用自增ID作为主键
MySQL 在底层以数据页为单位来存储数据的,一个数据页大小默认为 16k。
也就是说如果一个数据页存满了,MySQL 就会去申请一个新的数据页来存储数据。
- 如果主键为自增 ID 的话,MySQL 在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。
- 如果主键是非自增 ID,为了确保索引有序,MySQL 就需要将每次插入的数据都放到合适的位置上。
当往一个快满或已满的数据页中插入数据时,新插入的数据会将数据页写满,MySQL 就需要申请新的数据页。
并且把上个数据页中的部分数据挪到新的数据页上。这就造成了页分裂,这个大量移动数据的过程是会严重影响插入效率的。
索引下推ICP(Index Condition Pushdown)
一张
user表,有age_name的联合索引。执行查询
explain SELECT * from user where age >10 and name = 'a'。
- 看见
Extra中显示了Using index condition,表示出现了索引下推。ICP流程:
- 联合索引首先通过条件找到所有
age>10的数据,根据联合索引中已经存在的name数据进行过滤,找到符合条件的数据。
索引合并
在MySQL 5.1之后进行引入,它可以在多个索引上进行查询,并将结果合并返回。
索引失效
1、不满足最左匹配原则
2、索引列上有计算
1 | explain select * from 某表 where id+1=2; |
3、索引列用了函数
1 | explain select * from 某表 where SUBSTR(height,1,2)=17; |
4、字段类型不同
5、like左边包含%
6、列对比
id字段本身是有主键索引的,同时height字段也建了普通索引的,并且两个字段都是int类型,类型是一样的
如果把两个单独建了索引的列,用来做列对比时索引就会失效
1 | explain select * from user where id=height |
7、使用or关键字
因为最后加的address字段没有加索引,从而导致其他字段的索引都失效了
如果使用了
or关键字,那么它前面和后面的字段都要加索引,不然所有的索引都会失效
1 | explain select * from user where id=1 or height='175' or address='成都'; |
8、not in和not exists
主键字段中使用
not in关键字查询数据范围,可以走索引而普通索引字段使用了
not in关键字查询数据范围,索引会失效
9、order by 没加where或limit
如果order by语句中没有加where或limit关键字,该sql语句将不会走索引
1 | explain select * from user order by code, name; |
10、对不同的索引做order by
1 | explain select * from user order by code, height limit 100; |
CBO
CBO(Cost-Based Optimizer,基于成本的优化器)。
优化器的选择是基于成本(cost),哪个索引的成本越低,优先使用哪个索引。
一条 SQL 的计算成本计算如下:
1 | Cost = Server Cost + Engine Cost |
CPU Cost:
- 表示计算的开销,比如索引键值的比较、记录值的比较、结果集的排序……这些操作都在 Server 层完成。
IO Cost:
- 计算读取内存 IO 开销以及读取磁盘 IO 的开销。
















{kind=link}