Redis常见问题!
Redis常见问题!
月伴飞鱼热Key
热 Key 带来问题:
流量集中,达到服务器处理上限(
CPU、网络IO等)。会影响在同一个
Redis实例上其他Key的读写请求操作。热
Key请求落到同一个Redis实例上,无法通过扩容解决。大量
Redis请求失败,查询操作可能打到数据库,拖垮数据库,导致整个服务不可用。
如何发现热 Key:
客户端进行收集:
- 可以对客户端工具进行封装,在发送请求前进行收集采集,同时定时把收集到的数据上报到统一的服务进行聚合计算。
在代理层进行收集:
- 如果所有的
Redis请求都经过Proxy(代理)的话,可以考虑改动Proxy代码进行收集。
热 Key 问题解决方案:
增加 Redis 实例副本数量:
- 对于出现热
Key的Redis实例,可以通过水平扩容增加副本数量,将读请求的压力分担到不同副本节点上。二级缓存(本地缓存)
热 Key 备份:
通过热
Key备份的方式,给热Key加上前缀或者后缀
- 把一个热
Key的数量变成Redis实例个数N的倍数M
- 从而由访问一个
RedisKey变成访问N*M个RedisKey。
N*M个RedisKey经过分片分布到不同的实例上,将访问量均摊到所有实例。
1 | // N 为 Redis 实例个数,M 为 N 的 2倍 |
通过一个大于等于
1小于M的随机数,得到一个bakHotKey
- 程序会优先访问
bakHotKey,在得不到数据的情况下
- 再访问原来的
hotkey,并将hotkey的内容写回bakHotKey。
bakHotKey的过期时间是hotkey的过期时间加上一个较小的随机正整数
- 保证在
hotkey过期时,所有bakHotKey不会同时过期而造成缓存雪崩。
大key
如果String类型值大于10KB,
Hash,Set,Zset,List类型的元素的个数大于5000个都可以称之为大Key。
大Key的危害:
客户端超时等待
阻塞工作线程
内存分布不均匀:
- 集群模型在Slot分片均匀的情况下,会出现数据和查询倾斜情况,部分有大Key的Redis节点占用内存多。
如何处理大Key:
对大Key进行拆分:
- 将一个Big Key拆分为多个
Key-Value这样的小Key,并确保每个Key的成员数量或者大小在合理范围内。- 通过Get不同的key或者使用MGet批量获取。
删除BigKey:
Redis官方文档描述到:
- String 类型的key,DEL 时间复杂度是
O(1),大Key除外。List/Hash/Set/ZSet类型的Key,DEL 时间复杂度是O(M),M 为元素数量,元素越多,耗时越久。
异步删除:
Redis从4.0开始,可以使用
UNLINK命令来异步删除大Key,删除大Key的语法与DEL命令相同。
- 当使用UNLINK删除一个大Key时,Redis不会立即释放关联的内存空间,而是将删除操作放入后台处理队列中。
Redis会在处理命令的间隙,逐步执行后台队列中的删除操作,从而不会显著影响服务器的响应性能。
缓存一致性
| 方案 | 问题 | 问题出现概率 | 推荐程度 |
|---|---|---|---|
| 更新缓存 -> 更新数据库 | 为了保证数据准确性,数据必须以数据库更新结果为准,所以该方案绝不可行 | 大 | 不推荐 |
| 更新数据库 -> 更新缓存 | 并发更新数据库场景下,会将脏数据刷到缓存 | 并发写场景,概率一般 | 写请求较多时会出现不一致问题,不推荐使用。 |
| 删除缓存 -> 更新数据库 | 更新数据库之前,若有查询请求,会将脏数据刷到缓存 | 并发读场景,概率较大 | 读请求较多时会出现不一致问题,不推荐使用 |
| 更新数据库 -> 删除缓存 | 在更新数据库之前有查询请求,并且缓存失效了,会查询数据库,然后更新缓存。 如果在查询数据库和更新缓存之间进行了数据库更新的操作,那么就会把脏数据刷到缓存。 |
并发读场景&读操作慢于写操作,概率最小 | 读操作比写操作更慢的情况较少,相比于其他方式出错的概率小一些。勉强推荐。 |
操作失败情况处理:
对数据库和缓存的操作,在实际生产中,由于网络抖动、服务下线等等原因,操作是有可能失败的。
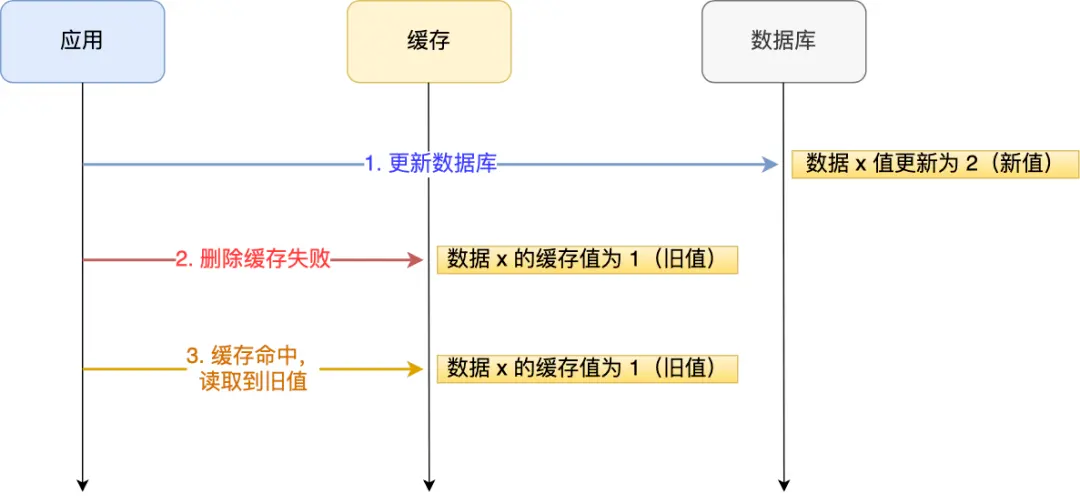
举例说明:
应用要把数据 X 的值从 1 更新为 2,先成功更新了数据库,然后在
Redis缓存中删除 X 的缓存。但是这个操作失败了,这个时候数据库中 X 的新值为 2,
Redis中的 X 的缓存值为 1,出现了数据库和缓存数据不一致的问题。
- 不管是先操作数据库,还是先操作缓存,只要第二个操作失败都会出现数据一致的问题。
解决方法:
重试机制:
- 如果重试超过一定次数,还是没有成功,就需要向业务层发送报错信息了。
订阅
MySQL Binlog,再操作缓存。
缓存击穿
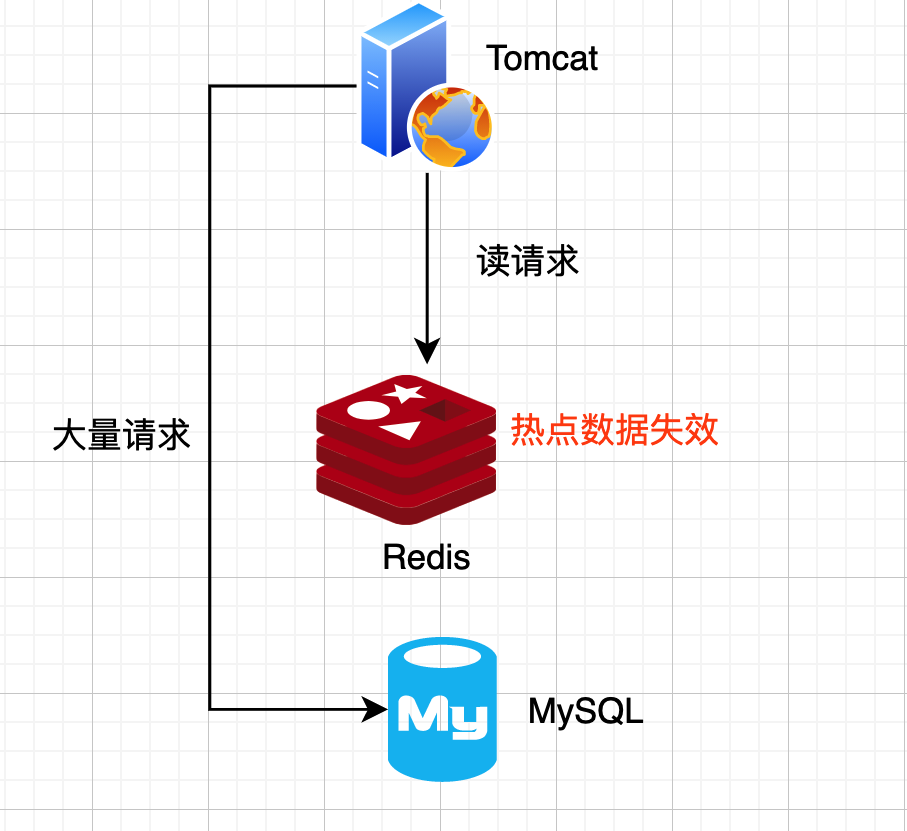
解决方案:
使用互斥锁。
提前使用互斥锁:
- 即在value内部设置1个超时值(timeout1),timeout1比实际的redis timeout(timeout2)小。
- 当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。
- 然后再从数据库加载数据并设置到cache中。
缓存永不过期。
缓存穿透
查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询。
在流量大时,要是DB无法承受瞬间流量冲击,DB可能就挂了。
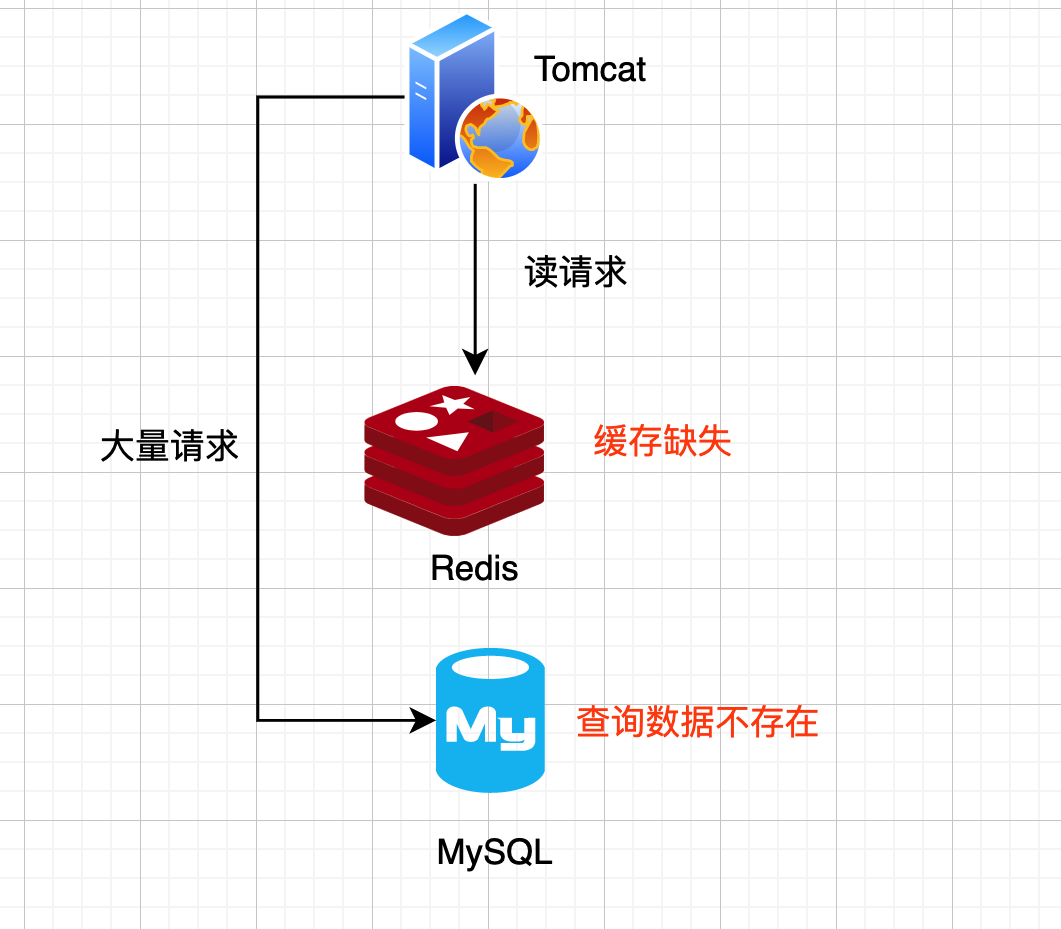
解决方案:
缓存空数据。
布隆过滤器。
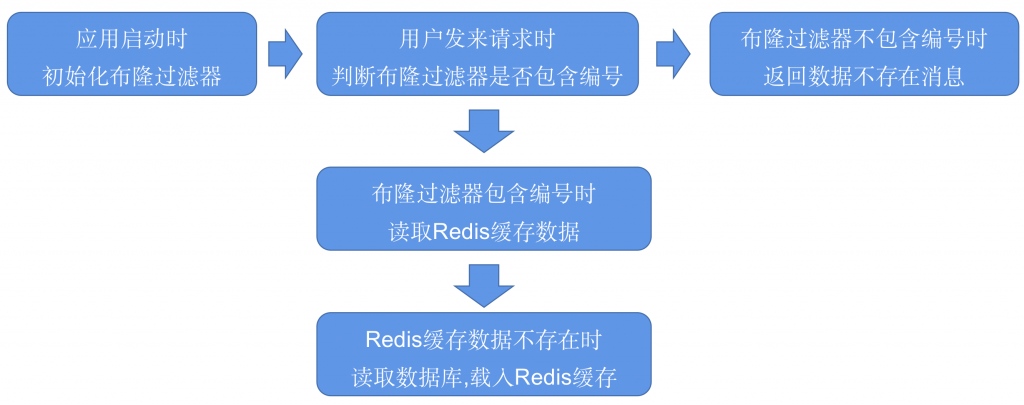
缓存雪崩
缓存中有大量数据同时过期,导致大量请求无法得到处理。
解决方案:
设计不同的过期时间。
对缓存增加多个副本。

















{kind=link}