Redis数据结构!
Redis数据结构!
月伴飞鱼一个单机的 Redis 服务器默认情况下有 16 个数据库(0-15 号)。
- 默认使用的是 0 号数据库,可以使用
SELECT命令切换数据库。
每个数据库都由一个
redis.h/redisDb结构表示:
- 它记录了单个 Redis 数据库的键空间、所有键的过期时间、处于阻塞状态和就绪状态的键、数据库编号等。
dict:
- 一个记录键值对数据的字典。
- 键是一个字符串对象,值是字符串、列表、哈希表、集合和有序集合在内的任意一种 Redis 类型对象。
expires:
- 一个用于记录键的过期时间的字典。
- 键为 dict 中的数据库键,值为这个数据库键的过期时间戳,这个值以 long long 类型表示。
1 | typedef struct redisDb { |
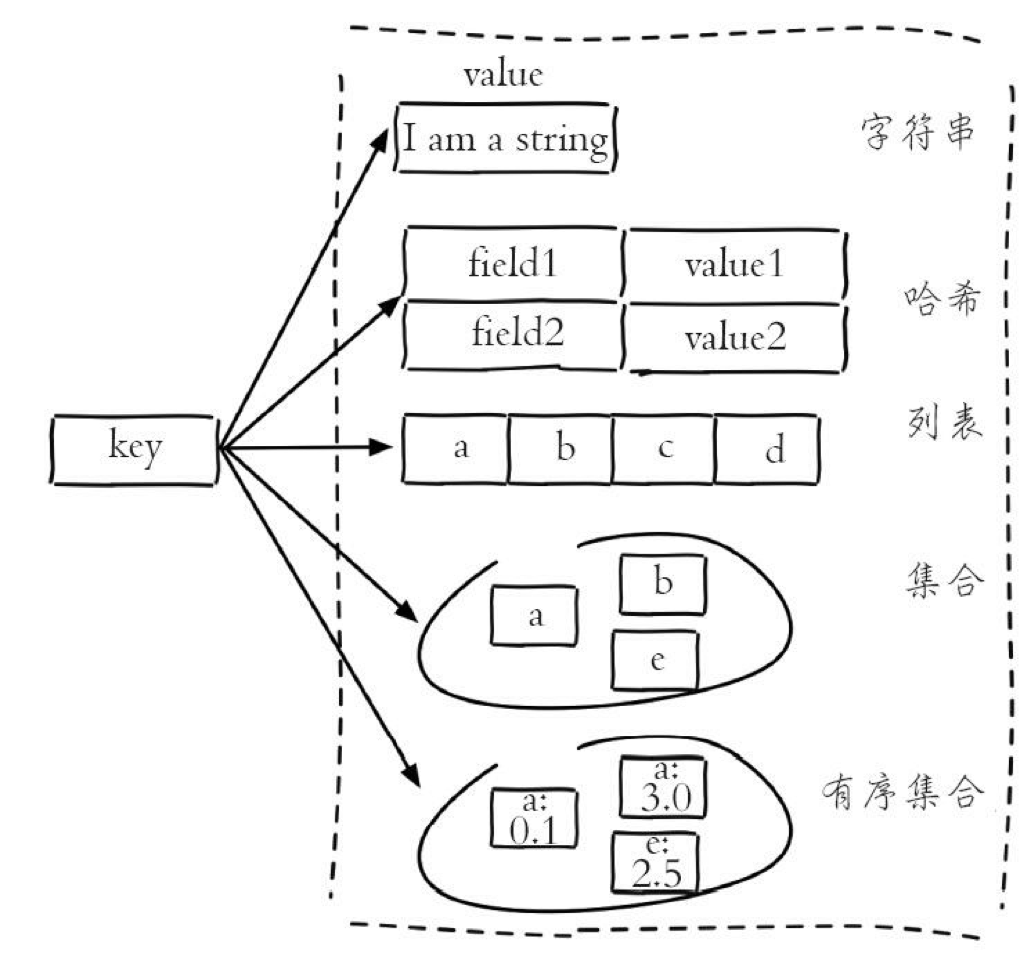
数据类型
string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)
String
它可以存储任意类型的数据,比如文本、数字、图片或者序列化的对象。
一个 string 类型的键最大可以存储 512 MB 的数据。
string 类型的底层实现是 SDS,它是一个动态字符串结构,由长度、空闲空间和字节数组三部分组成。
SDS有3种编码类型:
- embstr:占用64Bytes的空间,存储44Bytes的数据
- raw:存储大于44Bytes的数据
- int:存储整数类型
embstr和raw存储字符串数据,int存储整型数据。
应用场景:
- 缓存数据,提高访问速度和降低数据库压力。
- 计数器,利用 incr 和 decr 命令实现原子性的加减操作。
- 分布式锁,利用 setnx 命令实现互斥访问。
- 限流,利用 expire 命令实现时间窗口内的访问控制。
List
一个有序的字符串列表,它按照插入顺序排序,并且支持在两端插入或删除元素。
一个 list 类型的键最多可以存储
2^32 - 1个元素。
redis3.2以后,list 类型的底层实现只有一种结构:quicklist。应用场景:
- 消息队列,利用 lpush 和 rpop 命令实现生产者消费者模式。
- 最新消息,利用 lpush 和 ltrim 命令实现固定长度的时间线。
- 历史记录,利用 lpush 和 lrange 命令实现浏览记录或者搜索记录。
Hash
一个键值对集合,它可以存储多个字段和值,类似于编程语言中的 map 对象。
一个 hash 类型的键最多可以存储
2^32 - 1个字段。Hash类型的底层实现有三种:
ziplist:压缩列表,当hash达到一定的阈值时,会自动转换为hashtable结构。listpack:紧凑列表,在Redis7.0之后,listpack正式取代ziplist。
- 同样的,当hash达到一定的阈值时,会自动转换为
hashtable结构。hashtable:哈希表,类似map。应用场景:
hash 类型的应用场景主要是存储对象,比如:
- 用户信息,利用 hset 和 hget 命令实现对象属性的增删改查。
- 购物车,利用 hincrby 命令实现商品数量的增减。
- 配置信息,利用 hmset 和 hmget 命令实现批量设置和获取配置项。
Set
set是一个无序的字符串集合,它不允许重复的元素。一个
set类型的键最多可以存储2^32 - 1个元素。
set类型的底层实现有两种:
intset,整数集合。hashtable(哈希表)。
- 哈希表和 hash 类型的哈希表相同,它将元素存储在一个数组中,并通过哈希函数计算元素在数组中的索引。
应用场景:
- 去重,利用 sadd 和 scard 命令实现元素的添加和计数。
- 交集,并集,差集,利用 sinter,sunion 和 sdiff 命令实现集合间的运算。
- 随机抽取,利用 srandmember 命令实现随机抽奖或者抽样。
ZSet
Redis中的zset是一种有序集合类型,它可以存储不重复的字符串元素,并且给每个元素赋予一个排序权重值(score)。
Redis通过权重值来为集合中的元素进行从小到大的排序。
zset的成员是唯一的,但权重值可以重复。一个
zset类型的键最多可以存储2^32 - 1个元素。应用场景:
- 排行榜,利用 zadd 和 zrange 命令实现分数的更新和排名的查询。
- 延时队列,利用 zadd 和 zpopmin 命令实现任务的添加和执行,并且可以定期地获取已经到期的任务。
- 访问统计,可以使用 zset 来存储网站或者文章的访问次数,并且可以按照访问量进行排序和筛选。
GEO
Redis的Geo在Redis 3.2版本推出,这个功能可以推算地理位置的信息: 两地之间的距离,方圆几里的人。
查询键的数据类型
type key:
例如键
hello字符串类型,返回:string。键
mylist列表类型,返回:list。如果键不存在,则返回
none。
1 | 127.0.0.1:6379> set a b |
内部编码
对于每种 数据类型,实际上都有自己底层的 内部编码 实现,而且是 多种实现。
这样
Redis会在合适的 场景 选择合适的 内部编码。
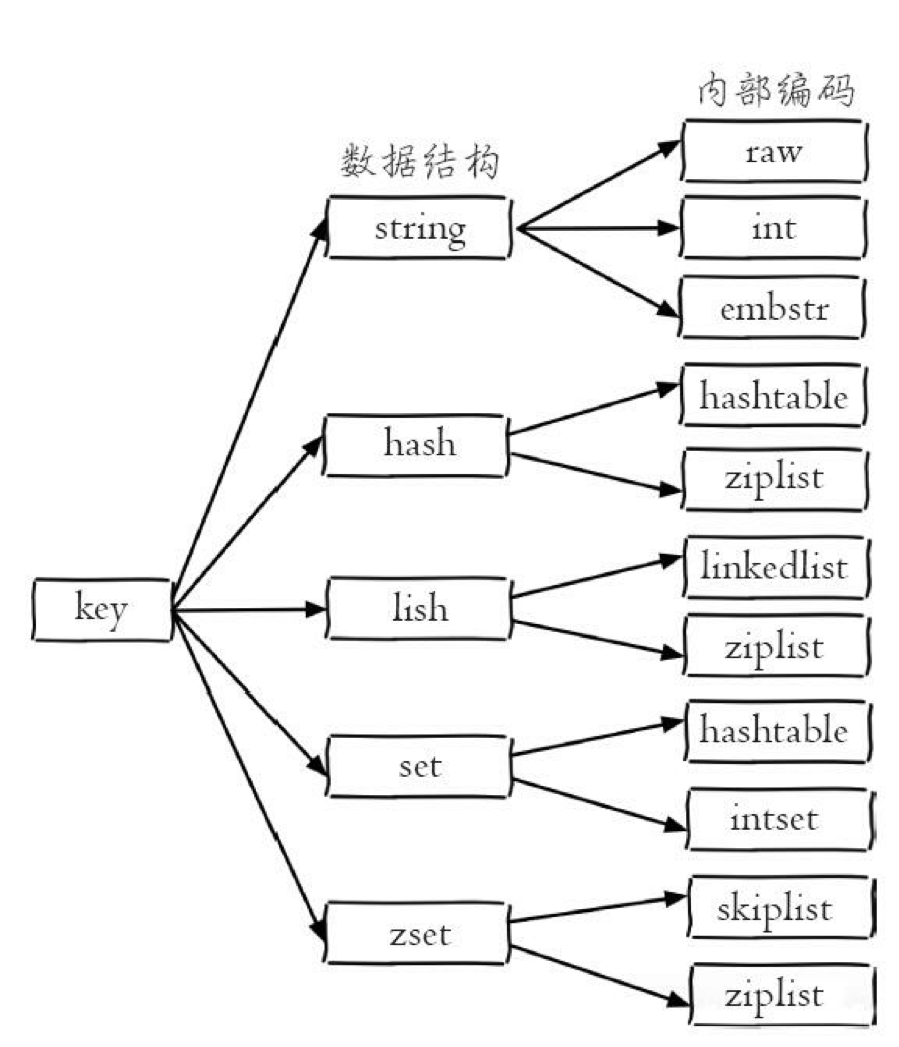
通过 object encoding 命令查询 内部编码:
1 | 127.0.0.1:6379> object encoding hello |
Hash底层原理
哈希类型 的 内部编码:
- ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)
- hashTable
ziplist(压缩列表):
- 当 哈希类型 元素个数 小于
hash-max-ziplist-entries配置,同时 所有值 都 小于hash-max-ziplist-value配置时使用。ziplist使用更加 紧凑的结构 实现多个元素的 连续存储,在 节省内存 方面比hashtable更加优秀。hashtable(哈希表):
- 当 哈希类型 无法满足
ziplist的条件时,Redis会使用hashtable作为 哈希 的 内部实现。- 因为此时
ziplist的 读写效率 会下降,而hashtable的读写 时间复杂度 为O(1)。
List底层原理
列表类型的 内部编码:
- 在
Redis3.2之前,list使用的是linkedlist和ziplist- 在
Redis3.2~Redis7.0之间,list使用的是quickList,是linkedlist和ziplist的结合- 在
Redis7.0之后,list使用的也是quickList,只不过将ziplist转为listpack,它是listpack、linkedlist结合版ziplist(压缩列表):
- 当列表的元素个数 小于
list-max-ziplist-entries配置。- 同时列表中 每个元素 的值都 小于
list-max-ziplist-value配置时使用。linkedlist(链表):
- 当 列表类型 无法满足
ziplist的条件时,Redis会使用linkedlist作为 列表 的 内部实现。
Set底层原理
集合类型 的 内部编码:
- 在
Redis7.2之前,set使用的是intset和hashtable- 在
Redis7.2之后,set使用的是intset、listpack、hashtableintset(整数集合):
- 当集合中的元素都是 整数 且 元素个数 小于
set-max-intset-entries配置时使用。hashtable(哈希表):
- 当集合类型 无法满足
intset的条件时,Redis会使用hashtable作为集合的 内部实现。
为什么加入了listpack?
在
redis7.2之前,sds类型的数据会直接放入到编码结构式为hashtable的set中。
- 其中,
sds其实就是redis中的string类型。而在
redis7.2之后,sds类型的数据,首先会使用listpack结构,当set达到一定的阈值时,才会自动转换为hashtable。添加
listpack结构是为了提高内存利用率和操作效率,因为 hashtable 的空间开销和碰撞概率都比较高。
ZSet底层原理
有序集合的内部实现:
ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)skiplist当有序集合的元素个数小于
zset-max-ziplist-entries(默认为128个)。并且每个元素成员的长度小于
zset-max-ziplist-value(默认为64字节)时,使用压缩列表作为有序集合的内部实现。
- 每个集合元素由两个紧挨在一起的两个压缩列表结点组成,其中第一个结点保存元素的成员,第二个结点保存元素的分支。
- 压缩列表中的元素按照分数从小到大依次紧挨着排列,有效减少了内存空间的使用。
当有序集合的元素个数大于等于
zset-max-ziplist-entries(默认为128个)。或者每个元素成员的长度大于等于
zset-max-ziplist-value(默认为64字节)时,使用跳跃表作为有序集合的内部实现。
- 在跳跃表中,所有元素按照从小到大的顺序排列。
- 跳跃表的结点中的
object指针指向元素成员的字符串对象,score保存了元素的分数。- 通过跳跃表,Redis可以快速地对有序集合进行分数范围、排名等操作。
在哈希表中,为有序集合创建了一个从元素成员到元素分数的映射。
键值对中的键指向元素成员的字符串对象,键值对中的值保存了元素的分数。
- 通过哈希表,Redis可以快速查找指定元素的分数。
虽然有序集合同时使用跳跃表和哈希表,但是这两种数据结构都使用指针共享元素中的成员和分数,不会额外的内存浪费。
Pipeline
通过将一批命令进行打包,然后发送给服务器,服务器执行完按顺序打包返回,这样就减少了频繁交互往返的时间,提升了性能。
- 客户端将执行的命令写入到缓冲区(内存)中,最后再一次性发送 Redis。
Pipeline的优点:
通过打包命令,一次性执行,可以节省连接->发送命令->返回结果这个过程所产生的往返时间,减少的I/O的调用(用户态到内核态之间的切换)次数。
Pipeline的缺点:
每批打包的命令不能过多,因为所有命令前先缓存起所有命令的处理结果,这样就有一个内存的消耗。
不保证原子性,执行命令过程中,如果一个命令出现异常,也会继续执行其他命令。
每次只能作用在一个Redis节点上。

















{kind=link}