XXLJOB基本原理!
XXLJOB基本原理!
月伴飞鱼系统架构
XXL-JOB有2个角色:
xxl-job-admin调度中心:
- 统一管理任务调度平台上的调度任务,负责触发调度执行,并且提供任务管理平台。
xxl-job-executor执行器:
- 执行器通常是业务系统,如
springboot项目。
设计思想
将调度行为抽象形成 调度中心 公共平台,而平台自身并不承担业务逻辑,调度中心 负责发起调度请求。
将任务抽象成分散的
JobHandler,交由 执行器 统一管理, 执行器 负责接收调度请求并执行对应的JobHandler中业务逻辑。
- 因此,调度 和 任务 两部分可以相互解耦,提高系统整体稳定性和扩展性。
系统主要通过MySQL管理各种定时任务信息:
- 当到了定时任务的触发时间,就把任务信息从数据库中拉进内存,对任务执行器发起调度请求。
架构图
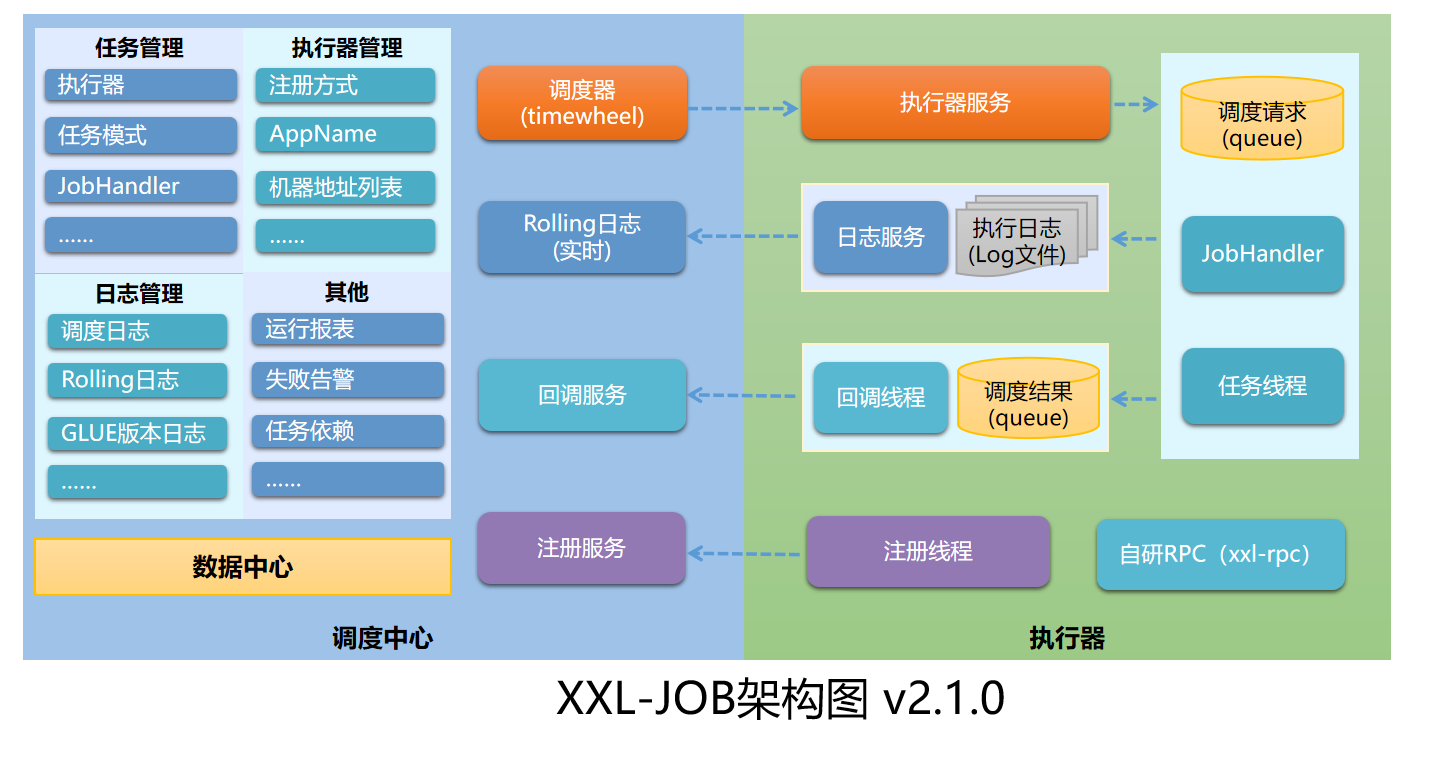
基本原理
执行器的注册和发现:
执行器的注册和发现主要是关系两张表:
xxl_job_registry:
- 执行器的实例表,保存实例信息和心跳信息。
xxl_job_group:
- 每个服务注册的实例列表。
执行器启动线程每隔30秒向注册表
xxl_job_registry请求一次,更新执行器的心跳信息。调度中心启动线程每隔30秒检测一次
xxl_job_registry。
- 将超过90秒还没有收到心跳的实例信息从
xxl_job_registry删除,并更新xxl_job_group服务的实例列表信息。
调度中心调用执行器:
调度中心通过循环不停的:
- 关闭自动提交事务
- 利
MySQL的悲观锁,其他事务无法进入- 读取数据库中的
xxl_job_info:
- 记录定时任务的相关信息,该表中有
trigger_next_time字段表示下一次任务的触发时间- 拿到距离当前时间5s内的任务列表,分为三种情况处理:
- 对于当前时间-任务的下一次触发时间>5,直接调过不执行,重置
trigger_next_time的时间(超过5s)- 对于任务的下一次触发时间<当前时间<任务的下一次触发时间+5的任务(不超过5s的):
- 开线程处理执行触发逻辑,根据当前时间更新下一次任务触发时间
- 如果新的任务下一次触发时间-当前时间<5,放到时间轮中,时间轮是一个MAP
- 根据新的任务下一次触发时间更新下下一次任务触发时间
- 对于任务的下一次触发时间>当前时间,将其放入时间轮中,根据任务下一次触发时间更新下下一次任务触发时间
- Commit提交事务,同时释放排他锁
1 | select * from xxl_job_lock where lock_name = 'schedule_lock' for update |
执行器的操作:
执行器接收到调度中心的调度信息,将调度信息放到对应的任务的等待队列中。
执行器的任务处理线程从任务队列中取出调度信息,执行业务逻辑。
- 将结果放入一个公共的等待队列中(每个任务都有一个单独的处理线程和等待队列,任务信息放入该队列中)。
执行器有一个专门的回调线程定时批量从结果队列中取出任务结果,并且回调告知调度中心。
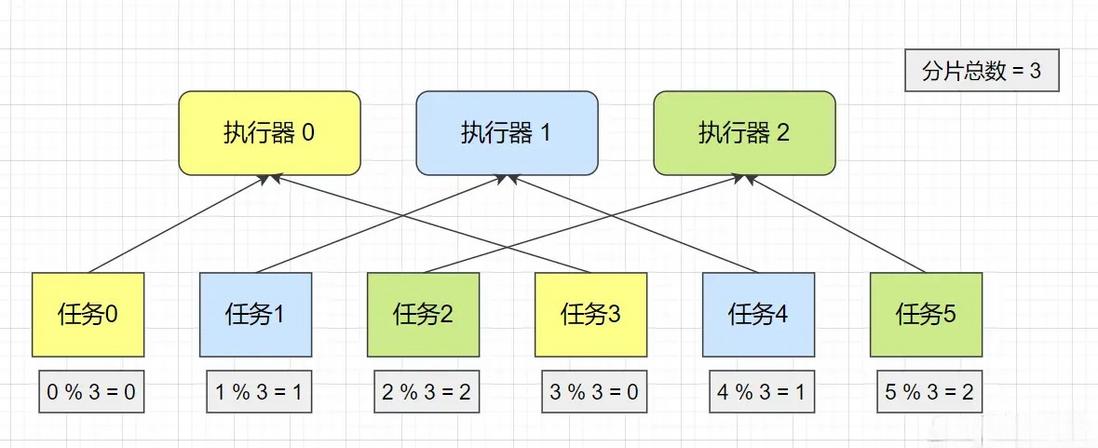
怎么将任务均分给每台服务器?
利用
XXL-JOB在集群部署时,配置路由策略中选择 分片广播 的方式。
- 可以使一次任务调度会广播触发集群中所有的执行器执行一次任务,并且可以向系统传递分片参数。
扫描任务表,根据任务 ID 对分片总数 取模 来实现对所有分片的均分任务。
- 通过判断是否是当前分片序号,并且当前任务状态为
1(未处理)或3(处理失败)并且当前任务失败次数小于3次时可以取得当前任务。每次扫描只取出
count个任务数(批量处理)。通过 分片广播 + 取模 的方式即可实现对集群服务均分任务的操作。
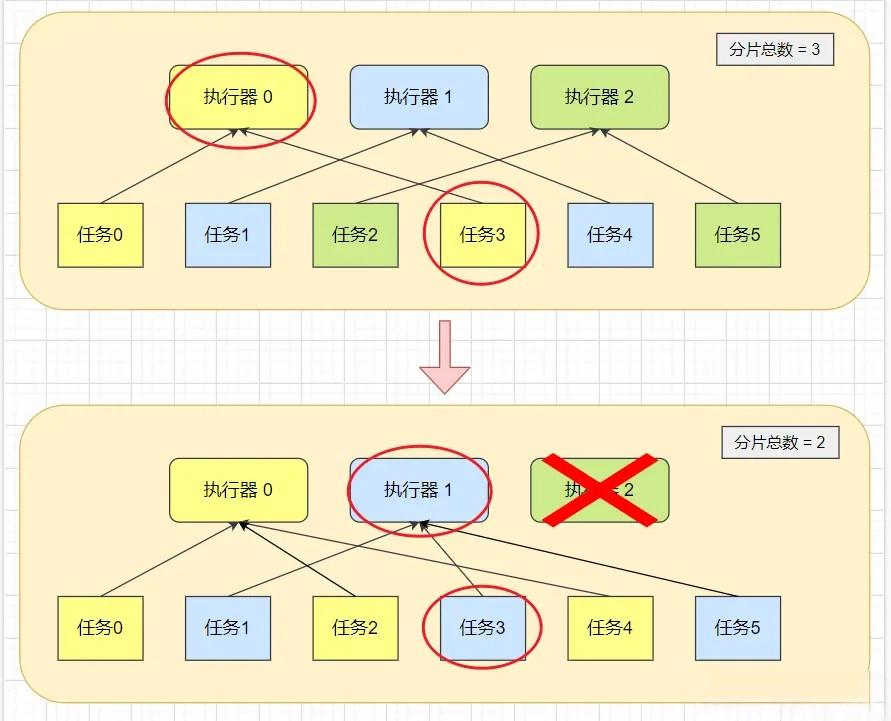
怎么确保任务不会被重复消费?
有三台集群机器和六个任务,刚开始分配好了每台机器两个任务,执行器0正准备执行任务3时,刚好执行器2宕机了。
此时执行器1刚好执行一次任务,因为分片总数减小,导致执行器1重新分配到需要执行的任务正好也是任务3。
- 那么此时就会出现执行器0和执行器1都在执行任务3的情况。
XXL-JOB使用乐观锁的方式实现幂等性。使用
CAS的方式通过比较和设置的方式只有在状态为未处理或处理失败时才能设置为处理中。这样在并发场景下,即使多个执行器同时处理该任务。
- 也只有一个任务可以设置成功进入处理任务阶段。
为了真正达到幂等性,还需要设置一下
XXL-JOB的调度过期策略和阻塞处理策略来保证真正的幂等性。分别设置为 忽略(调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间) 和 丢弃后续调度:
- 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败。












{kind=link}