LLM实现记忆功能思路与常见记忆模式!
LLM实现记忆功能思路与常见记忆模式!
月伴飞鱼LLM实现记忆功能思路
大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮对话,并有一定的上下文记忆功能。
但实际上,模型本身时不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。
而实现这个记忆功能,就需要额外的模块取保存我们和模型对话的上下文信息。
- 然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出结果。
所以为 LLM 添加记忆其实非常简单,就是在 Prompt 中预留
chat_history占位符。将 Human/Ai 的历史对话信息插入到占位符中,并且实时保存 Human/Ai 的对话信息。
在每一次对话时插入到预留占位符即可完成最简单的记忆功能。
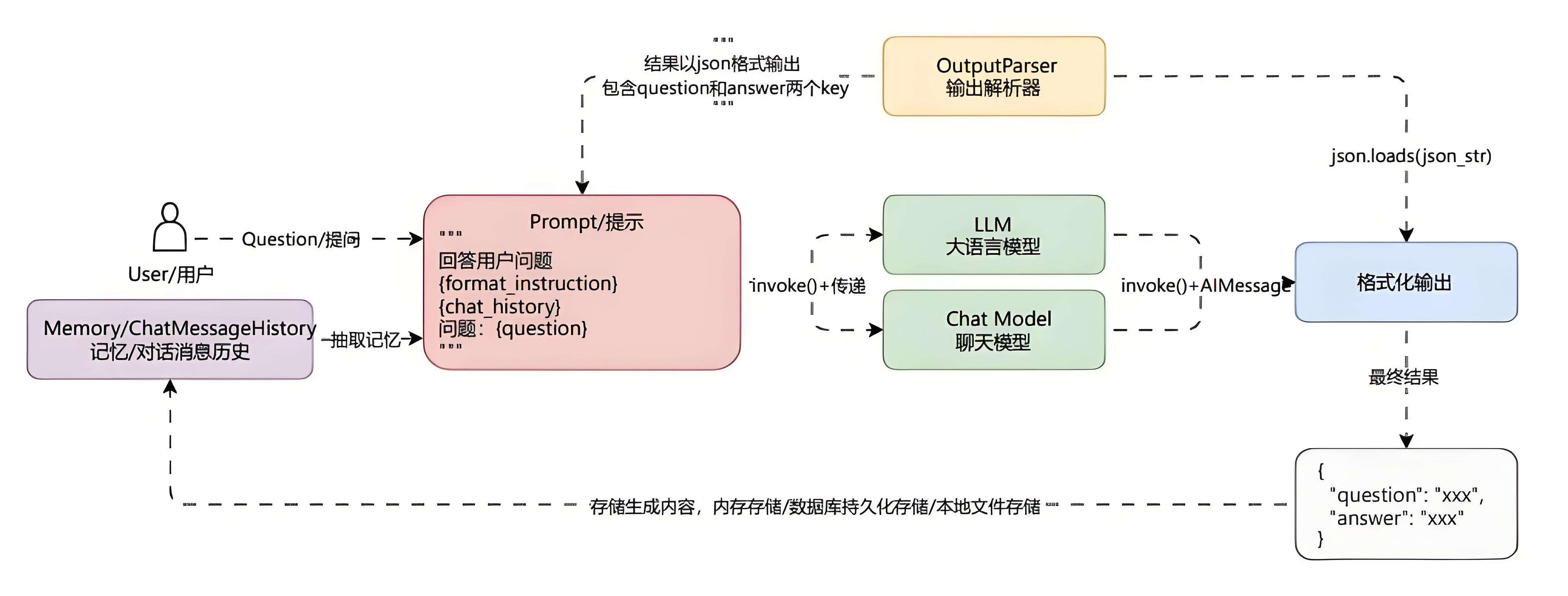
用户通过前端界面或接口发起自然语言问题,该问题作为系统的输入请求,进入问答处理流程。
系统调用对话记忆模块(
Memory/ChatMessageHistory)。
- 提取当前用户的历史对话上下文信息,以便构建具有上下文感知能力的模型输入。
系统将当前用户问题与提取到的历史对话内容一并填充至预定义的 Prompt 模板中。
该模板通常包含格式化指令(
format_instruction)、对话历史(chat_history)以及当前问题(question)。
- 用于明确模型的生成目标和输出格式。
构造完成的 Prompt 被传递至大语言模型(LLM)或聊天模型(Chat Model)。
通过
invoke()方法执行推理请求,模型基于输入内容生成响应文本,封装为 AIMessage 对象返回。生成的 AIMessage 文本输出由输出解析器(OutputParser)进行结构化处理。
解析器根据预期格式(如 JSON)对模型输出进行解析,提取出关键字段(如 question 和 answer),实现结果的可编程化利用。
结构化后的结果被传入格式化输出模块,作为最终响应返回给用户。
同时,该结果可选择性地存储至本地文件系统、数据库或重新写入对话记忆模块,以支持持续的多轮对话交互。
最终,系统输出包含原始问题与模型回答的标准化 JSON 结果,确保问答过程的可追溯性与结构化输出的一致性。
常见记忆模式
基于在 Prompt 中插入记忆内容,可以划分成几种记忆模式。
例如:缓冲记忆、缓冲窗口记忆、令牌缓冲记忆、摘要总结记忆、摘要缓冲混合记忆、实体记忆、向量存储库记忆等。
不同的记忆模式有不同的适用场景。
缓冲记忆
最基础的记忆模式,将所有 Human/Ai 生成的消息全部存储起来,每次需要使用时将保存的所有聊天消息列表传递到 Prompt 中。
通过往用户的输入中添加历史对话信息/记忆,可以让 LLM 能理解之前的对话内容。
而且这种记忆方式在上下文窗口限制内是无损的。
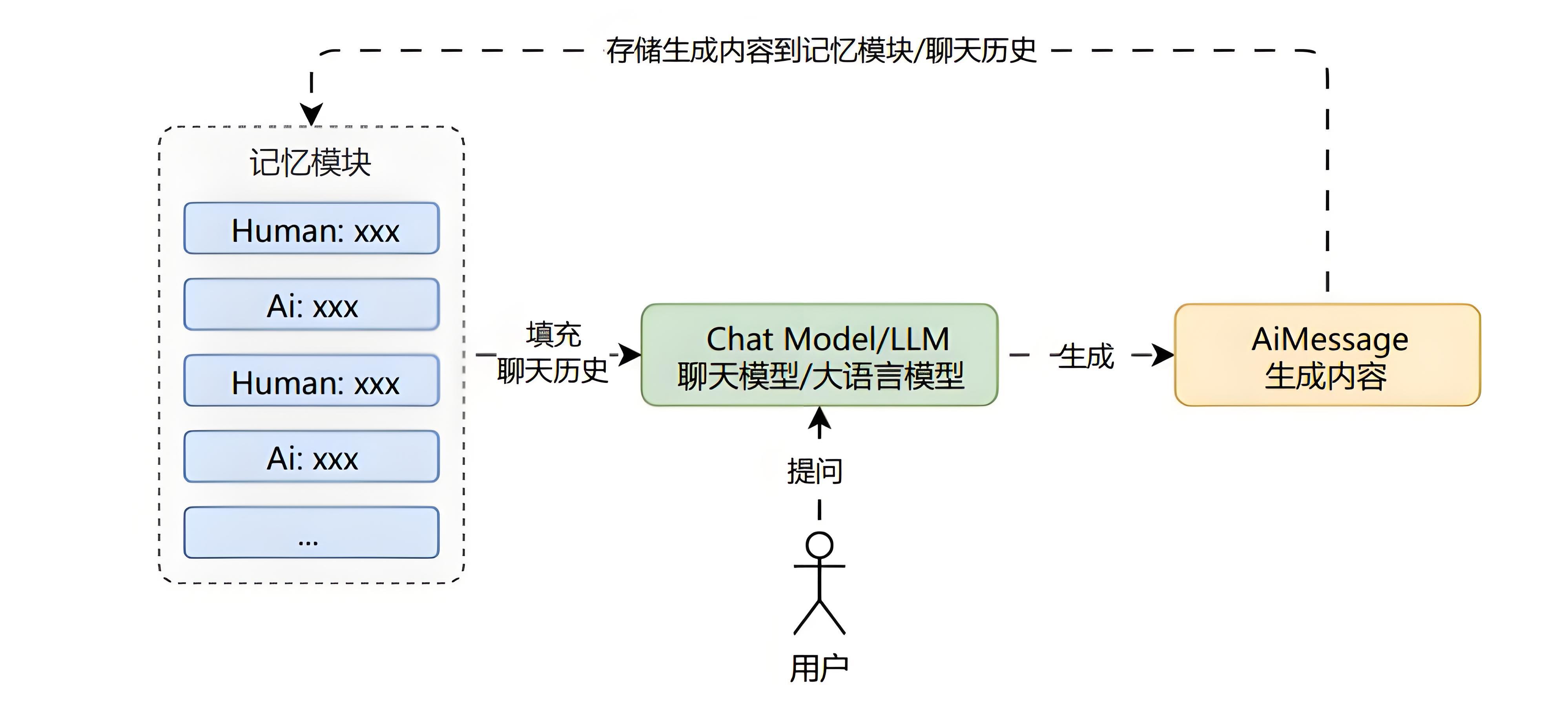
优点:
无损记忆,用户输入什么内容都会被记忆。
实现方式简单,兼容性最好,所有大模型都支持。
缺点:
直接将存储的所有内容给 LLM,因为大量信息意味着新输入中包含更多的 Token,导致响应时间变慢和成本增加。
当达到 LLM 的令牌数限制时,太长的对话无法被记住。
记忆内容不是无限的,对于上下文长度较小的模型来说,记忆内容会变得极短。
缓冲窗口记忆
缓冲窗口记忆只保存最近的几次 Human/Ai 生成的消息。
它基于缓冲记忆 思想,并添加了一个窗口值k ,这意味着只保留一定数量的过去互动,然后忘记之前的互动。
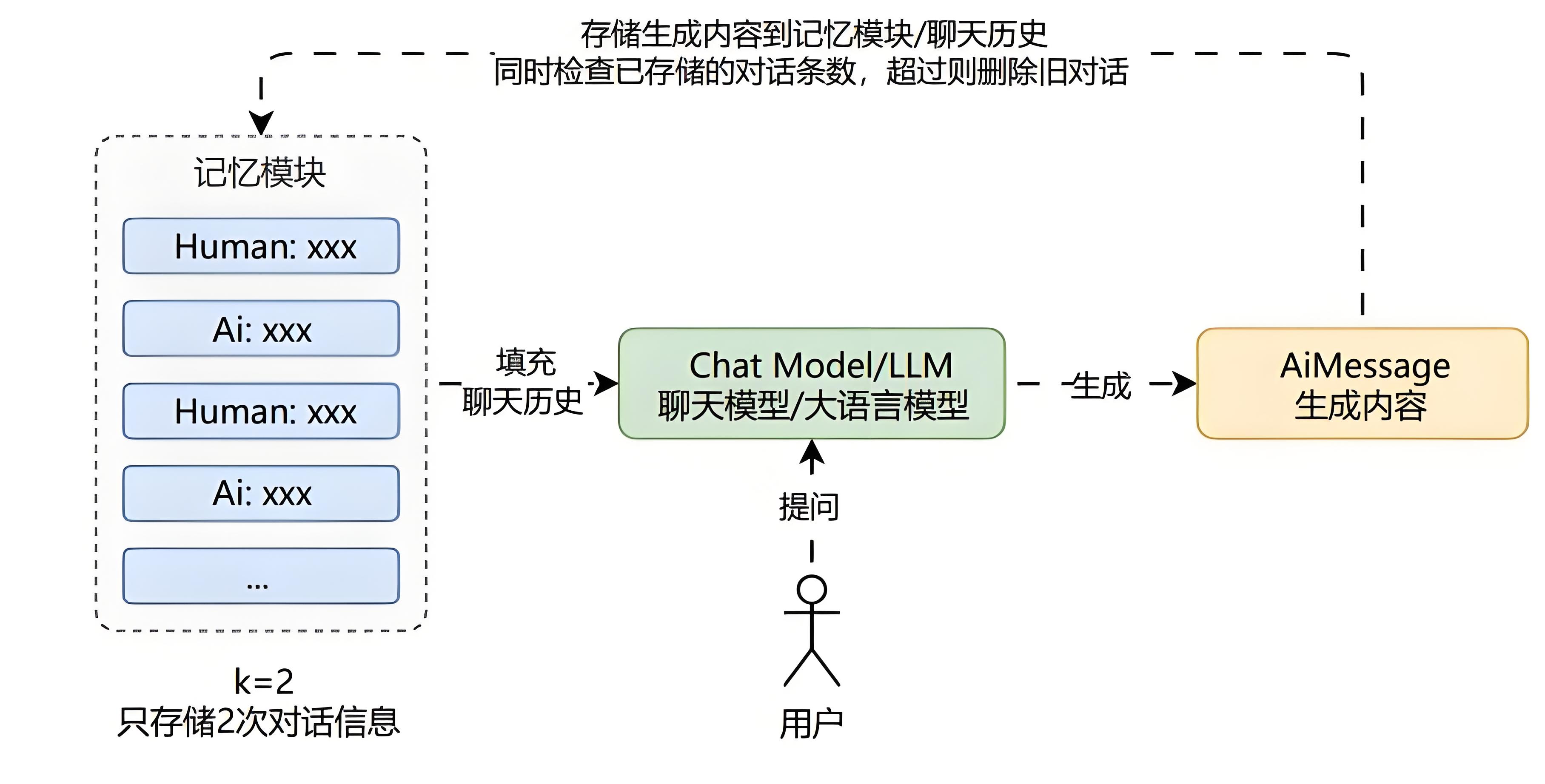
优点:
缓冲窗口记忆在限制使用的 Token 数量表现优异。
对小模型也比较友好,不提问比较远的关联内容,一般效果最佳。
实现方式简单,性能优异,所有大模型都支持。
缺点:
缓冲窗口记忆不适合遥远的互动,会忘记之前的互动。
部分对话内容长度较大,容易超过 LLM 的上下文限制。
令牌缓冲记忆
缓冲窗口记忆只保存限定次数 Human/Ai 生成的消息。
它基于 缓冲记忆 思想,并添加了一个令牌数
max_tokens,当聊天历史超过令牌数时,会遗忘之前的互动。
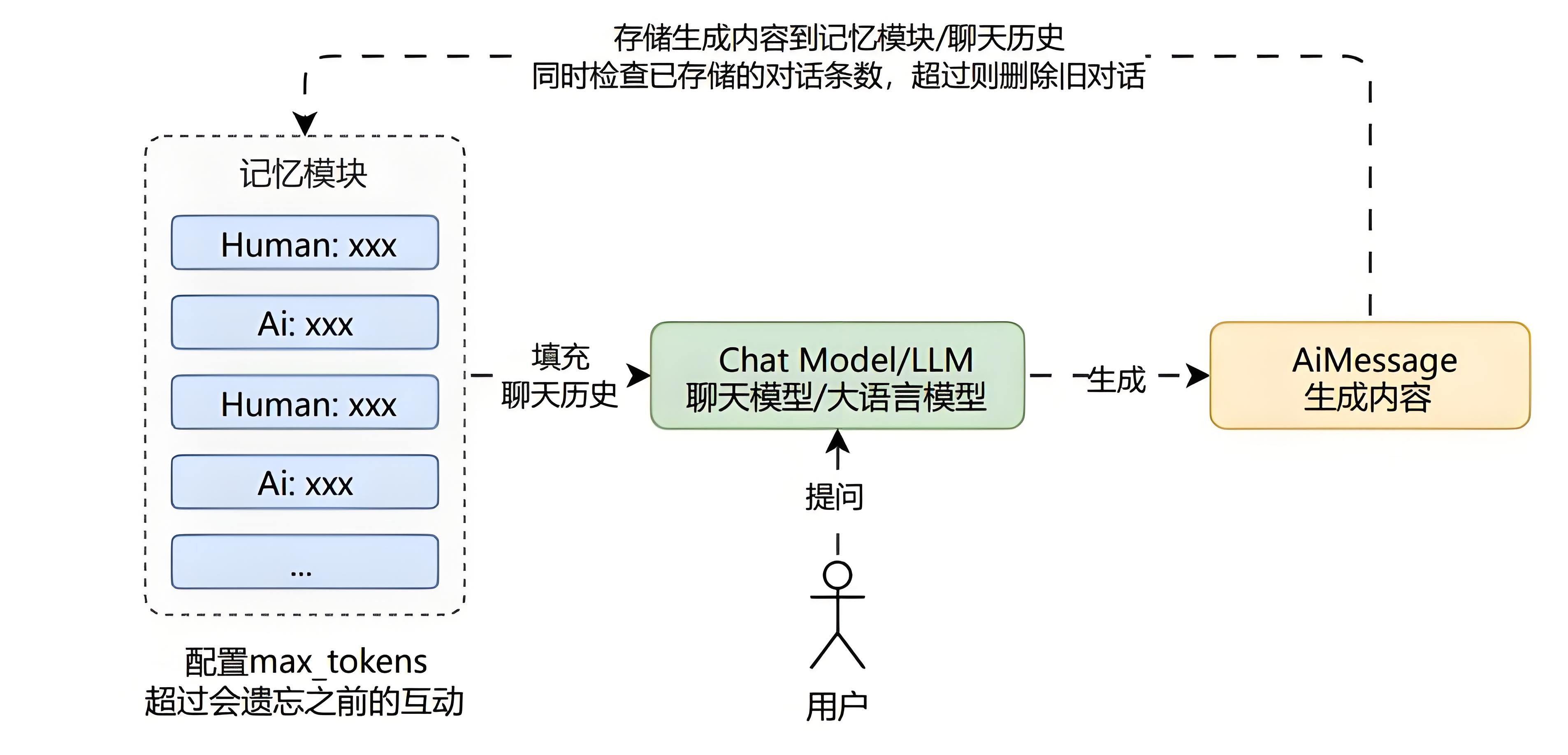
优点:
可以基于大语言模型的上下文长度限制分配记忆长度。
对小模型也比较友好,不提问比较远的关联内容,一般效果最佳。
实现方式简单,性能优异,所有大模型都支持。
缺点:
令牌缓冲记忆不适合遥远的互动,会忘记之前的互动。
摘要总结记忆
除了将消息传递给 LLM,还可以将消息进行总结,每次只传递总结的信息,而不是完整的消息。
这种模式记忆对于较长的对话最有用,可以避免过度使用 Token。
因为将过去的信息历史以原文的形式保留在提示中会占用太多的 Token。
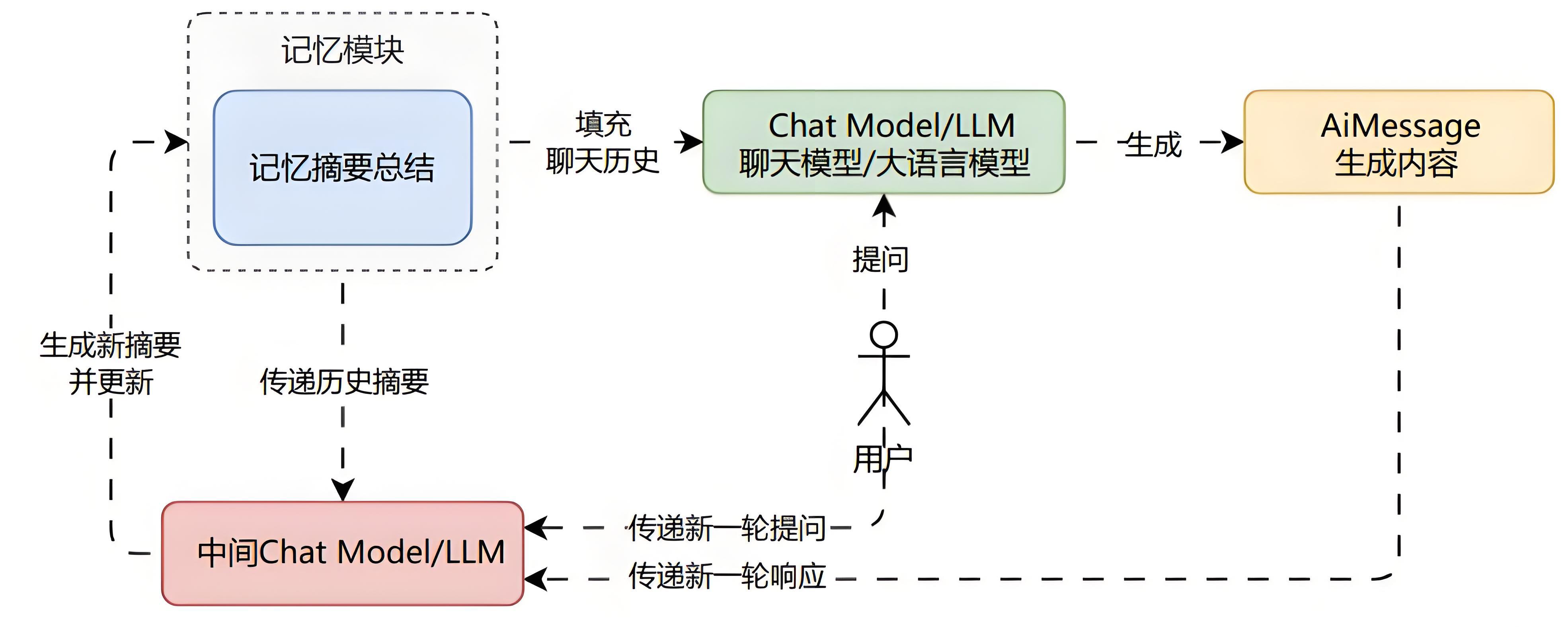
优点:
无论是长期还是短期的互动都可以记忆(模糊记忆)。
减少长对话中使用 Token 的数量,能记忆更多轮的对话信息。
长对话时效果明显,虽然最初使用 Token 数量较多。
随着对话进行,摘要方法增长速度减慢,与常规缓冲内存模型相比具有优势。
缺点:
虽然能同时记住近期和长远的互动内容,但是记忆的细节部分会丢失。
对于较短的对话可能会增加 Token 使用量。
对话历史的记忆完全依赖于中间摘要 LLM 的能力,需要为摘要 LLM 分配 Token,增加成本且未限制对话长度。
摘要缓冲混合记忆
摘要缓冲混合记忆结合了 摘要总结记忆 与 缓冲窗口记忆 ,它旨在对对话进行摘要总结,同时保留最近互动中的原始内容。
但不是简单地清除旧的交互,而是将它们编译成摘要并同时使用,并且使用标记长度而不是交互数量来确定何时清除交互。
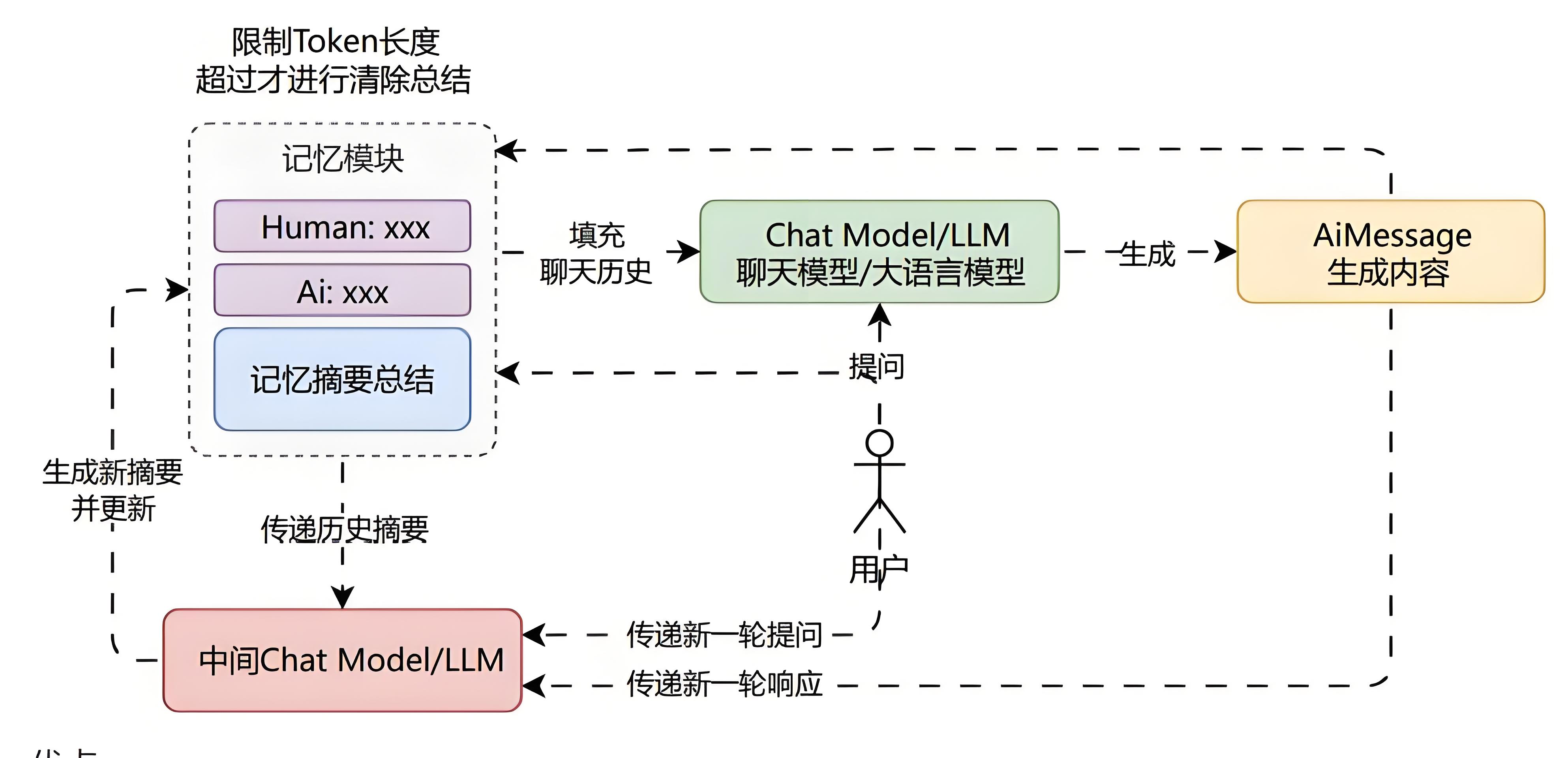
优点:
无论是长期还是短期的互动都可以记忆,长期为模糊记忆,短期为精准记忆。
减少长对话中使用 Token 的数量,能记忆更多轮的对话信息。
缺点:
长期互动的内容仍然为模糊记忆。
总结摘要部分完全依赖于中间摘要 LLM 的能力,需要为摘要 LLM 分配 Token,增加成本且未限制对话长度。
向量存储库记忆
将记忆存储在向量存储中,并在每次调用时查询前 K 个最匹配的文档。
这类记忆模式能记住所有内容,在细节部分比摘要总结要强,但是比缓冲记忆弱,消耗 Token 方面相对平衡。
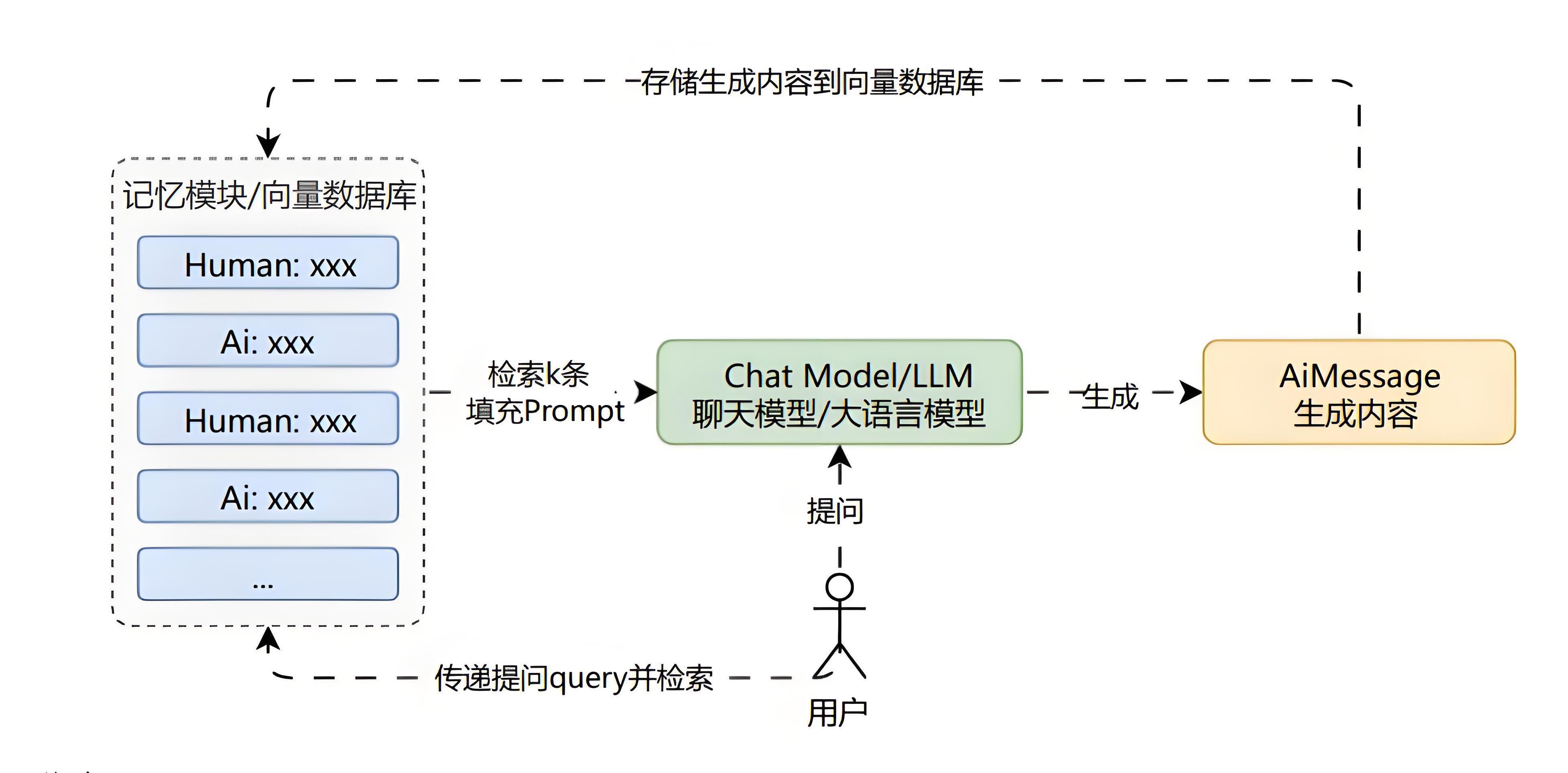
优点:
拥有比摘要总结更强的细节,比缓冲记忆能记忆更多的内容,甚至无限长度的内容。
消耗的 Token 也相对平衡。
缺点:
性能相比其他模式相对较差,需要额外的 Embedding + 向量数据库支持。
记忆效果受检索功能的影响,好的非常好,差的非常差。

















{kind=link}