Embedding文本嵌入模型介绍!
Embedding文本嵌入模型介绍!
月伴飞鱼什么是 Embedding?
要想使用向量数据库的相似性搜索,存储的数据必须是向量。
那么如何将高维度的文字、图片、视频等非结构化数据转换成向量呢?
这个时候就需要使用到
Embedding嵌入模型了。
例如下方就是 Embedding 嵌入模型的运行流程:
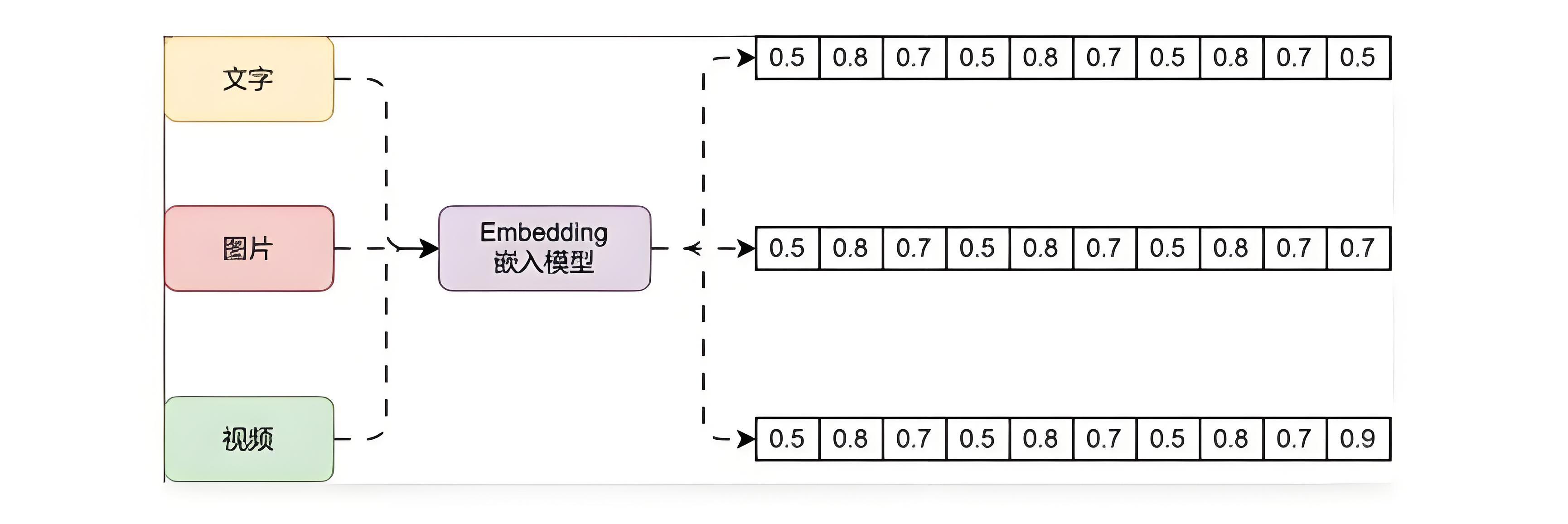
Embedding 模型是一种在机器学习和自然语言处理中广泛应用的技术。
它旨在将高纬度的数据(如文字、图片、视频)映射到低纬度的空间。
Embedding 向量是一个 N 维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。
- 这种嵌入可以是一个词、一个类别特征(如商品、电影、物品等)或时间序列特征等。
而且通过学习,Embedding 向量可以更准确地表示对应特征的内在含义。
使几何距离相近的向量对应的物体有相近的含义,甚至对向量进行加减乘除算法都有意义。
一句话理解 Embedding:
一种模型生成方法,可以将非结构化的数据,例如文本/图片/视频等数据映射成有意义的向量数据。
目前生成 Embedding 方法的模型有以下 4 类。
Word2Vec(词嵌入模型):
这个模型通过学习将单词转化为连续的向量表示,以便计算机更好地理解和处理文本。
Word2Vec 模型基于两种主要算法 CBOW 和 Skip-Gram。
Glove:
一种用于自然语言处理的词嵌入模型。
它与其他常见的词嵌入模型(如 Word2Vec 和 FastText)类似,可以将单词转化为连续的向量表示。
GloVe 模型的原理是通过观察单词在语料库中的共现关系,学习得到单词之间的语义关系。
具体来说,GloVe 模型将共现概率矩阵表示为两个词向量之间的点积和偏差的关系。
- 然后通过迭代优化来训练得到最佳的词向量表示。
GloVe 模型的优点是它能够在大规模语料库上进行有损压缩,得到较小维度的词向量,同时保持了单词之间的语义关系。
这些词向量可以被用于多种自然语言处理任务,如词义相似度计算、情感分析、文本分类等。
FastText:
一种基于词袋模型的词嵌入技术。
与其他常见的词嵌入模型(如 Word2Vec 和 GloVe)不同之处在于,FastText考虑了单词的子词信息。
- 其核心思想是将单词视为字符的 n-grams 的集合。
在训练过程中,模型会同时学习单词级别和n-gram级别的表示。
这样可以捕捉到单词内部的细粒度信息,从而更好地处理各种形态和变体的单词。
大模型 Embeddings:
和大模型相关的嵌入模型,如 OpenAI 官方发布的第二代模型:text-embedding-ada-002。
它最长的输入是 8191 个tokens,输出的维度是 1536。
Embedding 带来的价值
降维:
在许多实际问题中,原始数据的维度往往非常高。
例如,在自然语言处理中,如果使用 Token 词表编码来表示词汇,其维度等于词汇表的大小,可能达到数十万甚至更高。
通过 Embedding,我们可以将这些高维数据映射到一个低维空间,大大减少了模型的复杂度。
捕捉语义信息:
Embedding 不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。
例如,在词嵌入中,语义上相近的词在向量空间中也会相近。
这意味着Embedding可以保留并利用原始数据的一些重要信息。
适应性:
与一些传统的特征提取方法相比,Embedding 是通过数据驱动的方式学习的。
这意味着它能够自动适应数据的特性,而无需人工设计特征。
泛化能力:
在实际问题中,我们经常需要处理一些在训练数据中没有出现过的数据。
由于Embedding能够捕捉到数据的一些内在规律,因此对于这些未见过的数据,Embedding仍然能够给出合理的表示。
可解释性:
尽管 Embedding 是高维的,但我们可以通过一些可视化工具(如t-SNE)来观察和理解 Embedding 的结构。
这对于理解模型的行为,以及发现数据的一些潜在规律是非常有用的。

















{kind=link}