Document组件与文档加载器组件使用!
Document组件与文档加载器组件使用!
月伴飞鱼Document 与文档加载器
Document 类是 LangChain 中的核心组件,这个类定义了一个文档对象的结构,涵盖了文本内容和相关的元数据。
Document 也是文档加载器、文档分割器、向量数据库、检索器这几个组件之间交互传递的状态数据。
在 LangChain 旧版本中,Document 还支持 lookup 检索功能,不过新版本下 Document 组件只拥有最基础的记录信息功能:
1 | Document = page_content(页面内容) + metadata(元数据) |
在 RAG 开发中,一般会读取特定来源的数据,而非手动录入数据。
例如:本地 MarkDown 文件、HTML 网页、PDF 文档、DOC 文档、URL 链接等多种方式来加载数据。
- 然后再将原始文档按照特定切割成特定大小的文档,最后再将数据存储到向量数据库中,很少会手动录入数据。
所以在 RAG 应用外部,一般都会有一个额外的扩展,专门用于处理 读取数据-切割数据-存储数据 这个流程。
并且这个流程非常耗时。
例如上传一个 30M 的文档,需要执行加载/切割/文本嵌入,一般都会使用队列/异步进行处理,架构流程图更新如下:
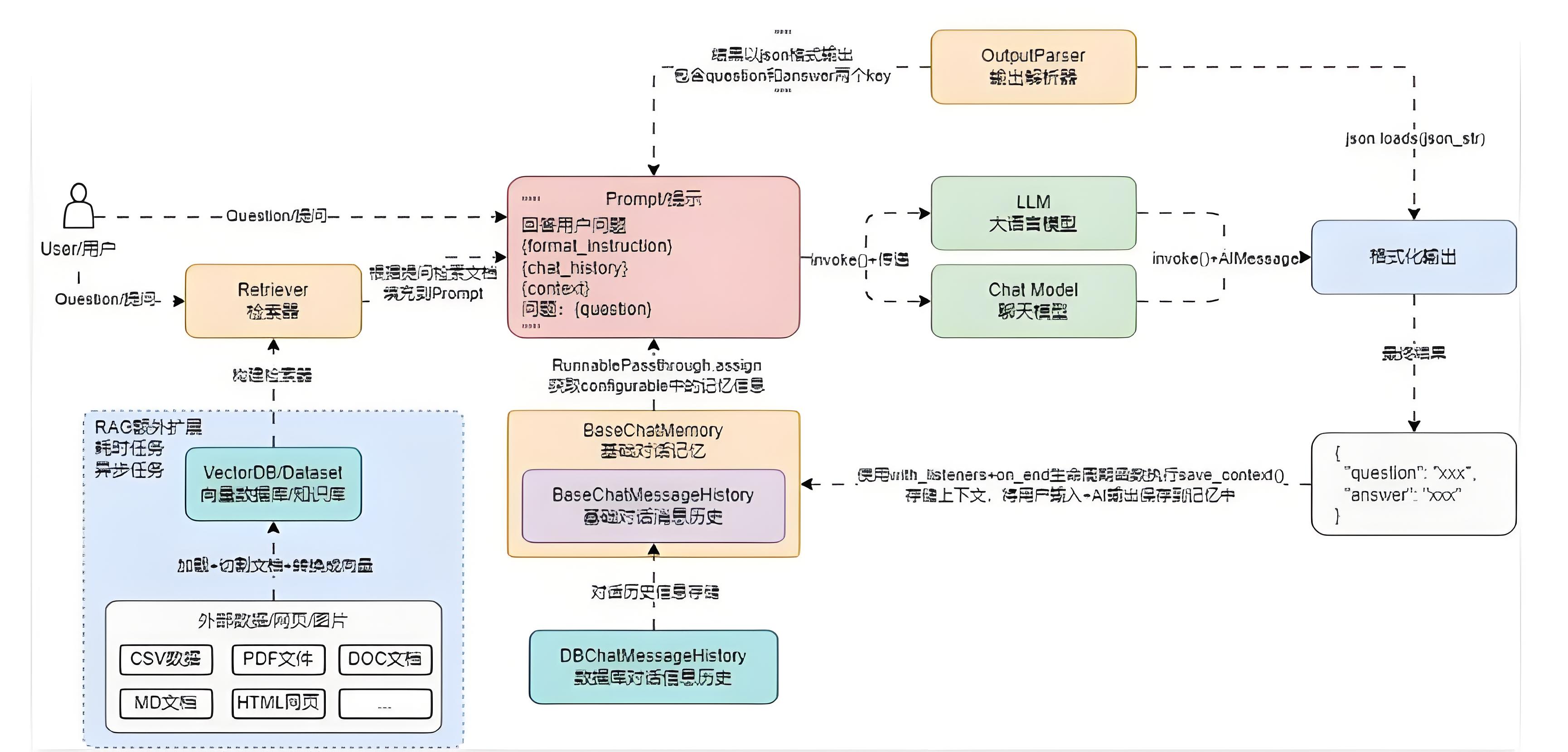
在新的架构流程中,文档加载器起到的作用就是从各式各样的数据中提取出相应的信息,并转换成标准的 Document 组件。
从而屏蔽不同类型文件的读取差异。
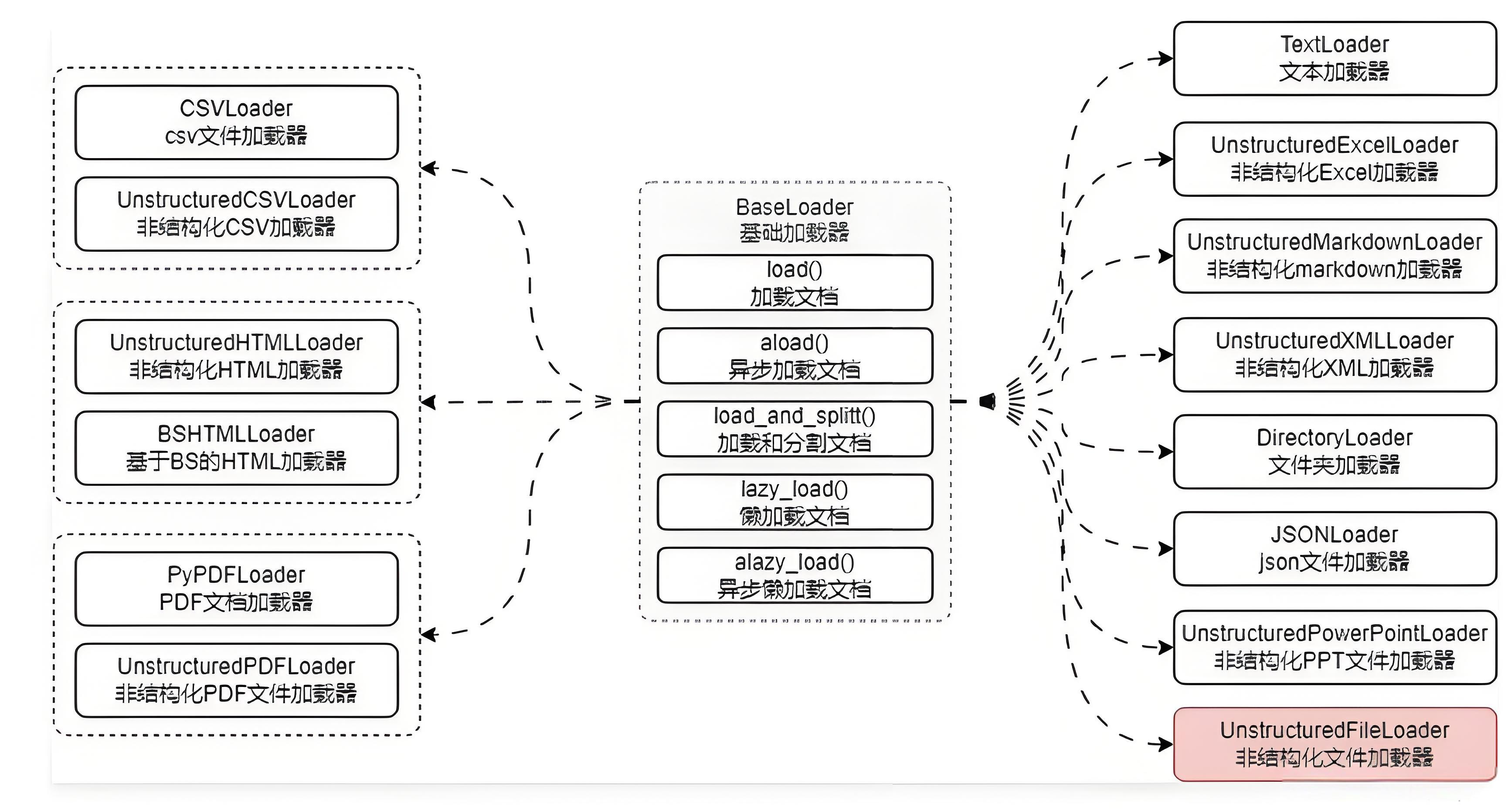
在 LangChain 中所有文档加载器的基类为 BaseLoader,封装了统一的 5 个方法:
load()/aload():
- 加载和异步加载文档,返回的数据为文档列表。
load_and_split():
- 传递分割器,加载并将大文档按照传入的分割器进行切割,返回的数据为分割后的文档列表。
lazy_load()/alazy_load():
- 懒加载和异步懒加载文档,返回的是一个迭代器,适用于传递的数据源有多份文档的情况。
- 例如文件夹加载器,可以每次获得最新的加载文档,不需要等到所有文档都加载完毕。
在 LangChain 中封装了上百种文档加载器,几乎所有的文件都可以使用这些加载器完成数据的读取,而不需要手动去封装:
LangChain 文档加载器文档:https://imooc-langchain.shortvar.com/docs/integrations/document_loaders/
TextLoader 使用技巧与源码解析
在 LangChain 中最简单的加载器组件就是 TextLoader。
这个加载器可以加载一个文本文件(源码、MarkDown、Text 等存储成文本结构的文件,DOC 并不是文本文件)。
并把整个文件的内容读入到一个 Document 对象中,同时为文档对象的 metadata 添加 source 字段用于记录源数据的来源信息。
TextLoader 使用起来非常简单,传递对应的文本路径即可:
1 | from langchain_community.document_loaders import TextLoader |
输出内容:
1 | [Document(page_content='xxx', metadata={'source': './电商产品数据.txt'})] |
TextLoader 源码底层主要通过 open 函数与对应的编码方式打开对应的文件,获取其内容。
并将传递的路径信息复制到生成的文档示例中的 metadata 字段中,从而实现数据的快速加载。
以 TextLoader 为例,扩展到 LangChain 封装的其他文档加载器,使用技巧都是一模一样的。
在实例化加载器的时候,传递对应的信息(文件路径、网址、目录等),然后调用加载器的
load()方法即可一键加载文档。
Markdown文档加载器
Markdown 加载器用于将本地的
.md文件解析为文本,并封装成 LangChain 所使用的 Document 对象。以便后续进行嵌入、匹配、问答等。
1 | #!/usr/bin/env python |
Office文档加载器
Office 文档加载器(Document Loaders for Office Formats)。
是专门用来处理如 Word(.doc, .docx)、Excel(.xls, .xlsx)、PowerPoint(.ppt, .pptx)等 Microsoft Office 文件类型的模块。
适用于构建文档问答(RAG)、生成摘要、知识库索引等应用。
1 | #!/usr/bin/env python |
URL网页加载器
URL 网页加载器是 LangChain 提供的文档加载器中的一种,它能够根据网页链接地址(URL)抓取网页的数据内容。
并封装为 LangChain 支持的 Document 对象,供后续 RAG、查询、摘要等处理。
1 | #!/usr/bin/env python |
通用文件加载器
通用文件加载器 是 LangChain 中用于读取本地或远程文件内容(如
.pdf, .docx, .pptx, .html, .md, .txt等)的工具。它的核心作用是将这些数据转换为 LangChain 能理解和处理的标准 Document 对象。
以便后续用于 问答系统、信息检索、摘要生成、RAG 等任务。
1 | #!/usr/bin/env python |

















{kind=link}