自定义LangChain文档加载器使用技巧!
自定义LangChain文档加载器使用技巧!
月伴飞鱼自定义加载器使用技巧
对于一些企业的内部数据,例如数据库、API接口等定制化非常强的数据。
如果使用通用的文档加载器进行提取,虽然可以提取记录到相应的信息,但是加载的数据格式或者样式大概率没法满足我们的需求。
这个时候就可以考虑实现自定义文档加载器。
例如使用的
WebBaseLoader文档加载器加载网页首页的信息,会提取得到很多空白数据(空格、换行、Tab 等)。将这类数据通过分割存储到向量数据库中,会极大降低检索与生成的效率和正确性。
在 LangChain 中实现自定义文档加载器非常简单,只需要继承 BaseLoader 基类,然后实现
lazy_load()方法即可。如果该文档加载器有异步使用的场景,还需要实现
alazy_load()方法。
假设有一个这样的需求,加载对应的文本信息,其中每行数据都作为一个 Document 组件,该文档加载器实现示例:
1 | from typing import Iterator, AsyncIterator |
输出示例:
1 | [Document(page_content='喵喵🐱\n', metadata={'line_number': 0, 'source': './喵喵.txt'}), Document(page_content='喵喵🐱\n', metadata={'line_number': 1, 'source': './喵喵.txt'}), Document(page_content='喵😻😻', metadata={'line_number': 2, 'source': './喵喵.txt'})] |
文档加载器扩展思考
在上面的自定义文档加载器中,可以看到
lazy_load()方法的两个核心步骤就是:
读取文件数据、将文件数据解析成Document,并且绝大部分文档加载器都有着两个核心步骤。
而且 读取文件数据 这个步骤大家都大差不差。
就像
.md、.txt、*.py这类文本文件,甚至是.pdf、.doc等这类非文本文件,都可以使用同一个读取文件数据。步骤将文件读取为二进制内容,然后在使用不同的解析逻辑来解析对应的二进制内容,所以很容易可以得出:
- 文档加载器 = 二进制数据读取 + 解析逻辑
因此,在项目开发中,如果大量配置自定义文档解析器的话,将解析逻辑与加载逻辑分离,维护起来会更容易。
而且也更容易复用相应的逻辑(具体使用哪种方式取决于开发)。
这样原先的 DocumentLoader 运行流程就变成了如下:
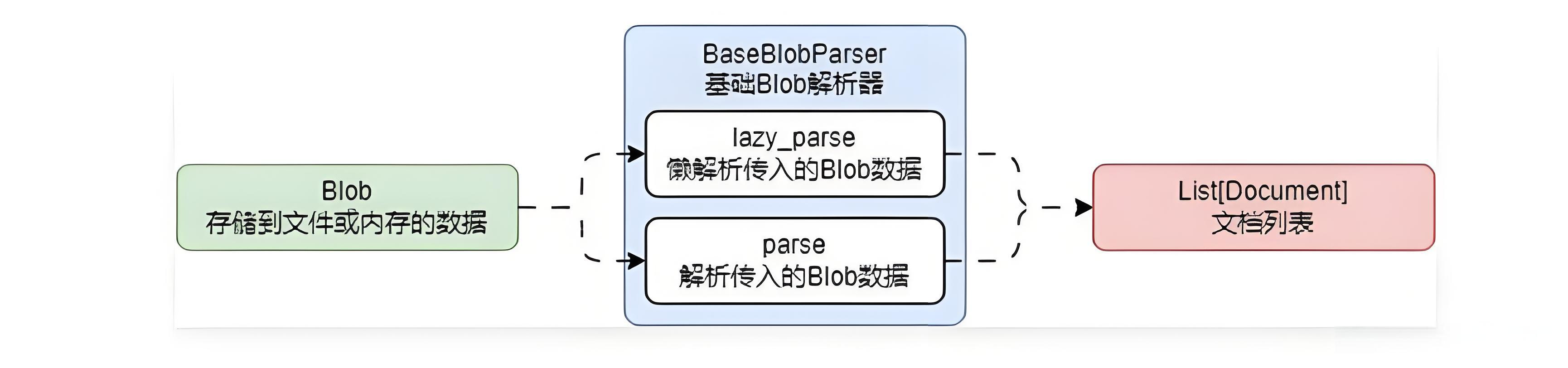
这样所有 DocumentLoader 就变成了共用 Blob(数据读取),每个加载器内部只实现不同的
parse即可。

















{kind=link}