LangChain中的Blob方案!
LangChain中的Blob方案!
月伴飞鱼许多文档加载器都涉及到解析文件,此类加载器之间的差异通常源于文件解析方式,而不是文件加载方式。
例如,你可以使用
open()函数来读取 PDF 或 Markdown 文件的二进制内容。但是需要不同的解析逻辑来将二进制数据转换为文本。
在 LangChain 中也提供了一个类似的解决方案 Blob,其灵感来源于 Blob WebAPI规范(这是前端 Web 浏览器中定义的相关规范)。
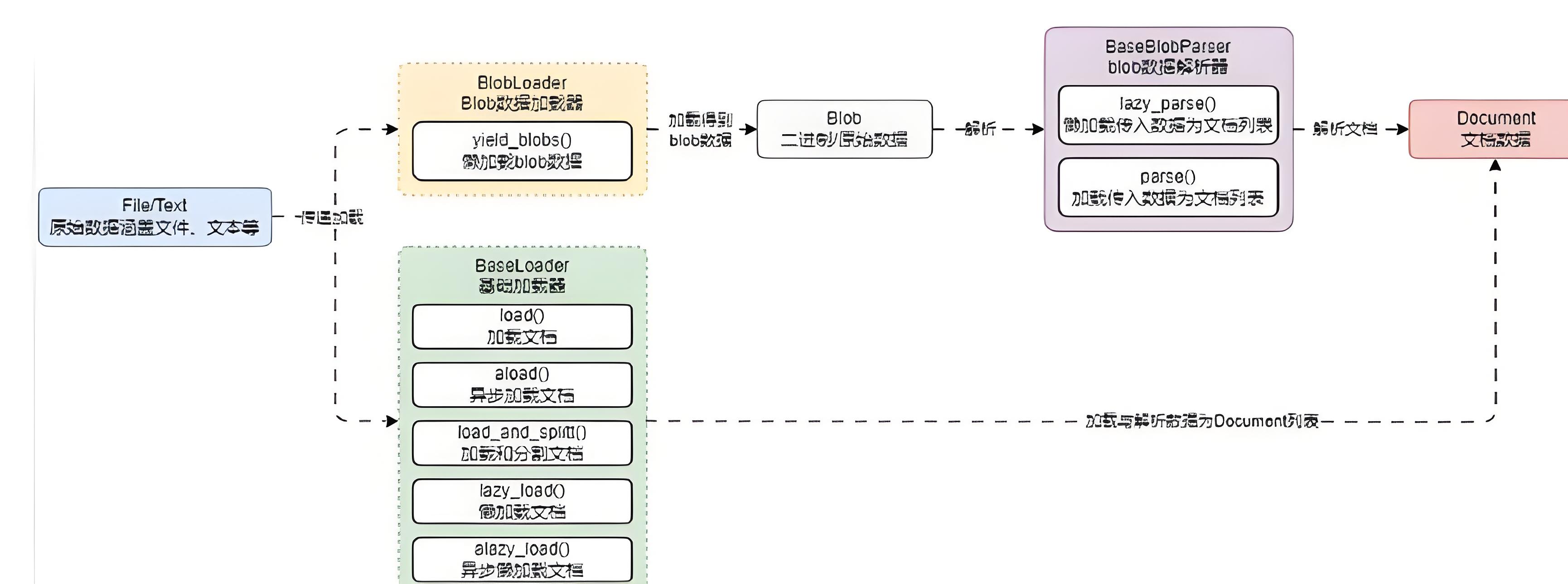
该方案下有 Blob、BlobLoader 和 BaseBlobParser 三个类,含义如下。
Blob:
LangChain 封装的数据对象,通过引用或值表示原始数据,该类提供一个接口,以表示不同形式具体化的二进制数据。
使用该类可以有助于将数据加载器的开发与解析器耦合。
BlobLoader:
Blob 数据加载器,类似 DocumentLoader,不过 BlobLoader 被设计成可以加载任何数据(未来的规划)。
BlobParser:
Blob 数据解析器,用于将传入的 Blob 数据转换成文档列表。
在这个方案下,文档加载器的运行流程变成如下:
例如加载对应的文本信息,其中每行数据都作为一个 Document 组件,使用 Blob 的方案来实现。
只需自定义一个解析器并实现
lazy_parser()方法即可,示例代码如下。
1 | from typing import Iterator |
输出内容:
1 | [Document(page_content='喵喵🐱\r\n', metadata={'source': './喵喵.txt', 'line_number': 0}), Document(page_content='喵喵🐱\r\n', metadata={'source': './喵喵.txt', 'line_number': 1}), Document(page_content='喵😻😻', metadata={'source': './喵喵.txt', 'line_number': 2})] |

















{kind=link}