RAG的10个优化技巧!
RAG的10个优化技巧!
月伴飞鱼Small To Big
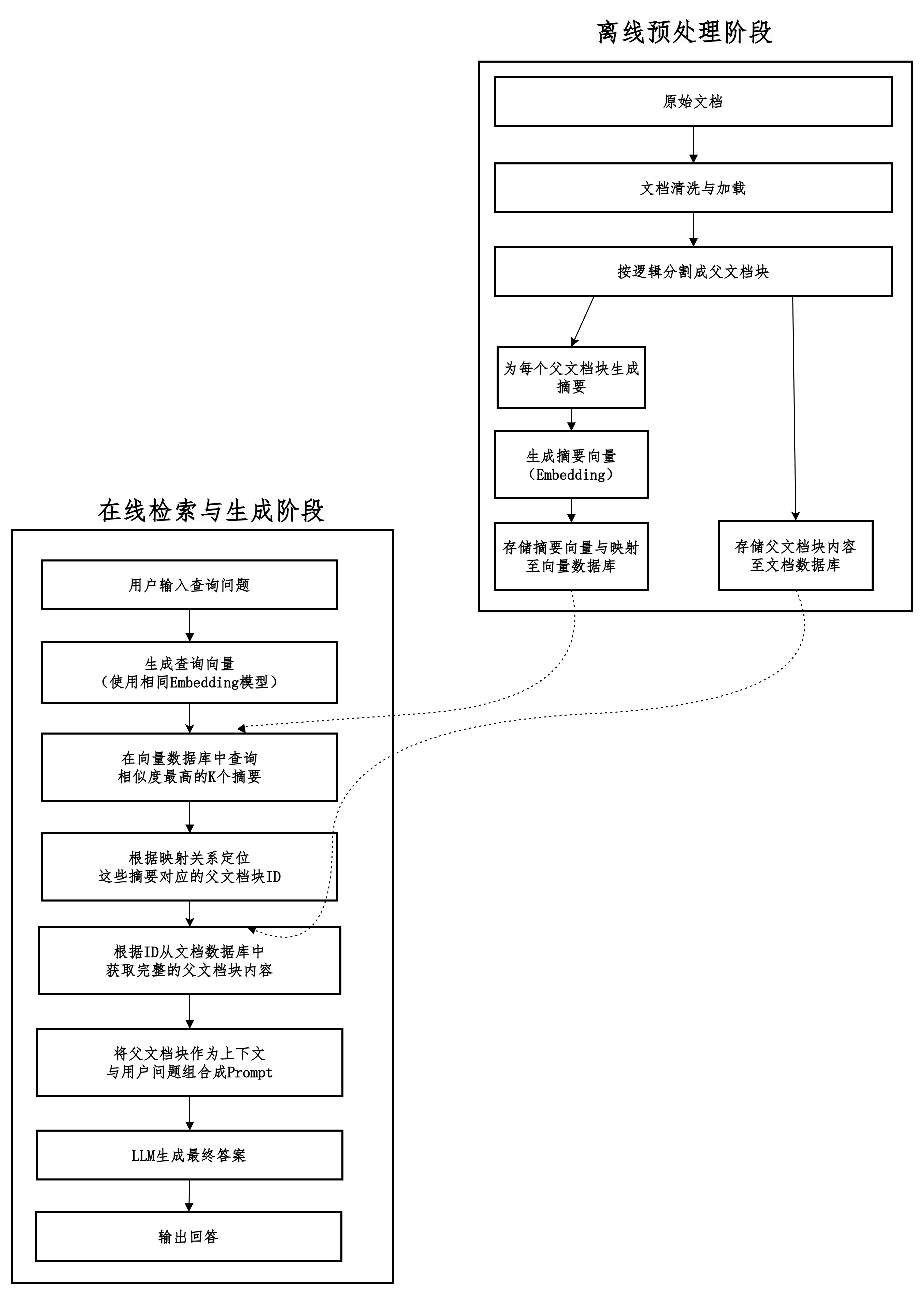
Small(小):
在检索阶段,使用较小的、细粒度的文档块(例如一个段落、几个句子)进行向量相似度计算。
Big(大):
在提供给LLM的阶段,则返回这些小文档块所属的、更大的父文档块作为上下文。
摘要检索
用摘要来寻找,用原文来回答。
在检索阶段,并不直接拿用户的查询去匹配庞大的原始文档,而是去匹配预先为这些文档生成好的、高度浓缩的摘要。
一旦找到相关的摘要,再定位到该摘要所对应的完整原始文档。
并将这些原始文档作为上下文提供给大语言模型(LLM)来生成最终答案。
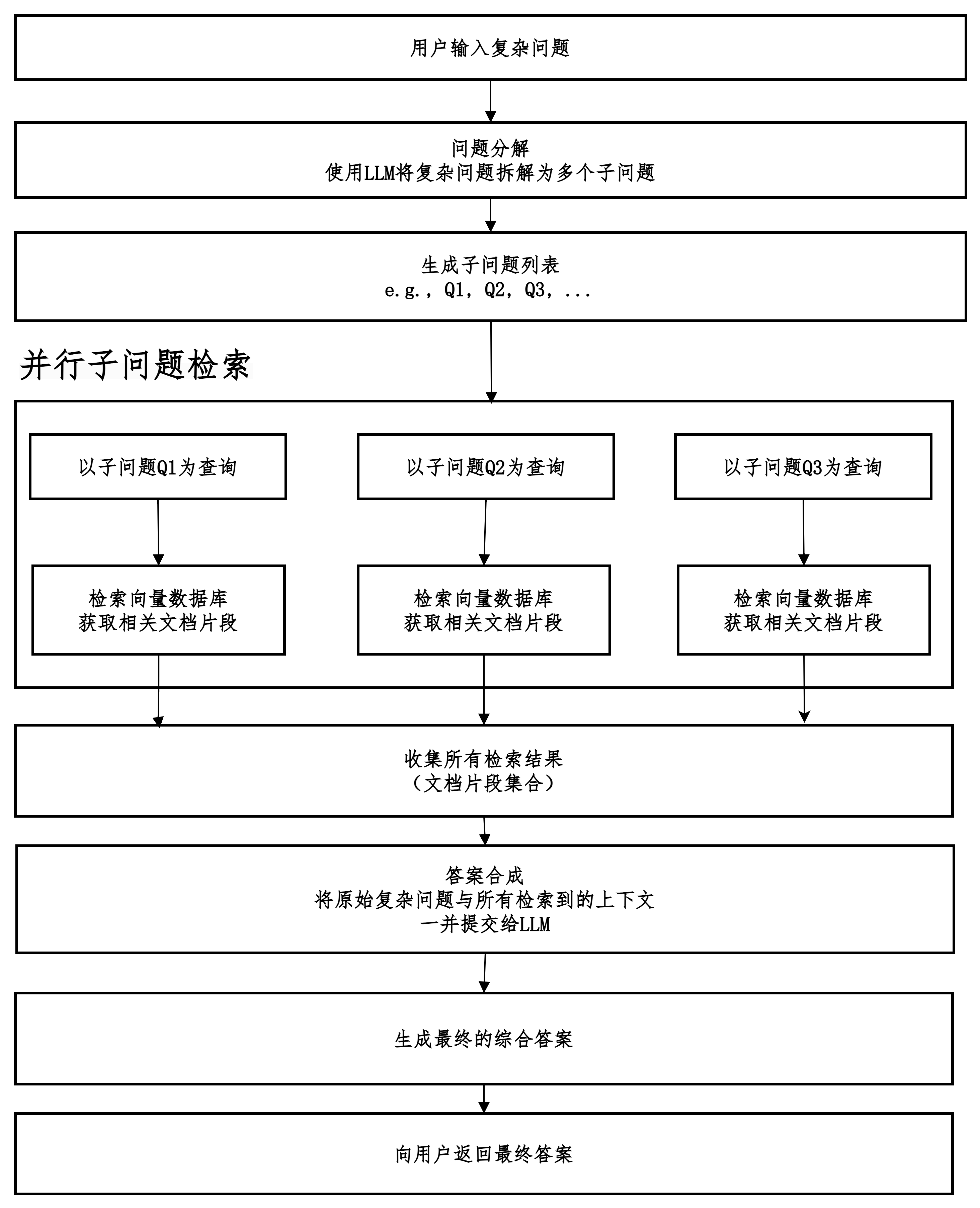
子问题检索
先拆解,分头找,再汇总。
当系统接收到一个复杂的用户问题时,并不直接用它去检索文档。
- 而是先让一个大语言模型(LLM)将这个复杂问题分解成一系列逻辑相关的、更简单的子问题。
然后,系统并行地为每一个子问题独立地进行检索,获取相关的文档片段。
最后,将所有子问题检索到的信息综合起来,交给LLM生成一个全面、准确的最终答案。
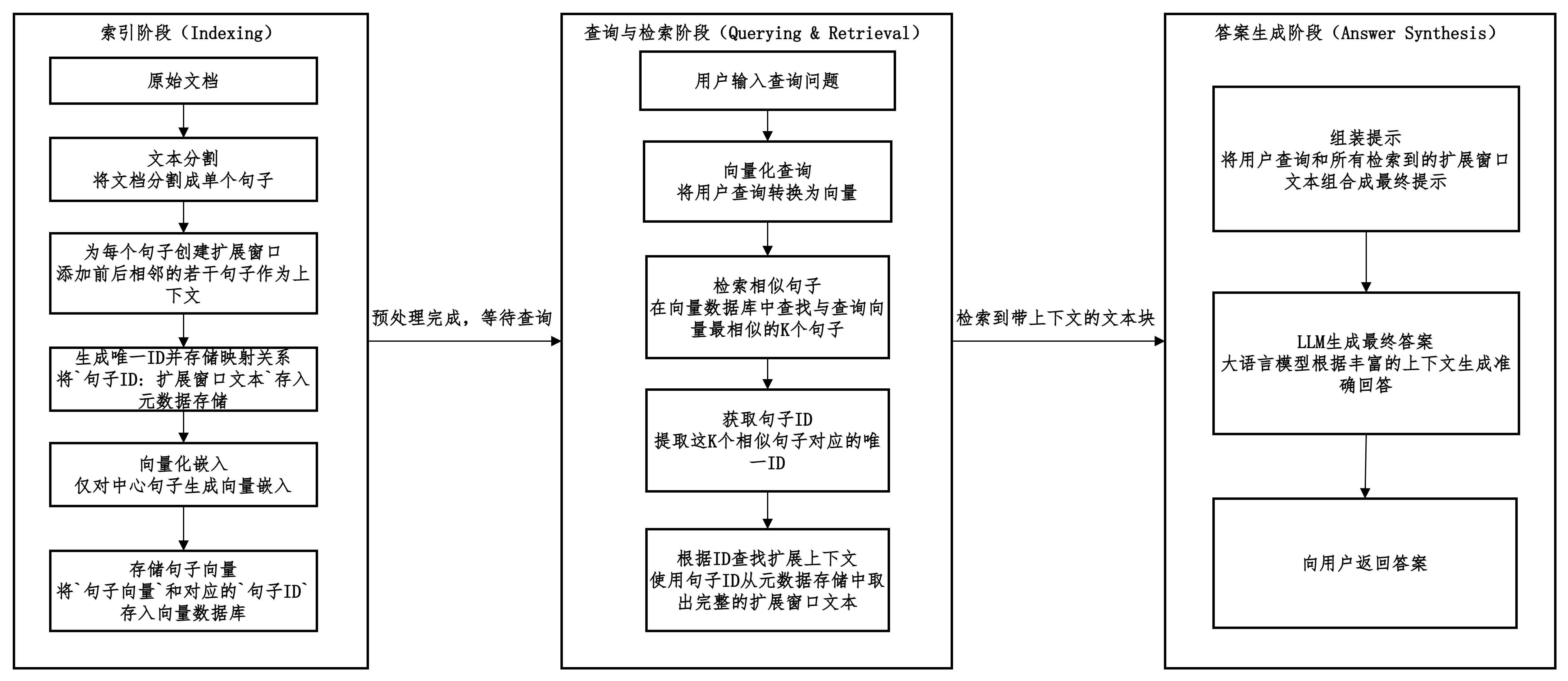
句子窗口检索
先检索最相关的单个句子,然后自动地将这个句子的原始上下文(即它前后相邻的句子)窗口一并找回。
最终将这个完整的窗口提供给LLM。
多路召回
不要把所有的鸡蛋放在一个篮子里。
采用多种不同的策略、方法或渠道(即多路)分别进行信息检索。
然后将各路的结果进行合并、去重和排序,最终筛选出最相关的结果集合。

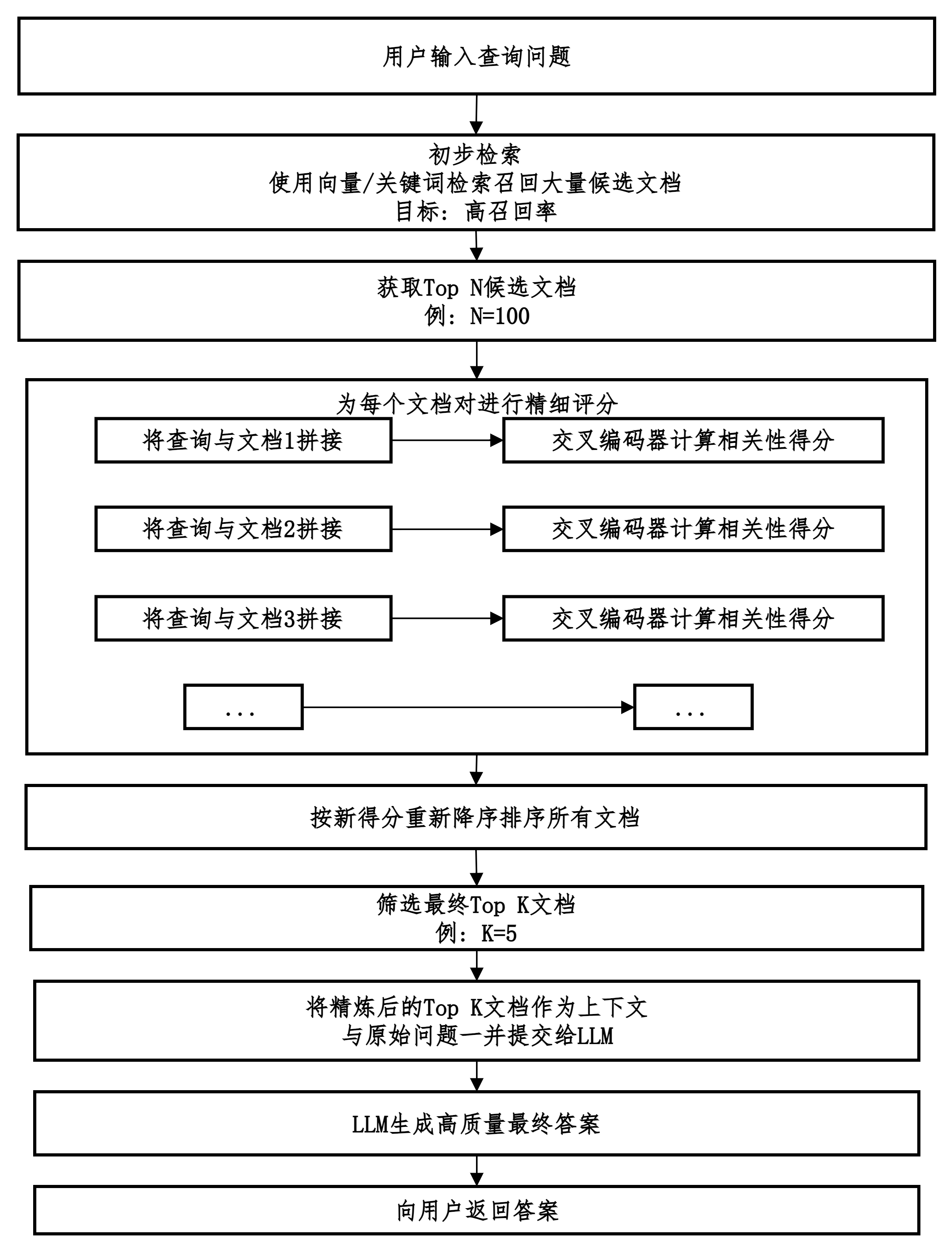
Rerank
初步检索到一批相关文档后,使用一个更精细、更强大的模型对这些文档进行重新评估和排序。
以挑选出与问题真正最相关的少数几个文档的过程。
Refine模式
不一次性处理所有上下文,而是通过多次、迭代的方式,让LLM逐步地、不断地优化和精炼答案。
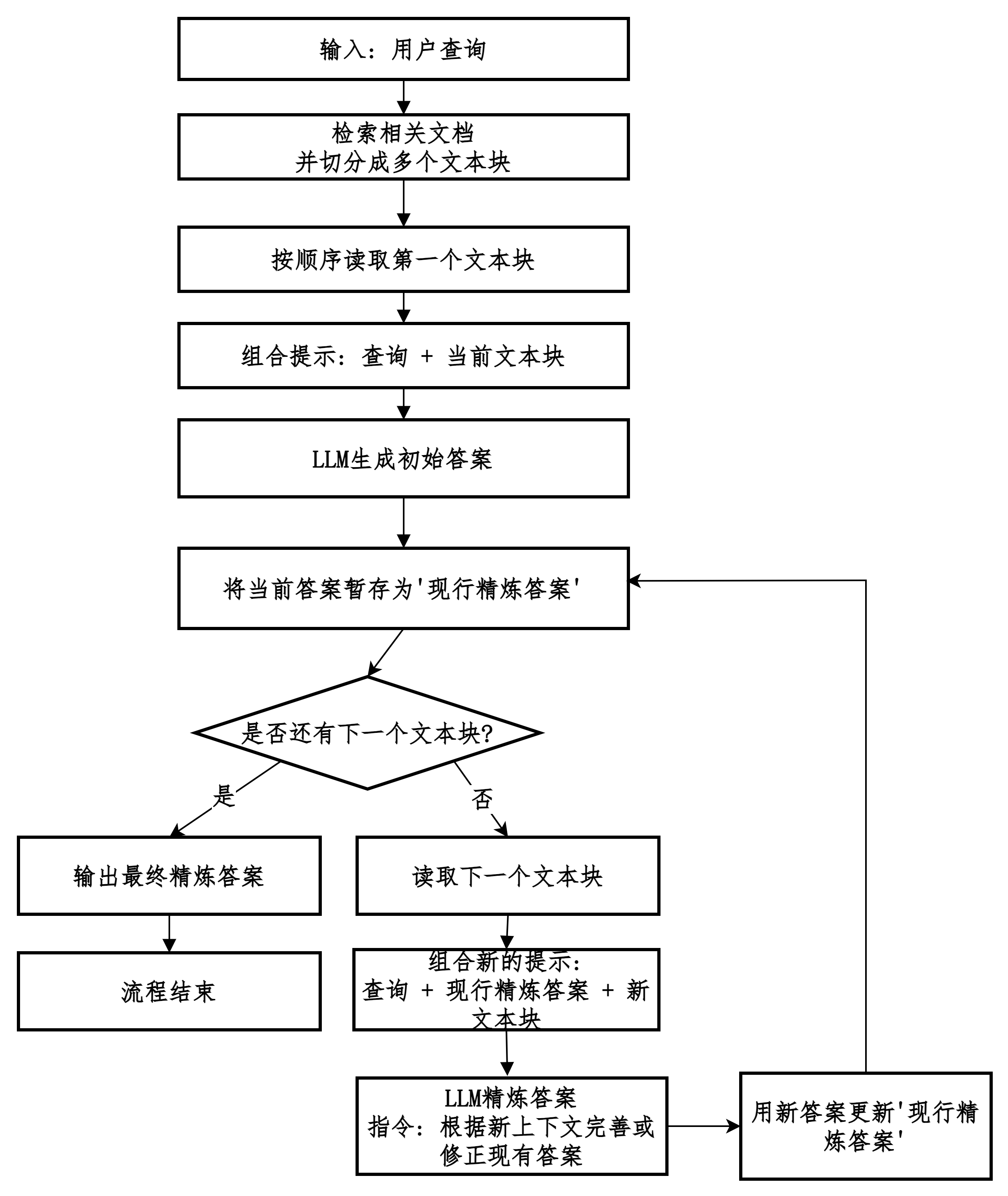
多文档场景的Refine
不一次性处理所有文档,而是让LLM迭代地、一个接一个(或一小批接一小批)地处理文档。
并不断地基于新看到的信息来优化、修正和扩展之前的答案。

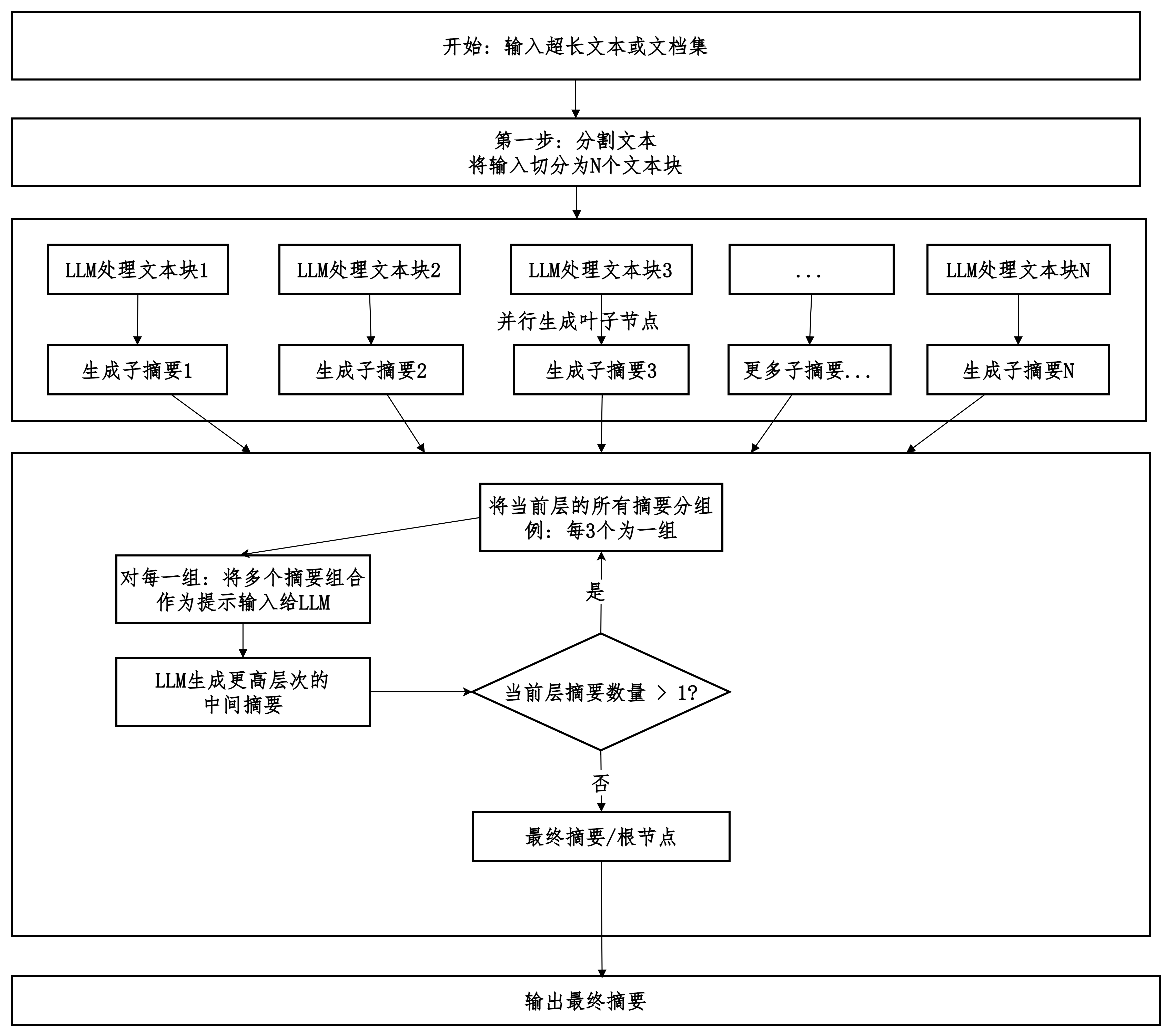
tree_summarize
分而治之。
- 通过并行处理文本块来显著提高速度、降低延迟。
- 通过分层递归汇总来突破上下文窗口限制,处理超长文档。
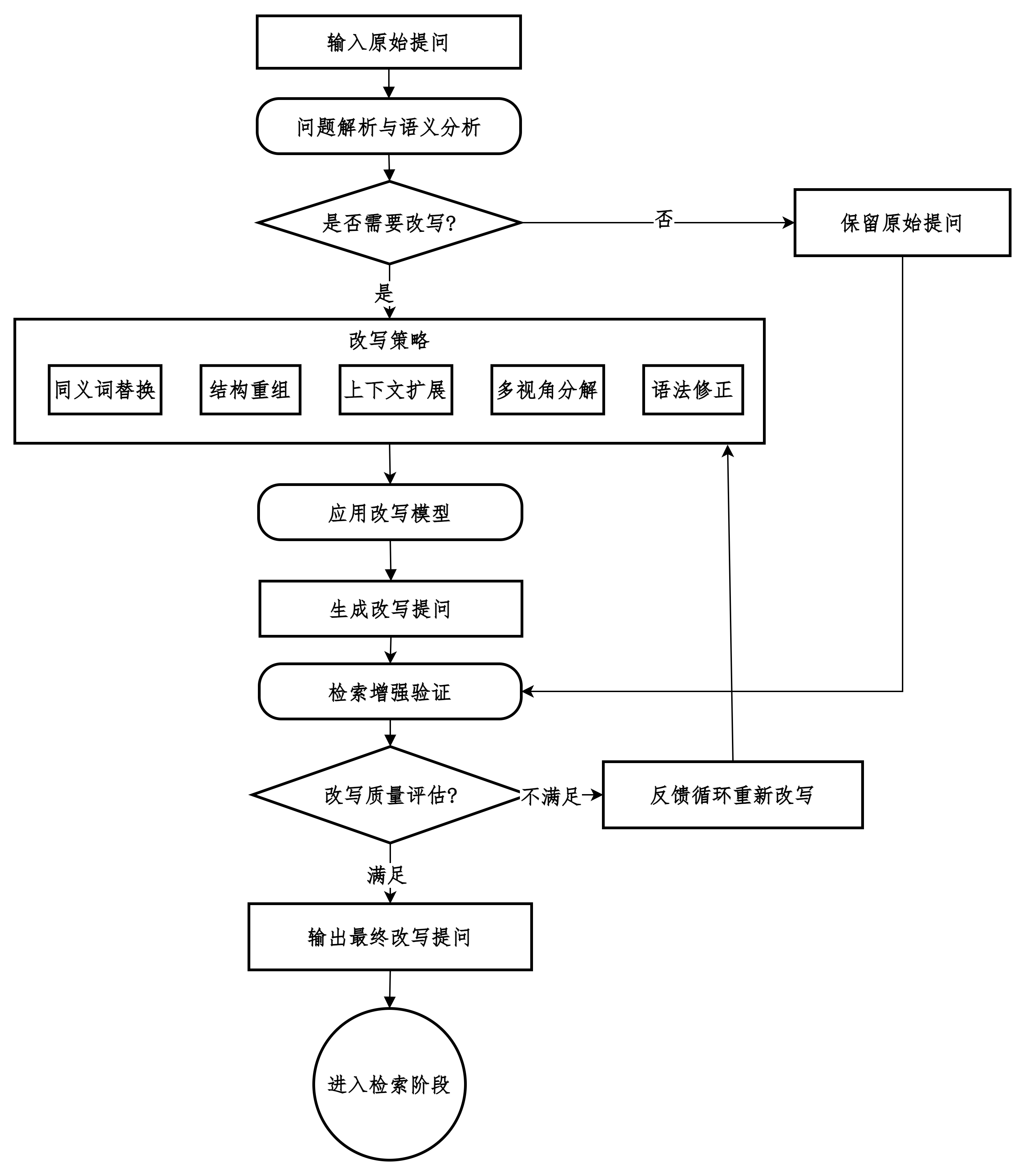
改写提问
在保持用户原始意图不变的前提下,对用户输入的问题或查询(Query)进行重新表述、扩展或优化。
以提升后续检索或回答质量的技术。

















{kind=link}