支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
Apache Flink作为一款高吞吐量、低延迟的针对流数据和批数据的分布式实时处理引擎。
- 和Storm/Spark Streaming一样,定位于流式处理系统。
官网地址:https://flink.apache.org/
官方文档(1.14.2版本):https://nightlies.apache.org/flink/flink-docs-release-1.14/
官方中文文档(1.14.2版本):https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/
主要特点
高吞吐和低延迟:
- 每秒处理数百万个事件,毫秒级延迟。
结果的准确性:
Flink提供了事件时间(event-time)和处理时间(processing-time)语义。
对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
精确一次(exactly-once)的状态一致性保证。
可以连接到最常用的外部系统:如Kafka、Hive、JDBC、HDFS、Redis等。
高可用:
- 本身高可用的设置,加上与K8s,YARN和Mesos的紧密集成。
- 再加上从故障中快速恢复和动态扩展任务的能力,Flink能做到以极少的停机时间7×24全天候运行。
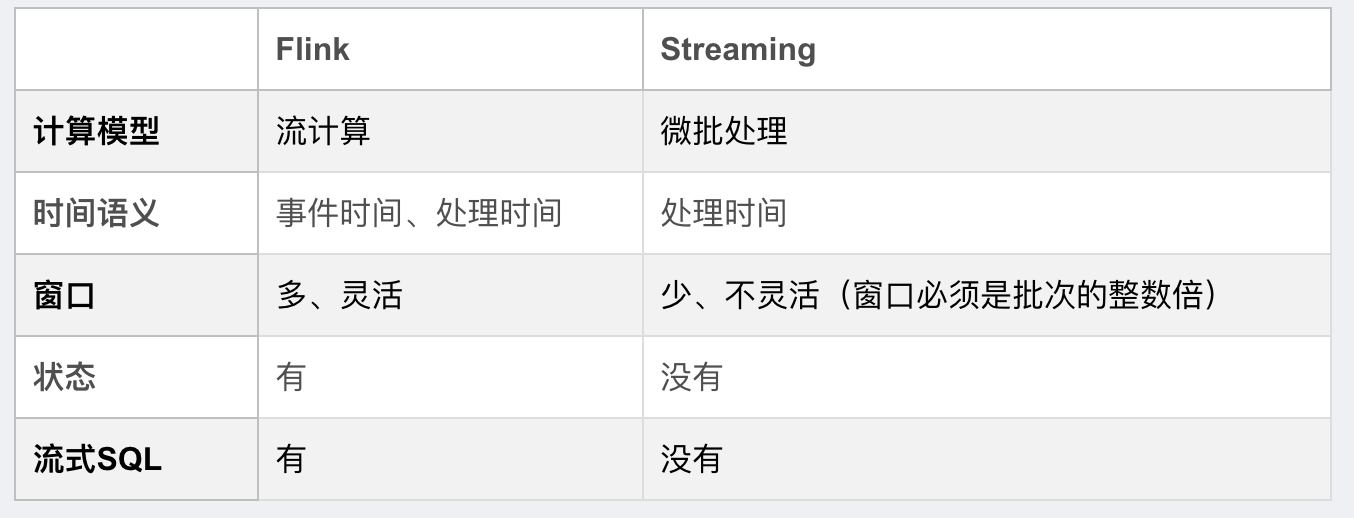
Flink和SparkStreaming
如果是批处理,可选择
Spark,如果是实时流处理,则选择Flink。
Flink的延迟是毫秒级别,而Spark Streaming的延迟是秒级延迟。