 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
数据驱动建模设计举例
假设有如下几张表:
order(订单)和order_detail(订单明细)product(商品)和product_comment(商品评论)正常来说,从表的设计看,能知道:
order与order_detail之间肯定是一对多的关系。
product与product_comment之间肯定是一对多的关系。那么他们的关系实际是一样的吗?
需要深入到代码,才能够发现差异:
public class OrderService {
@Transactional
public void createOrder(Order order, List<OrderDetail> orderDetailList) throws Exception {
// 保存订单
// 保存订单详情
}
}
public class ProductService {
@Transactional
public void createProduct(Product product) throws Exception {
// 保存产品
}
}
订单和订单明细是一起保存的,也就是说两者可以作为一个整体来看待(聚合)
- 而产品和产品评论之间并不能被看做一个整体,所以没有在一起进行操作!
这层逻辑,只看表设计是看不出来的,只有看到代码了,才能理清这一层关系。
- 这无形中就增加了理解和使用难度。
聚合就是解决这种问题的一种方法!
架构与代码的差异
《程序员必读之软件架构》中有这么一段话:
很多人以组件来谈论软件系统,然而代码通常并未反映出这种结构。
这就是软件架构和依据原则编码之间会脱节的原因之一。
- 简单说就是:墙上的架构图说的是一回事,代码说的却是另一回事。
这也是架构与代码差异的一个原因。
还有一个原因就是某些约束没有在设计中体现出来,而这些约束需要阅读代码才能够知道。
- 这就增加了理解和使用这个组件的难度。
这个问题在基于数据建模的设计方法上比较明显。
形象化举例:
聚合前:
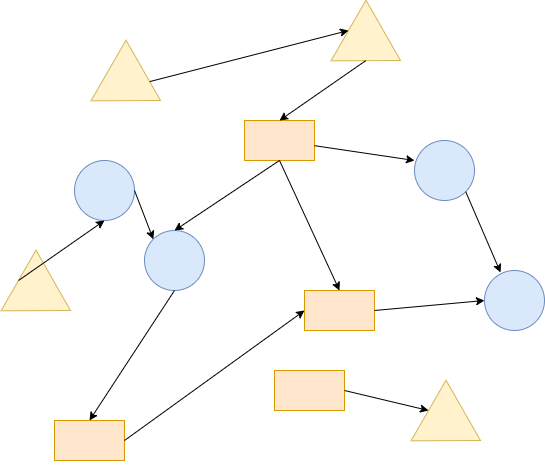 聚合后:
聚合后:
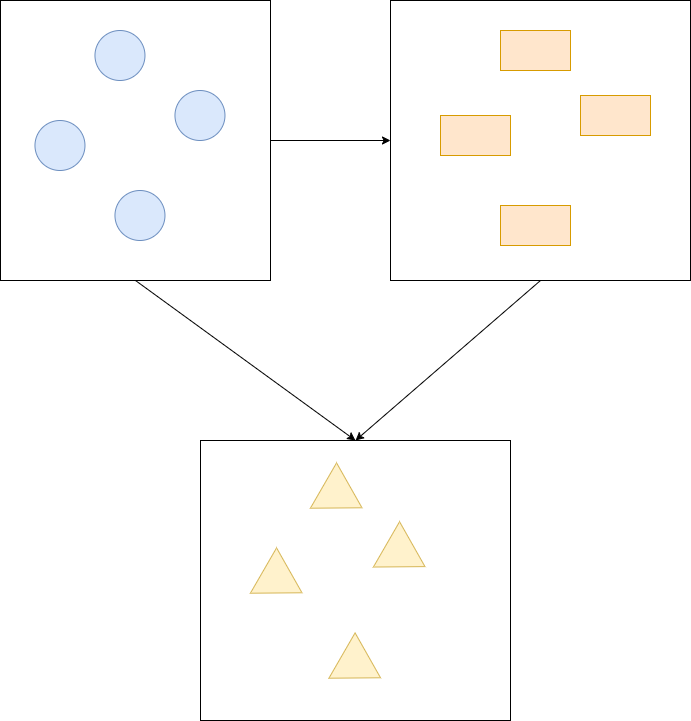
什么是聚合和聚合根
一段代码:
public class Test {
public void test() {
System.out.println("test1");
System.out.println("test2");
}
}
上面的代码,我们如何保障在多线程情况下1和2能按顺序打印出来?
最简单的方法就是使用
synchronized关键字进行加锁操作。
public class Test {
public synchronized void test() {
System.out.println("test1");
System.out.println("test2");
}
}
synchronized保证了代码的原子性执行。如果说,
synchronized是多线程层面的锁。
- 事务是数据库层面的锁,那么 聚合 可以理解为业务层面的锁。
在业务逻辑上,有些对象需要保持操作上的原子性,否则就没有任何意义。
- 这些对象就组成了聚合。
比如上面的订单与订单详情,从业务上来看,订单与订单明细需要保持业务上的原子性操作:
- 订单必须要包含订单明细。
- 订单明细必须要属于某个订单。
- 订单和订单明细被视为一个整体,少了任何一个都没有意义。
所以:
订单和订单明细组成一个 聚合
订单是操作的主体,所以订单是这个 聚合 的 聚合根
所有对这个 聚合 的操作,只能通过 聚合根 进行
而产品和产品评价就不构成聚合。
- 虽然在表设计时,订单和订单明细的结构关系与产品与产品评价的结构关系是一样的。
因为:
- 虽然产品评价需要属于某个产品。
- 但是产品不一定就有产品评价。
- 产品评价可以独立操作。
产品和产品评论是两个聚合
- 产品评论通过
productId与产品聚合进行关联
如何确定聚合和聚合根
对象在业务逻辑上是否需要保证原子性操作是确定聚合和聚合根的其中一个约束。
还有一个约束就是 边界,即聚合多大才合适?
- 过大的 聚合 会带来各种问题。
比如下面代码:
public class Test {
public synchronized void test() {
System.out.println("test1");
System.out.println("test2");
System.out.println("test3");
System.out.println("test4");
}
}
如果只希望1,2能按顺序打印出来,而3和4没有这个要求。
上面的代码能满足要求,但是影响了性能。
- 优化方式是使用同步块,缩小同步范围。
public class Test {
public void test() {
synchronized(Test.class) {
System.out.println("test1");
System.out.println("test2");
}
System.out.println("test3");
System.out.println("test4");
}
}
边界就像上面的同步块一样,只将需要的对象组合成聚合。
假设上面的产品和产品评论构成了一个聚合。
那会发生什么事情呢?
当A,B两个用户同时对这个商品进行评论,A先开始评论,此时就会锁定该产品对象以及下面的所有评论。
- 在A提交评论之前,B是无法操作这个产品对象的,显然这是不合理的。
如何设计聚合
假设是一个订单管理系统。
- 订单(
Order)聚合是一个典型的聚合根。步骤如下:
确定聚合的边界:
- 订单聚合包含订单、订单明细(
Order Detail)和订单支付(Order Payment)等实体和值对象。确定聚合根:
- 在订单聚合中,订单(
Order)被选为聚合根。定义聚合的属性和行为:
- 订单聚合可以有属性如订单号、订单日期、订单状态等,行为如修改订单状态、添加订单明细等。
聚合设计的原则
聚合是用来封装真正的不变性,而不是简单的将对象组合在一起。
聚合应尽量设计的小。
聚合之间的关联通过聚合根ID,而不是对象引用。
聚合内强一致性,聚合之间最终一致性。
参考资料
- 《领域驱动设计:软件核心复杂性应对之道》
- 《实现领域驱动设计》