 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
Hadoop是Apache软件基金会下一个开源分布式计算平台。
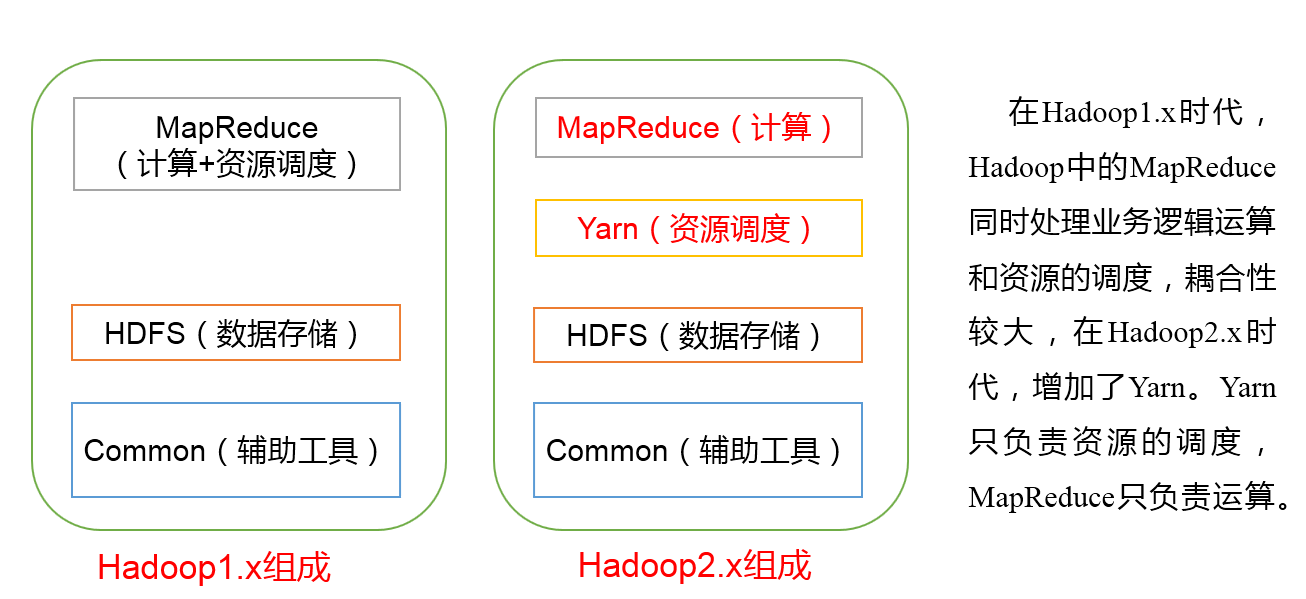
以HDFS、MapReduce,Hadoop2.0加入了YARN,Yarn是资源调度框架,能够细粒度的管理和调度任务。
- 还能够支持其他的计算框架,比如Spark为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
HDFS的高容错性、高伸缩性、高效性等优点让用户可以将Hadoop部署在低廉的硬件上,形成分布式系统。
Hadoop发行版本
Apache Hadoop发行版:
DKhadoop发行版:
Cloudera发行版:
官方地址:https://www.cloudera.com/products/open-source/apache-hadoop.html
Hortonworks发行版:
Hadoop2.x
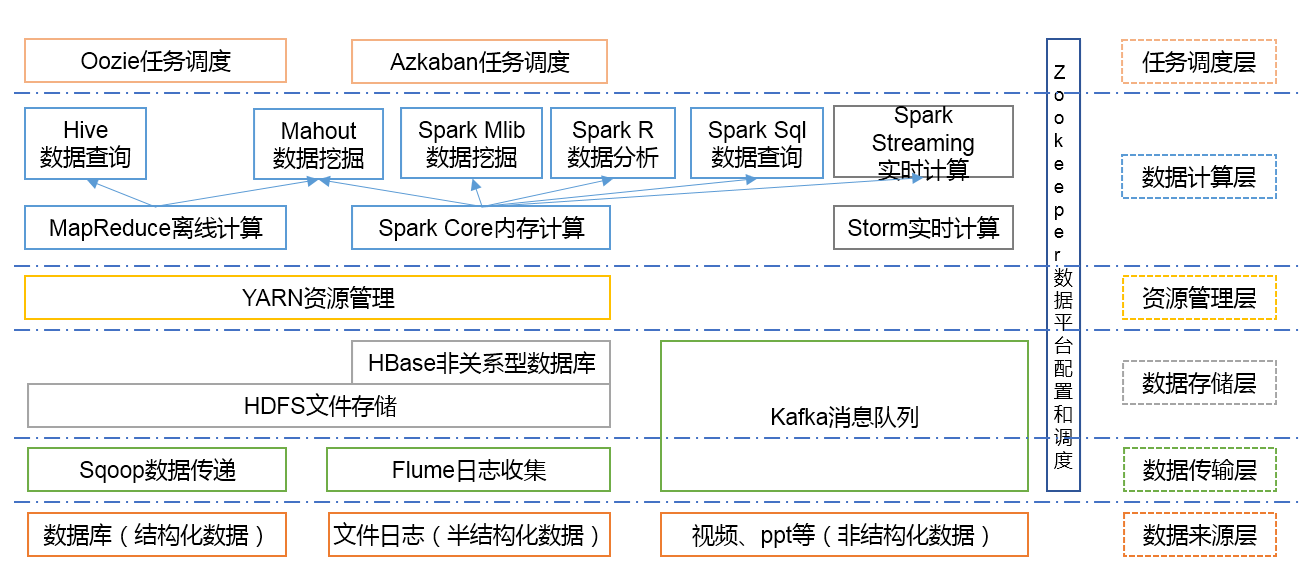
生态系统
HDFS
- Hadoop分布式文件系统,运行于大型商用机器集群,可实现分布式存储。
MapReduce
- 并行计算框架,基于其写出来的应用程序能够运行在由上千个商用机器组成的大型集群上。
- 以一种可靠容错的方式并行处理T级别及以上的数据集。
Yarn
- 一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。
- 它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Spark
- 通用内存并行计算框架,借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷。
Storm
- Storm用于连续计算,对数据流做连续查询,在计算时就将结果以流的形式输出给用户,如今已被Flink替代。
Flink
- 一个面向数据流处理和批量数据处理的可分布式的开源计算框架。
- 它基于同一个Flink流式执行模型,能够支持流处理和批处理两种应用类型。
Flume
- 一个可用的、可靠的、分布式的海量日志采集、聚合和传输系统。
Hive
- 提供简单的数据操作而设计的分布式数据仓库,它提供了简单的类似SQL语法的HiveQL语言进行数据查询。
Zookeeper
- 分布式协调系统,是高可用的和可靠的分布式协同系统,提供分布式锁之类的基本服务,用于构建分布式应用。
HBase
- 基于Hadoop的分布式数据库。
- 是一个有序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储到各个计算节点上。
CloudBase
- 基于Hadoop的数据仓库,支持标准的SQL语法进行数据查询。
Pig
- 大数据流处理系统,建立于Hadoop之上为并行计算环境提供了一套数据工作流语言和执行框架。
Mahout
- 基于HadoopMapReduce的大规模数据挖掘与机器学习算法库。
Oozie
- MapReduce工作流管理系统。
SQOOP
- 数据转移系统,是一个用来将Hadoop和关系型数据库中的数据相互转移的工具。
- 可以将一个关系型数据库中的数据导入Hadoop的HDFS中,也可以将HDFS的数据导入关系型数据库中。
Scribe
- Facebook开源的日志收集聚合框架系统。