支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
Apache Sqoop(SQL-To-Hadoop)项目旨在协助RDBMS(Relational Database Management System:关系型数据库管理系统)与Hadoop之间进行高效的大数据交流。
用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中。
同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。
Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。
在特定场景下,抽取过程会有很大的性能提升。
官方文档:https://sqoop.apache.org/docs/1.99.7/index.html
主要特点
可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中。
Sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduce作业,在hadoop集群中运行。
采用map-reduce框架同时在多个节点进行import或者export操作,速度比单节点运行多个并行导入导出效率高,同时提供了良好的并发性和容错性。
支持insert、update模式,可以选择参数,若内容存在就更新,若不存在就插入。
对国外的主流关系型数据库支持性更好。
基本架构
sqoop的底层实现是mapreduce,所以sqoop依赖于hadoop,sqoop将导入或导出命令翻译成MapReduce程序来实现,在翻译出的MapReduce 中主要是对InputFormat和OutputFormat进行定制。
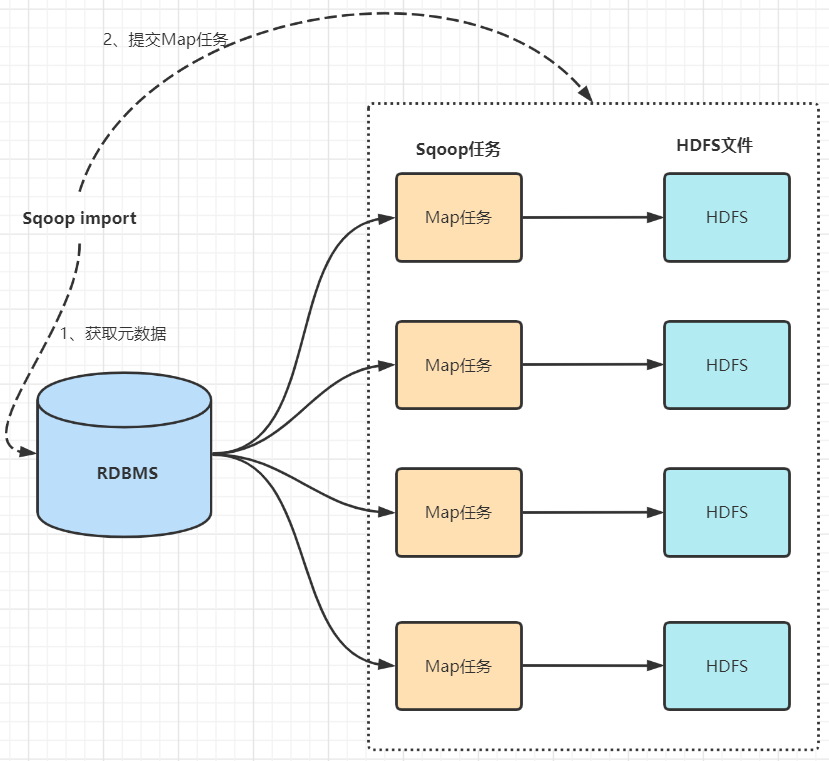
数据导入(RDBMS->Haoop)
sqoop会通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型。
这些数据库的数据类型会被映射成为java的数据类型,根据这些信息,sqoop会生成一个与表名相同的类用来完成序列化工作,保存表中的每一行记录。
sqoop开启MapReduce作业。
启动的作业在input的过程中,会通过jdbc读取数据表中的内容,这时,会使用sqoop生成的类进行序列化。
最后将这些记录写到hdfs上,在写入hdfs的过程中,同样会使用sqoop生成的类进行反序列化。
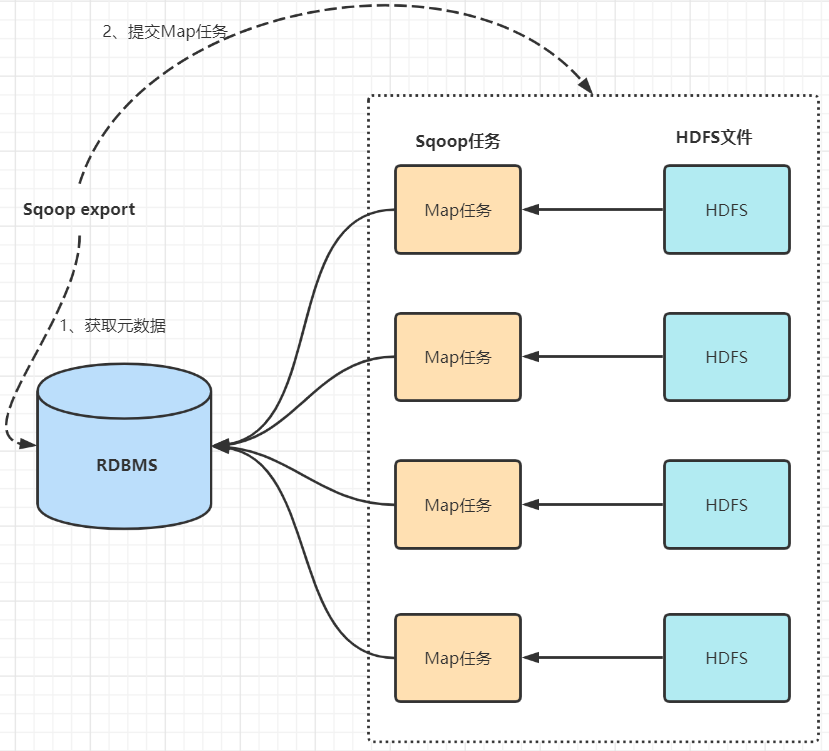
数据导出(Haoop->RDBMS)
首先sqoop通过jdbc访问关系型数据库获取需要导出的信息的元数据信息。
根据获取的元数据信息,sqoop生成一个Java类,用来承载数据的传输,该类必须实现序列化。
启动MapReduce程序。
sqoop利用生成的这个类,并行从hdfs中获取数据。
每个map作业都会根据读取到的导出表的元数据信息和读取到的数据,生成一批insert 语句,然后多个map作业会并行的向MySQL中插入数据。