 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}

Apache Spark是用于大规模数据处理的统一分析引擎。基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性。
允许用户将
Spark部署在大量硬件之上,形成集群。文档查看地址:https://spark.apache.org/docs/3.3.0/
下载地址:
Spark和Hadoop
Spark 并不能完全替代 Hadoop,Spark 主要用于替代Hadoop中的
MapReduce计算模型。存储依然可以使用
HDFS,但是中间结果可以存放在内存中。调度可以使用 Spark 内置的,也可以使用更成熟的调度系统
YARN等。Spark 已经很好地融入了 Hadoop 生态圈,它可以借助于
YARN实现资源调度管理,借助于HDFS实现分布式存储。Hadoop 可以使用廉价的、异构的机器来做分布式存储与计算,但 Spark 对硬件的要求稍高一些,对内存与 CPU 有一定的要求。
| Hadoop | Spark | |
|---|---|---|
| 类型 | 分布式基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD 组成 DAG 有向无环图, API 较为顶层, 方便使用 |
| 数据存储结构 | MapReduce 中间计算结果存在 HDFS 磁盘上, 延迟大 | RDD 中间运算结果存在内存中 , 延迟小 |
| 运行方式 | Task 以进程方式维护, 任务启动慢 | Task 以线程方式维护, 任务启动快 |
生态圈
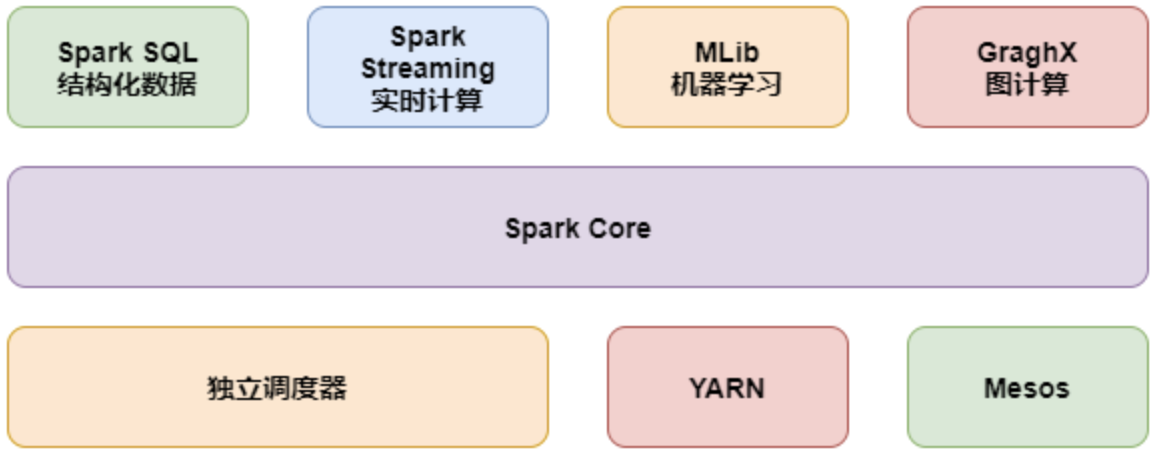
Spark Core:
- 实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:
- Spark 用来操作结构化数据的程序包。
- 通过 Spark SQL,可以使用 SQL 操作数据。
Spark Streaming:
- Spark 提供的对实时数据进行流式计算的组件,提供了用来操作数据流的 API。
Spark MLlib:
- 提供常见的机器学习(ML)功能的程序库。
- 包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):
- Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:
- Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:
- 处理结构化流,统一了离线和实时的 API。
Spark为什么会流行
优秀的数据模型和丰富计算抽象:
Spark 产生之前,已经有
MapReduce这类非常成熟的计算系统存在了,并提供了高层次的 API。
- 把计算运行在集群中并提供容错能力,从而实现分布式计算。
虽然 MapReduce 提供了对数据访问和计算的抽象。
但是对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中(例如 HDFS)。
- 所以会产生数据的复制备份,磁盘的 I/O 以及数据的序列化。
所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。
而这类操作是非常常见的,例如迭代式计算,交互式数据挖掘,图计算等。
学术界的 AMPLab 提出了一个新的模型,叫做 RDD。
RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单)。
它可以让用户显式的将中间结果数据集保存在内存中,并且通过控制数据集的分区来达到数据存放处理最优化。
- 同时 RDD 也提供了丰富的 API 来操作数据集。
后来 RDD 被 AMPLab 在一个叫做 Spark 的框架中提供并开源。
简而言之,Spark 借鉴了
MapReduce思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度。
Spark特点
与 Hadoop 的
MapReduce相比,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。
- Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。
Spark 支持 Java、Python、R 和 Scala 的 API,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。
而且 Spark 支持交互式的 Python 和 Scala 的 Shell,可以非常方便地在这些 Shell 中使用 Spark 集群来验证解决问题的方法。
Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
Spark 可以非常方便地与其他的开源产品进行融合。
比如,Spark 可以使用
Hadoop的 YARN 和 Apache Mesos 作为它的资源管理和调度器。并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。
Spark 也可以不依赖于第三方的资源管理和调度器,它实现了
Standalone作为其内置的资源管理和调度框架。
- 这样进一步降低了 Spark 的使用门槛,使得所有人都可以非常容易地部署和使用 Spark。
此外,Spark 还提供了在 EC2 上部署 Standalone 的 Spark 集群的工具。
运行流程
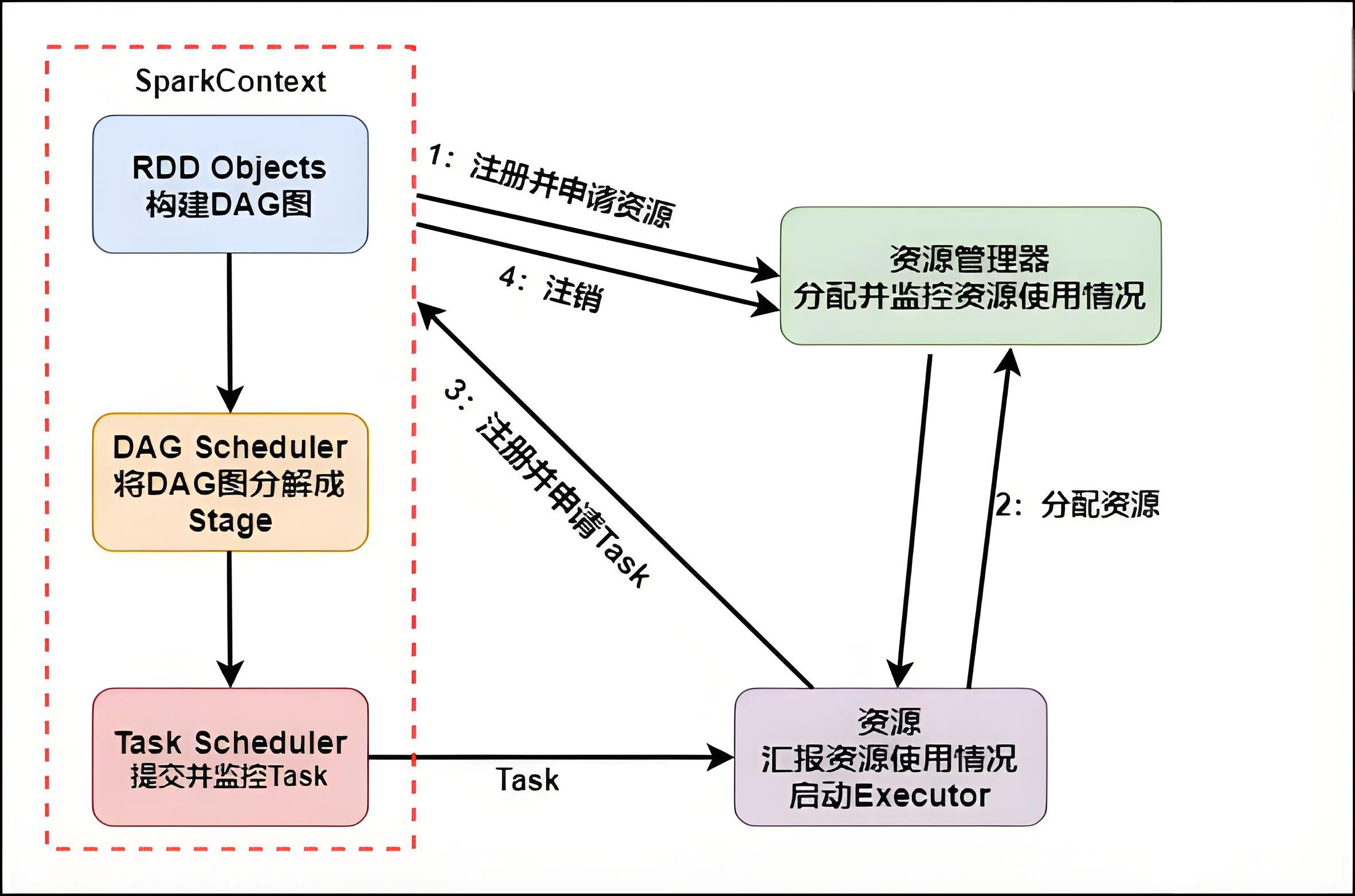
具体运行流程如下:
SparkContext向资源管理器注册并向资源管理器申请运行Executor。资源管理器分配
Executor,然后资源管理器启动Executor。
Executor发送心跳至资源管理器。
SparkContext构建DAG有向无环图。将
DAG分解成Stage(TaskSet)。把
Stage发送给TaskScheduler。
Executor向SparkContext申请Task。
TaskScheduler将Task发送给Executor运行。同时
SparkContext将应用程序代码发放给Executor。
Task在Executor上运行,运行完毕释放所有资源。
任务总体调度
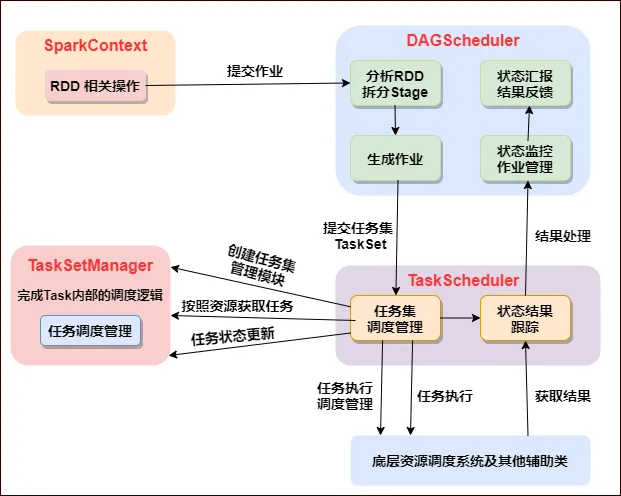
Executor进程专属
每个
Application获取专属的Executor进程,该进程在Application期间一直驻留,并以多线程方式运行Tasks。
Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
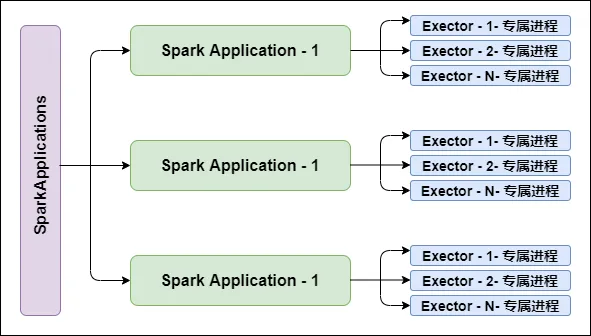
支持多种资源管理器
Spark与资源管理器无关,只要能够获取Executor进程,并能保持相互通信就可以了。
Spark支持资源管理器包含:Standalone、On Mesos、On YARN、Or On EC2。
Job提交就近原则
提交
SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack(机架)里。因为
Spark Application运行过程中SparkContext和Executor之间有大量的信息交换。如果想在远程集群中运行,最好使用
RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
移动程序而非移动数据的原则执行
移动程序而非移动数据的原则执行,
Task采用了数据本地性和推测执行的优化机制。
运行模式
Spark集群分为两种模式:单机模式与集群模式。
Local模式:
- 在本地部署单个Spark服务。
Standalone模式:
- Spark自带的任务调度模式(国内常用)。
YARN模式:
- Spark使用Hadoop的YARN组件进行资源与任务调度(国内最常用)。
Mesos模式:
- Spark使用Mesos平台进行资源与任务的调度(国内很少用)。
RDD
为什么要有 RDD?
在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果。
- 即一个阶段的输出结果会作为下一个阶段的输入。
但是,之前的
MapReduce框架采用非循环式的数据流模型,把中间结果写入到 HDFS 中。
- 带来了大量的数据复制、磁盘 IO 和序列化开销。
且这些框架只能支持一些特定的计算模式(
Map/Reduce),并没有提供一种通用的数据抽象。RDD 提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性。
只需将具体的应用逻辑表达为一系列转换操作(函数),不同 RDD 之间的转换操作之间还可以形成依赖关系,进而实现管道化。
从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销,并且还提供了更多的 API。
RDD 是什么?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象。
代表一个不可变、可分区、里面的元素可并行计算的集合。
单词拆解:
- Resilient :它是弹性的,RDD 里面的中的数据可以保存在内存中或者磁盘里面。
- Distributed :它里面的元素是分布式存储的,可以用于分布式计算。
- Dataset:它是一个集合,可以存放很多元素。
Spark SQL
Hive 和 SparkSQL
Hive 是将 SQL 转为 MapReduce。
SparkSQL 可以理解成是将 SQL 解析成:RDD + 优化 再执行。
Spark Streaming
Spark Streaming 是一个基于 Spark Core 之上的实时计算框架。
可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点。