 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库。
是一款同时支持在线事务处理与在线分析处理的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。
目标是为用户提供一站式 OLTP、OLAP、HTAP 解决方案。
TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
- OLTP:
- 强调支持短时间内大量并发的事务操作(增删改查)能力。
- 每个操作涉及的数据量都很小(比如几十到几百字节)。
- 强调事务的强一致性。
- OLAP:
- 偏向于复杂的只读查询,读取海量数据进行分析计算,查询时间往往较长。
更详细的文档可以参考TiDB官网:https://docs.pingcap.com/zh/tidb/dev/overview
与传统的单机数据库相比,TiDB 具有以下优势:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
五大核心特性
TiDB 具备如下众多特性,其中两大核心特性为:水平扩展与高可用。
一键水平扩容或者缩容:
- 得益于 TiDB 存储计算分离的架构的设计,可按需对计算、存储分别进行在线扩容或者缩容,扩容或者缩容过程中对应用运维人员透明。通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
金融级高可用:
- 数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。
- 可按需配置副本地理位置、副本数量等策略满足不同容灾级别的要求。相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
实时 HTAP:
- 提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。
- TiKV、TiFlash 可按需部署在不同的机器,解决 HTAP 资源隔离的问题。
云原生的分布式数据库:
- TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,配合 TiDB Operator 项目 可实现自动化运维,使部署、配置和维护变得十分简单。
兼容 MySQL 5.7 协议和 MySQL ⽣态:
- 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
- 对于用户使用的时候,可以透明地从MySQL切换到TiDB 中,只是”新MySQL”的后端是存储”无限的”,不再受制于Local的磁盘容量。
- 在运维使用时也可以将TiDB当做一个从库挂到MySQL主从架构中。
分布式数据库好处
分布式数据库自带高可用、可扩展的属性,数据量大了、流量高了,只需要加机器就可以实现横向扩展,对业务端透明。
整体架构
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。
对应的架构图如下:
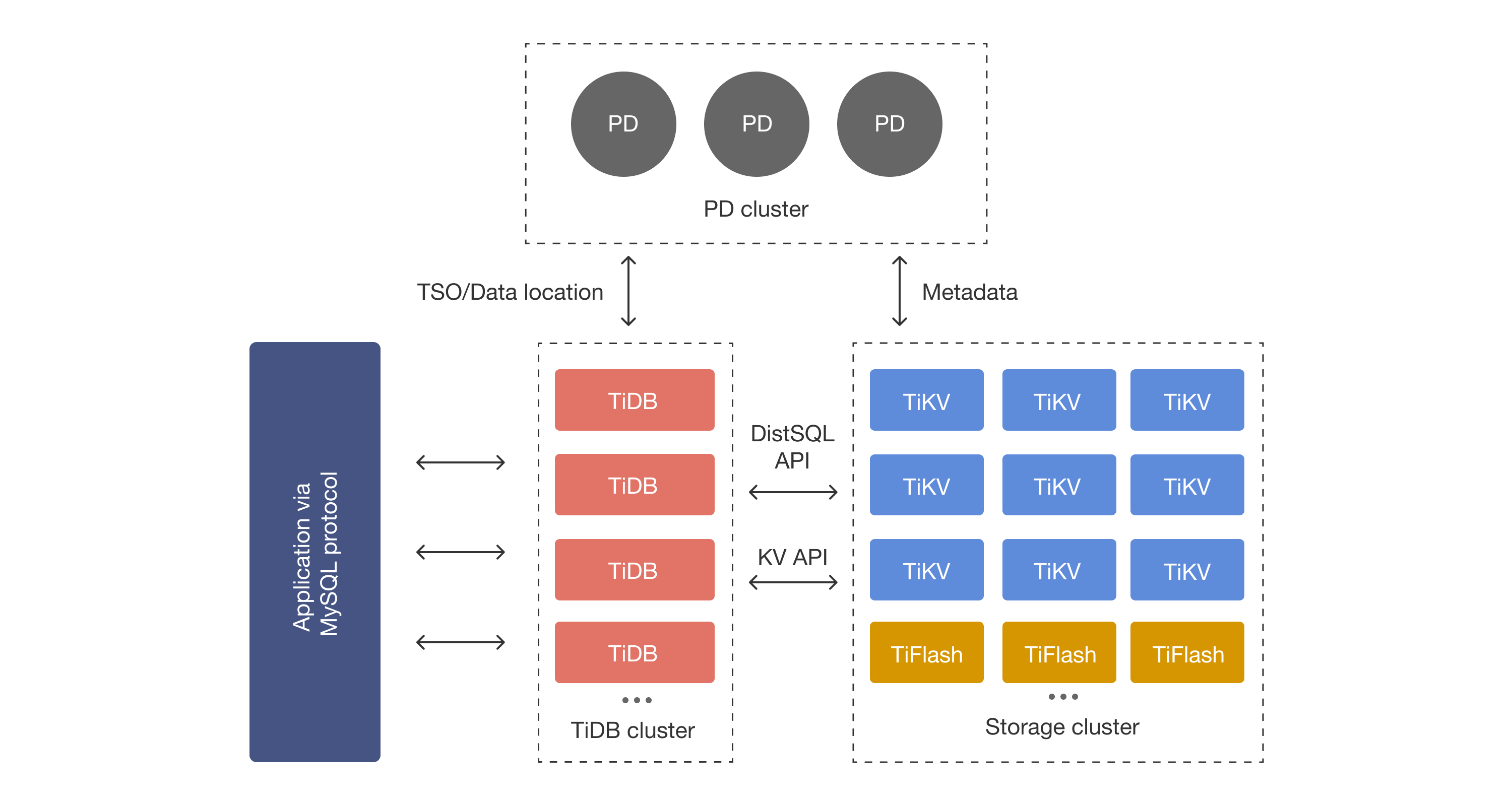
Application via mysql protocol:
- 客户端使用 mysql 协议发出 SQL 请求。
TiDB Server(TIDB cluster):SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的”大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。
建议部署奇数个 PD 节点。(即每条SQL具体在哪个存储节点执行是由 PD 决定的)
存储节点:
TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。
TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。
TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。
所以,数据都存储在 TiKV 中。另外,TiKV 每个节点中的数据都会自动维护多副本(即在不同的region里。默认为三副本,主副本加起来三份,即实际每份数据都会存三份),天然支持高可用和自动故障转移。
TiFlash:TiFlash 是一类特殊的存储节点。
- 和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
Region:是Tikv存储数据的基本单位(也是节点间同步数据的最小单位,Region实际上是一个逻辑上的单位),每个Region承载一段特定的数据,并分布在TiKV集群的不同节点上。
Region的ID、范围、所在的节点信息等元信息会存储在PD中,TiKV Client通过查询PD获取Region的元信息,从而确定数据所在的节点。
TIDB行记录映射到KV
每行数据按照一定规则进行编码成 key-value 形式,key 格式:t + tableId + _ + r + rowID
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1,col2,col3,col4]

怎么迁移MySQL的数据到TiDB
TiDB提供了专门迁移数据的工具DM,https://docs.pingcap.com/zh/tidb/stable/dm-overview。
该工具可以实现全量+增量的数据同步,数据延迟与MySQL集群间的延迟相当,在毫秒级别。
除了一些写后读的场景外,其他场景几乎感知不到数据的延迟。
使用DM数据同步功能需要注意什么
- 数据同步过程中,如果源库的DML操作非常频繁、或者有大事务,可能会造成TiDB和源库间的数据延迟,当然,MySQL集群内部的节点也可能会出现数据延迟。
- 所以,建议MySQL源库的写操作最好不要高于5K QPS。
- TiDB的DDL操作都是Online DDL,且都是异步的,其中增减字段可以秒级完成,但增加索引时,由于要回填索引数据,这个过程会非常长。
- 所以在同步场景中,源库MySQL已经增加索引完成,但在TiDB中看不到这个索引,业务使用上有可能会造成一些困扰。
- 解决方法是可以配置不同步索引修改,单独在TiDB中手动操作。
- 分库分表合并场景中,源库MySQL分表的结构修改,要在所有分表执行一遍,同步到TiDB中,就会有很多个相同的表结构修改语句,如果TiDB设置的是悲观模式,就要等待所有分表都修改完表结构,TiDB再进行修改,这个过程中就出现了数据延迟。
- 解决方案是如果满足乐观模式,就配置乐观模式的同步,即在第一个分表修改后,TiDB就进行表结构修改。
- 悲观模式和乐观模式的区别,参考:https://docs.pingcap.com/zh/tidb/stable/feature-shard-merge。
误删了数据怎么找回
TiDB提供了Stale Read 功能,可以读取一周内任意时刻的数据(历史数据一般保留一周,可按需调整),在查询中设置一个TIMESTAMP,就可以读取该TIMESTAMP的数据了,同时也支持导出,为误删数据的找回提供了方便。
具体实现和使用方法参考:https://docs.pingcap.com/zh/tidb/stable/as-of-timestamp