 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
专栏链接:https://kaiwu.lagou.com/course/courseInfo.htm?courseId=536
基础入门
Go语言优势
语法简洁,相比其他语言更容易上手
- 开发效率更高
自带垃圾回收(
GC),不用再手动申请释放内存
- 能够有效避免
Bug,提高性能语言层面的并发支持
- 让你很容易开发出高性能的程序
提供的标准库强大,第三方库也足够丰富
- 可以拿来即用,提高开发效率
可通过静态编译直接生成一个可执行文件,运行时不依赖其他库
- 部署方便,可伸缩能力强
提供跨平台支持
- 很容易编译出跨各个系统平台直接运行的程序
Java虽然具备垃圾回收功能,但它是解释型语言
- 需要安装
JVM虚拟机才能运行
C语言虽然不用解释,可以直接编译运行,但是它不具备垃圾回收功能
- 需要开发者自己管理内存的申请和释放,容易出问题
而
Go语言具备了两者的优势
微服务和云原生已经成为一种趋势,而 Go 作为一款高性能的编译型语言
- 最适合承载落地微服务的实现
又容易生成跨平台的可执行文件,相比其他编程语言更容易部署在
Docker容器中
- 实现灵活的自动伸缩服务
第一个Go语言程序
package main
import "fmt"
func main() {
fmt.Println("Hello, 世界")
}
$ go run ch01/main.go
Hello, 世界
代码中的
go是一个Go语言开发工具包提供的命令
它和平时常用的
ls命令一样都是可执行的命令它可以帮助运行
Go语言代码,并进行编译,生成可执行的二进制文件等run 在这里是
go命令的子命令,表示要运行 Go 语言代码的意思
第一行的 package main
代表当前的
ch01/main.go文件属于哪个包
- 其中 package 是 Go 语言声明包的关键字,main 是要声明的包名
在 Go 语言中
main包是一个特殊的包
- 代表你的 Go 语言项目是一个可运行的应用程序,而不是一个被其他项目引用的库
第二行的 import fmt
- 是导入一个 fmt 包,其中 import 是 Go 语言的关键字,表示导入包的意思
- 这里导入的是
fmt包,导入的目的是要使用它第三行的 func main()
是定义了一个函数,其中 func 是 Go 语言的关键字,表示要定义一个函数或者方法的意思
main是函数名,() 空括号表示这个 main 函数不接受任何参数在 Go 语言中 main 函数是一个特殊的函数,它代表整个程序的入口
- 也就是程序在运行的时候,会先调用
main函数- 然后通过 main 函数再调用其他函数,达到实现项目业务需求的目的
第四行的 fmt.Println(“Hello, 世界”)
是通过 fmt 包的 Println 函数打印 Hello, 世界 这段文本
- 其中
fmt是刚刚导入的包,要想使用一个包,必须先导入Println 函数是属于包 fmt 的函数,这里我需要它打印输出一段文本,也就是
Hello, 世界第五行的大括号 }
- 表示 main 函数体的结束
语言环境搭建
先下载 Go 语言开发包
可以从官网 https://golang.org/dl/ 和 https://golang.google.cn/dl/ 下载
- 第一个链接是国外的官网,第二个是国内的官网,如果第一个访问不了,可以从第二个下载
安装测试
可以打开终端或者命令提示符,输入
go version来验证 Go 语言开发工具包是否安装成功
- 如果成功的话,会打印出
Go语言的版本和系统信息
环境变量设置
GOPATH:
- 代表 Go 语言项目的工作目录,在
Go Module模式之前非常重要
- 现在基本上用来存放使用
go get命令获取的项目GOBIN:
- 代表 Go 编译生成的程序的安装目录
- 比如通过
go install命令
- 会把生成的 Go 程序安装到 GOBIN 目录下,以供你在终端使用
假设工作目录为
/Users/flysnow/go
- 你需要把 GOPATH 环境变量设置为
/Users/flysnow/go
- 把 GOBIN 环境变量设置为
$GOPATH/bin
项目结构
采用
Go Module的方式,可以在任何位置创建你的 Go 语言项目。
假设你的项目位置是
/Users/flysnow/git/gotour
- 打开终端,输入如下命令切换到该目录下:
$ cd /Users/flysnow/git/gotour
然后再执行如下命令创建一个
Go Module项目:
$ go mod init
执行成功后,会生成一个
go.mod文件。然后在当前目录下创建一个
main.go文件,这样整个项目目录结构是:
gotour
├── go.mod
├── lib
└── main.go
其中
main.go是整个项目的入口文件,里面有main函数。lib 目录是项目的子模块,根据项目需求可以新建很多个目录作为子模块
- 也可以继续嵌套为子模块的子模块。
编译发布
可以编译生成可执行文件
- 也可以把它发布到
$GOBIN目录,以供在终端使用。在项目根目录输入以下命令,即可编译一个可执行文件。
$ go build ./ch01/main.go
回车执行后会在当前目录生成
main可执行文件。
$ ./main
Hello, 世界
如果成功打印出
Hello, 世界,证明程序成功生成。以上生成的可执行文件在当前目录
- 也可以把它安装到
$GOBIN目录或者任意位置,如下所示:
$ go install ./ch01/main.go
使用
go install命令即可,现在你在任意时刻打开终端
- 输入 main 回车,都会打印出
Hello, 世界。
跨平台编译
Go 语言通过两个环境变量来控制跨平台编译,它们分别是
GOOS和GOARCH。
GOOS:代表要编译的目标操作系统
- 常见的有 Linux、Windows、Darwin 等。
GOARCH:代表要编译的目标处理器架构
- 常见的有 386、AMD64、ARM64 等。
这样通过组合不同的 GOOS 和 GOARCH
- 就可以编译出不同的可执行程序。
比如操作系统是 macOS AMD64 的,想编译出 Linux AMD64 的可执行程序
- 只需要执行
go build命令即可,如以下代码所示:
$ GOOS=linux GOARCH=amd64 go build ./ch01/main.go
编辑器推荐
第一款是 Visual Studio Code + Go 扩展插件
- 通过官方网站 https://code.visualstudio.com/ 下载使用。
第二款是老牌 IDE 公司 JetBrains 推出的 Goland,所有插件已经全部集成
- 更容易上手,并且功能强大,新手老手都适合
- 可以通过官方网站 https://www.jetbrains.com/go/ 下载使用。
数据类型
变量声明
在 Go 语言中,通过
var声明语句来定义一个变量定义的时候需要指定这个变量的类型,然后再为它起个名字,并且设置好变量的初始值。
所以
var声明一个变量的格式如下:
var 变量名 类型 = 表达式
package main
import "fmt"
func main() {
var i int = 10
fmt.Println(i)
}
其中
var i int = 10就是定义一个类型为 int(整数)
- 变量名为 i 的变量,它的初始值为 10。
Go 语言中定义的变量必须使用,否则无法编译通过
- 防止定义了变量不使用,导致浪费内存的情况;
Go 语言具有类型推导功能,所以也可以不去刻意地指定变量的类型
- 而是让 Go 语言自己推导,比如变量 i 也可以用如下的方式声明:
var i = 10
这样变量 i 的类型默认是 int 类型。
你也可以一次声明多个变量,把要声明的多个变量放到一个括号中即可
如下面的代码所示:
var (
j int= 0
k int= 1
)
同理因为类型推导,以上多个变量声明也可以用以下代码的方式书写:
var (
j = 0
k = 1
)
整型
在 Go 语言中,整型分为:
- 有符号整型:如 int、int8、int16、int32 和 int64。
- 无符号整型:如 uint、uint8、uint16、uint32 和 uint64。
它们的差别在于,有符号整型表示的数值可以为负数、零和正数
- 而无符号整型只能为零和正数。
除了有用位(bit)大小表示的整型外,还有 int 和 uint 这两个没有具体 bit 大小的整型
- 它们的大小可能是 32bit,也可能是 64bit,和硬件设备 CPU 有关。
在整型中,如果能确定 int 的 bit 就选择比较明确的 int 类型
- 因为这会让你的程序具备很好的移植性。
在 Go 语言中,还有一种字节类型 byte,它其实等价于
uint8类型
- 可以理解为 uint8 类型的别名,用于定义一个字节,所以字节 byte 类型也属于整型。
浮点数
浮点数就代表现实中的小数。
Go 语言提供了两种精度的浮点数
- 分别是 float32 和 float64。
项目中最常用的是 float64
- 因为它的精度高,浮点计算的结果相比 float32 误差会更小。
var f32 float32 = 2.2
var f64 float64 = 10.3456
fmt.Println("f32 is",f32,",f64 is",f64)
$ go run ch02/main.go
f32 is 2.2 ,f64 is 10.3456
布尔型
一个布尔型的值只有两种:
- true 和 false,它们代表现实中的是和否。
Go 语言中的布尔型使用关键字 bool 定义。
var bf bool =false
var bt bool = true
fmt.Println("bf is",bf,",bt is",bt)
布尔值可以用于一元操作符 !,表示逻辑非的意思
- 也可以用于二元操作符
&&、||,它们分别表示逻辑和、逻辑或。
字符串
Go 语言中的字符串可以表示为任意的数据
比如以下代码,在 Go 语言中,字符串通过类型
string声明:
var s1 string = "Hello"
var s2 string = "世界"
fmt.Println("s1 is",s1,",s2 is",s2)
在 Go 语言中,可以通过操作符 + 把字符串连接起来,得到一个新的字符串
比如将上面的 s1 和 s2 连接起来,如下所示:
fmt.Println("s1+s2=",s1+s2)
字符串也可以通过 += 运算符操作。
零值
零值其实就是一个变量的默认值,在 Go 语言中,如果我们声明了一个变量,但是没有对其进行初始化
- 那么 Go 语言会自动初始化其值为对应类型的零值。
比如数字类的零值是 0,布尔型的零值是 false,字符串的零值是
“”空字符串等。
变量简短声明
借助类型推导,Go 语言提供了变量的简短声明 :=,结构如下:
变量名:=表达式
借助 Go 语言简短声明功能,变量声明就会非常简洁
比如以上示例中的变量,可以通过如下代码简短声明:
i:=10
bf:=false
s1:="Hello"
指针
在 Go 语言中,指针对应的是变量在内存中的存储位置
- 也就说指针的值就是变量的内存地址。
通过
&可以获取一个变量的地址,也就是指针。
在以下的代码中,pi 就是指向变量 i 的指针。
要想获得指针 pi 指向的变量值,通过
*pi这个表达式即可。
pi:=&i
fmt.Println(*pi)
常量的定义
下面的示例定义了一个常量 name,它的值是
飞雪无情。因为 Go 语言可以类型推导,所以在常量声明时也可以省略类型。
const name = "飞雪无情"
在 Go 语言中,只允许布尔型、字符串、数字类型这些基础类型作为常量。
iota
iota 是一个常量生成器,它可以用来初始化相似规则的常量,避免重复的初始化。
假设我们要定义 one、two、three 和 four 四个常量
- 对应的值分别是 1、2、3 和 4,如果不使用 iota,则需要按照如下代码的方式定义:
const(
one = 1
two = 2
three =3
four =4
)
以上声明都要初始化,会比较烦琐,因为这些常量是有规律的(连续的数字)
所以可以使用 iota 进行声明,如下所示:
const(
one = iota+1
two
three
four
)
fmt.Println(one,two,three,four)
会发现打印的值和上面初始化的一样,也是 1、2、3、4。
iota 的初始值是 0,它的能力就是在每一个有常量声明的行后面 +1
下面分解上面的常量:
one=(0)+1,这时候 iota 的值为 0,经过计算后,one 的值为 1。
two=(0+1)+1,这时候 iota 的值会 +1,变成了 1
- 经过计算后,two 的值为 2。
three=(0+1+1)+1,这时候 iota 的值会再 +1,变成了 2
- 经过计算后,three 的值为 3。
four=(0+1+1+1)+1,这时候 iota 的值会继续再 +1,变成了 3
- 经过计算后,four 的值为 4。
如果你定义更多的常量,就依次类推,其中 () 内的表达式
- 表示 iota 自身 +1 的过程。
字符串和数字互转
Go 语言是强类型的语言,也就是说不同类型的变量是无法相互使用和计算的
这也是为了保证Go 程序的健壮性
- 所以不同类型的变量在进行赋值或者计算前,需要先进行类型转换。
i2s:=strconv.Itoa(i)
s2i,err:=strconv.Atoi(i2s)
fmt.Println(i2s,s2i,err)
通过包 strconv 的 Itoa 函数可以把一个 int 类型转为 string
- Atoi 函数则用来把 string 转为 int。
同理对于浮点数、布尔型
- Go 语言提供了
strconv.ParseFloat、strconv.ParseBool、strconv.FormatFloat
- 和
strconv.FormatBool进行互转
对于数字类型之间,可以通过强制转换的方式,如以下代码所示:
i2f:=float64(i)
f2i:=int(f64)
fmt.Println(i2f,f2i)
这种使用方式比简单,采用类型(要转换的变量)格式即可。
采用强制转换的方式转换数字类型,可能会丢失一些精度
- 比如浮点型转为整型时,小数点部分会全部丢失。
把变量转换为相应的类型后,就可以对相同类型的变量进行各种表达式运算和赋值了。
Strings包
它是用于处理字符串的工具包,里面有很多常用的函数,帮助我们对字符串进行操作
- 比如查找字符串、去除字符串的空格、拆分字符串、判断字符串是否有某个前缀或者后缀等。
//判断s1的前缀是否是H
fmt.Println(strings.HasPrefix(s1,"H"))
//在s1中查找字符串o
fmt.Println(strings.Index(s1,"o"))
//把s1全部转为大写
fmt.Println(strings.ToUpper(s1))
控制结构
if条件语句
if语句是条件语句
- 它根据布尔值的表达式来决定选择哪个分支执行
如果表达式的值为 true
- 则 if 分支被执行
如果表达式的值为 false
- 则 else 分支被执行。
func main() {
i:=10
if i >10 {
fmt.Println("i>10")
} else {
fmt.Println("i<=10")
}
}
关于 if 条件语句的使用有一些规则:
if 后面的条件表达式不需要使用 ()
- 这和有些编程语言不一样,也更体现 Go 语言的简洁
每个条件分支(if 或者 else)中的大括号是必须的
- 哪怕大括号里只有一行代码
if 紧跟的大括号 { 不能独占一行,else 前的大括号 } 也不能独占一行
- 否则会编译不通过
在
if……else条件语句中还可以增加多个else if,增加更多的条件分支。
func main() {
i:=6
if i >10 {
fmt.Println("i>10")
} else if i>5 && i<=10 {
fmt.Println("5<i<=10")
} else {
fmt.Println("i<=5")
}
}
和其他编程语言不同,在 Go 语言的 if 语句中,可以有一个简单的表达式语句
- 并将该语句和条件语句使用分号
;分开
func main() {
if i:=6; i >10 {
fmt.Println("i>10")
} else if i>5 && i<=10 {
fmt.Println("5<i<=10")
} else {
fmt.Println("i<=5")
}
}
在 if 关键字之后,i>10 条件语句之前
- 通过分号
;分隔被初始化的 i:=6。这个简单语句主要用来在 if 条件判断之前做一些初始化工作
- 可以发现输出结果是一样的。
switch选择语句
switch i:=6;{
case i>10:
fmt.Println("i>10")
case i>5 && i<=10:
fmt.Println("5<i<=10")
default:
fmt.Println("i<=5")
}
switch 语句同样也可以用一个简单的语句来做初始化
- 同样也是用分号
;分隔。每一个 case 就是一个分支,分支条件为 true 该分支才会执行
- 而且 case 分支后的条件表达式也不用小括号 () 包裹。
在 Go 语言中,switch 的 case 从上到下逐一进行判断
- 一旦满足条件,立即执行对应的分支并返回,其余分支不再做判断。
也就是说 Go 语言的 switch 在默认情况下,case 最后自带 break。
这和其他编程语言不一样
- 比如 C 语言在 case 分支里必须要有明确的 break 才能退出一个 case。
Go 语言的这种设计就是为了防止忘记写
break时,下一个 case 被执行。
那么如果有需要,的确需要执行下一个紧跟的 case 怎么办呢?
- Go 语言提供了
fallthrough关键字。现在看个例子,如下面的代码所示:
switch j:=1;j {
case 1:
fallthrough
case 2:
fmt.Println("1")
default:
fmt.Println("没有匹配")
}
以上示例运行会输出 1,如果省略 case 1
- 后面的
fallthrough,则不会有任何输出。
当 switch 之后有表达式时,case 后的值就要和这个表达式的结果类型相同
- 比如这里的 j 是 int 类型,那么 case 后就只能使用 int 类型
- 如示例中的 case 1、case 2。
如果是其他类型,比如使用
case a,会提示类型不匹配,无法编译通过。
而对于 switch 后省略表达式的情况
- 整个 switch 结构就和
if……else条件语句等同了。switch 后的表达式也没有太多限制,是一个合法的表达式即可
- 也不用一定要求是常量或者整数。
你甚至可以像如下代码一样,直接把比较表达式放在
switch之后
switch 2>1 {
case true:
fmt.Println("2>1")
case false:
fmt.Println("2<=1")
}
for循环语句
sum:=0
for i:=1;i<=100;i++ {
sum+=i
}
fmt.Println("the sum is",sum)
其中:
第一部分是一个简单语句,一般用于 for 循环的初始化
- 比如这里声明了一个变量,并对
i:=1初始化第二部分是 for 循环的条件,也就是说,它表示 for 循环什么时候结束。
- 这里的条件是 i<=100
第三部分是更新语句,一般用于更新循环的变量
- 比如这里 i++,这样才能达到递增循环的目的。
sum:=0
i:=1
for i<=100 {
sum+=i
i++
}
fmt.Println("the sum is",sum)
这个示例和上面的 for 示例的效果是一样的,但是这里的 for 后只有
i<=100这一个条件语句
- 也就是说,它达到了
while的效果。在 Go 语言中,同样支持使用 continue、break 控制 for 循环:
continue 可以跳出本次循环,继续执行下一个循环。
break 可以跳出整个 for 循环
- 哪怕
for循环没有执行完,也会强制终止。
sum:=0
i:=1
for {
sum+=i
i++
if i>100 {
break
}
}
fmt.Println("the sum is",sum)
集合类型
Array(数组)
数组存放的是固定长度、相同类型的数据
- 而且这些存放的元素是连续的。
所存放的数据类型没有限制,可以是整型、字符串甚至自定义。
数组声明:
在下面的代码示例中,声明了一个字符串数组,长度是 5
- 所以其类型定义为
[5]string,其中大括号中的元素用于初始化数组。此外,在类型名前加
[]中括号,并设置好长度
- 就可以通过它来推测数组的类型。
注意:
[5]string和[4]string不是同一种类型
- 也就是说长度也是数组类型的一部分。
array:=[5]string{"a","b","c","d","e"}
如下面代码所示,运行它,可以看到输出打印的结果是 c
- 也就是数组
array的第三个元素
func main() {
array:=[5]string{"a","b","c","d","e"}
fmt.Println(array[2])
}
在定义数组的时候,数组的长度可以省略
- 这个时候 Go 语言会自动根据大括号
{}中元素的个数推导出长度所以以上示例也可以像下面这样声明:
array:=[...]string{"a","b","c","d","e"}
以上省略数组长度的声明只适用于所有元素都被初始化的数组
- 如果是只针对特定索引元素初始化的情况,就不适合了
如下示例:
array1:=[5]string{1:"b",3:"d"}
示例中的
「1:“b”,3:“d”」的意思表示初始化索引 1 的值为 b
- 初始化索引 3 的值为 d,整个数组的长度为 5。
如果我省略长度 5,那么整个数组的长度只有 4
- 显然不符合我们定义数组的初衷。
此外,没有初始化的索引,其默认值都是数组类型的零值
- 也就是 string 类型的零值
“”空字符串。除了使用 [] 操作符根据索引快速定位数组的元素外
- 还可以通过 for 循环打印所有的数组元素
如下面的代码所示:
for i:=0;i<5;i++{
fmt.Printf("数组索引:%d,对应值:%s\n", i, array[i])
}
数组循环
使用传统的 for 循环遍历数组,输出对应的索引和对应的值
这种方式很烦琐,一般不使用
大部分情况下,使用的是
for range这种 Go 语言的新型循环如下面的代码所示:
for i,v:=range array{
fmt.Printf("数组索引:%d,对应值:%s\n", i, v)
}
这种方式和传统 for 循环的结果是一样的。
对于数组,range 表达式返回两个结果:
第一个是数组的索引
第二个是数组的值
在上面的示例中,把返回的两个结果分别赋值给 i 和 v 这两个变量,就可以使用它们了。
相比传统的 for 循环,for range 要更简洁
- 如果返回的值用不到,可以使用
_下划线丢弃如下面的代码所示:
for _,v:=range array{
fmt.Printf("对应值:%s\n", v)
}
数组的索引通过 _ 就被丢弃了,只使用数组的值 v 即可。
Slice(切片)
切片和数组类似,可以把它理解为动态数组。
切片是基于数组实现的
- 它的底层就是一个数组。
对数组任意分隔,就可以得到一个切片。
基于数组生成切片:
下面代码中的
array[2:5]就是获取一个切片的操作
- 它包含从数组 array 的索引 2 开始到索引 5 结束的元素
array:=[5]string{"a","b","c","d","e"}
slice:=array[2:5]
fmt.Println(slice)
注意:这里是包含索引 2,但是不包含索引 5 的元素
- 即在 : 右边的数字不会被包含。
//基于数组生成切片,包含索引start,但是不包含索引end
slice:=array[start:end]
所以
array[2:5]获取到的是 c、d、e 这三个元素
- 然后这三个元素作为一个切片赋值给变量 slice。
切片和数组一样,也可以通过索引定位元素。
这里以新获取的 slice 切片为例
slice[0]的值为 c,slice[1]的值为 d。在数组 array 中,元素 c 的索引其实是 2
- 但是对数组切片后,在新生成的切片 slice 中,它的索引是 0,这就是切片。
虽然切片底层用的也是 array 数组
- 但是经过切片后,切片的索引范围改变了。
这里有一些小技巧,切片表达式
array[start:end]中的 start 和 end 索引都是可以省略的如果省略 start,那么 start 的值默认为 0
- 如果省略 end,那么 end 的默认值为数组的长度。
如下面的示例:
array[:4]等价于array[0:4]。
array[1:]等价于array[1:5]。
array[:]等价于array[0:5]。
切片修改
切片的值也可以被修改,这里也同时可以证明切片的底层是数组。
- 对切片相应的索引元素赋值就是修改
在下面的代码中,把切片 slice 索引 1 的值修改为 f,然后打印输出数组 array
slice:=array[2:5]
slice[1] ="f"
fmt.Println(array)
可以看到如下结果:
[a b c f e]
数组对应的值已经被修改为 f,所以这也证明了基于数组的切片,使用的底层数组还是原来的数组
- 一旦修改切片的元素值,那么底层数组对应的值也会被修改。
切片声明
除了可以从一个数组得到切片外,还可以声明切片
- 比较简单的是使用
make函数。下面的代码是声明了一个元素类型为 string 的切片,长度是 4
- make 函数还可以传入一个容量参数
slice1:=make([]string,4)
在下面的例子中,指定了新创建的切片
[]string容量为 8:
slice1:=make([]string,4,8)
这里需要注意的是,切片的容量不能比切片的长度小。
- 切片的长度就是切片内元素的个数。
那么容量是什么呢?其实就是切片的空间。
上面的示例说明,Go 语言在内存上划分了一块容量为 8 的内容空间(容量为 8)
- 但是只有 4 个内存空间才有元素(长度为 4)
其他的内存空间处于空闲状态,当通过 append 函数往切片中追加元素的时候,会追加到空闲的内存上
- 当切片的长度要超过容量的时候,会进行扩容。
切片不仅可以通过
make函数声明,也可以通过字面量的方式声明和初始化,如下所示:
slice1:=[]string{"a","b","c","d","e"}
fmt.Println(len(slice1),cap(slice1))
可以注意到,切片和数组的字面量初始化方式,差别就是中括号 [] 里的长度。
此外,通过字面量初始化的切片,长度和容量相同。
Append
可以通过内置的 append 函数对一个切片追加元素,返回新切片,如下面的代码所示:
//追加一个元素
slice2:=append(slice1,"f")
//多加多个元素
slice2:=append(slice1,"f","g")
//追加另一个切片
slice2:=append(slice1,slice...)
append 函数可以有以上三种操作,可以根据自己的实际需求进行选择
- append 会自动处理切片容量不足需要扩容的问题。
在创建新切片的时候,最好要让新切片的长度和容量一样
这样在追加操作的时候就会生成新的底层数组,从而和原有数组分离
就不会因为共用底层数组导致修改内容的时候影响多个切片
切片元素循环
切片的循环和数组一模一样,常用的也是
for range方式。在 Go 语言开发中,切片是使用最多的,尤其是作为函数的参数时
- 相比数组,通常会优先选择切片,因为它高效,内存占用小。
Map(映射)
在 Go 语言中,map 是一个无序的 K-V 键值对集合,结构为
map[K]V。
- 其中 K 对应 Key,V 对应 Value。
map 中所有的 Key 必须具有相同的类型,Value 也同样
- 但 Key 和 Value 的类型可以不同。
此外,Key 的类型必须支持 == 比较运算符,这样才可以判断它是否存在,并保证 Key 的唯一。
Map声明初始化
创建一个 map 可以通过内置的 make 函数,如下面的代码所示:
nameAgeMap:=make(map[string]int)
它的 Key 类型为 string,Value 类型为 int。
- 有了创建好的 map 变量,就可以对它进行操作了。
在下面的示例中,添加了一个键值对,Key 为飞雪无情,Value 为 20
- 如果 Key 已经存在,则更新 Key 对应的 Value
nameAgeMap["飞雪无情"] = 20
除了可以通过 make 函数创建 map 外,还可以通过字面量的方式。
同样是上面的示例,用字面量的方式做如下操作:
nameAgeMap:=map[string]int{"飞雪无情":20}
在创建 map 的同时添加键值对,如果不想添加键值对,使用空大括号 {} 即可
- 要注意的是,大括号一定不能省略。
Map 获取和删除
map 的操作和切片、数组差不多,都是通过 [] 操作符,只不过数组切片的 [] 中是索引
- 而 map 的 [] 中是 Key,如下面的代码所示:
//添加键值对或者更新对应 Key 的 Value
nameAgeMap["飞雪无情"] = 20
//获取指定 Key 对应的 Value
age:=nameAgeMap["飞雪无情"]
Go 语言的 map 可以获取不存在的 K-V 键值对
- 如果 Key 不存在,返回的 Value 是该类型的零值,比如 int 的零值就是 0。
所以很多时候,需要先判断 map 中的 Key 是否存在。
map 的 [] 操作符可以返回两个值:
第一个值是对应的 Value;
第二个值标记该 Key 是否存在,如果存在,它的值为 true。
nameAgeMap:=make(map[string]int)
nameAgeMap["飞雪无情"] = 20
age,ok:=nameAgeMap["飞雪无情1"]
if ok {
fmt.Println(age)
}
在示例中,age 是返回的 Value
- ok 用来标记该 Key 是否存在,如果存在则打印 age。
如果要删除 map 中的键值对,使用内置的 delete 函数即可
- 比如要删除 nameAgeMap 中 Key 为飞雪无情的键值对。
delete(nameAgeMap,"飞雪无情")
delete 有两个参数:第一个参数是 map,第二个参数是要删除键值对的 Key。
遍历 Map
map 是一个键值对集合,它同样可以被遍历
- 在 Go 语言中,map 的遍历使用
for range循环。对于 map,for range 返回两个值:
第一个是 map 的 Key
第二个是 map 的 Value。
//测试 for range
nameAgeMap["飞雪无情"] = 20
nameAgeMap["飞雪无情1"] = 21
nameAgeMap["飞雪无情2"] = 22
for k,v:=range nameAgeMap{
fmt.Println("Key is",k,",Value is",v)
}
需要注意的是 map 的遍历是无序的
- 也就是说你每次遍历,键值对的顺序可能会不一样。
如果想按顺序遍历,可以先获取所有的 Key,并对 Key 排序
- 然后根据排序好的 Key 获取对应的 Value。
小技巧:
for range map的时候,也可以使用一个值返回。使用一个返回值的时候,这个返回值默认是 map 的 Key。
Map 的大小
和数组切片不一样,map 是没有容量的,它只有长度
- 也就是 map 的大小(键值对的个数)。
要获取 map 的大小,使用内置的 len 函数即可,如下代码所示:
fmt.Println(len(nameAgeMap))
函数和方法
函数声明
func funcName(params) result {
body
}
这就是一个函数的签名定义,它包含以下几个部分:
关键字 func
函数名字 funcName
函数的参数 params,用来定义形参的变量名和类型
- 可以有一个参数,也可以有多个,也可以没有
result 是返回的函数值,用于定义返回值的类型
- 如果没有返回值,省略即可,也可以有多个返回值
body 就是函数体,可以在这里写函数的代码逻辑
func sum(a int,b int) int{
return a+b
}
函数中形参的定义和定义变量是一样的,都是变量名称在前,变量类型在后
- 只不过在函数里,变量名称叫作参数名称
- 也就是函数的形参,形参只能在该函数体内使用。
函数形参的值由调用者提供,这个值也称为函数的实参
- 现在传递实参给 sum 函数
演示函数的调用,如下面的代码所示:
func main() {
result:=sum(1,2)
fmt.Println(result)
}
自定义的 sum 函数,在 main 函数中直接调用
- 调用的时候需要提供真实的参数,也就是实参 1 和 2。
函数的返回值被赋值给变量 result,然后把这个结果打印出来。
- 在以上函数定义中,a 和 b 形参的类型是一样的
这个时候可以省略其中一个类型的声明,如下所示:
func sum(a, b int) int {
return a + b
}
像这样使用逗号分隔变量,后面统一使用 int 类型
- 这和变量的声明是一样的,多个相同类型的变量都可以这么声明。
多值返回
在 Go 语言的标准库中,可以看到很多这样的函数:
- 第一个值返回函数的结果,第二个值返回函数出错的信息,这种就是多值返回的经典应用。
对于
sum函数,假设不允许提供的实参是负数,可以这样改造:
- 在实参是负数的时候,通过多值返回,返回函数的错误信息
如下面的代码所示:
func sum(a, b int) (int,error){
if a<0 || b<0 {
return 0,errors.New("a或者b不能是负数")
}
return a + b,nil
}
这里需要注意的是,如果函数有多个返回值
- 返回值部分的类型定义需要使用小括号括起来,也就是 (
int,error)。这代表函数 sum 有两个返回值,第一个是 int 类型,第二个是 error 类型
- 在函数体中使用 return 返回结果的时候,也要符合这个类型顺序。
在函数体中,可以使用 return 返回多个值,返回的多个值通过逗号分隔即可
- 返回多个值的类型顺序要和函数声明的返回类型顺序一致
比如下面的例子:
return 0,errors.New("a或者b不能是负数")
返回的第一个值 0 是 int 类型,第二个值是 error 类型
和函数定义的返回类型完全一致。
定义好了多值返回的函数
现在我们用如下代码尝试调用
func main() {
result,err := sum(1, 2)
if err!=nil {
fmt.Println(err)
}else {
fmt.Println(result)
}
}
函数有多值返回的时候,需要有多个变量接收它的值
- 示例中使用 result 和 err 变量,使用逗号分开。
如果有的函数的返回值不需要,可以使用下划线
_丢弃它
- 这种方式我在
for range循环那节课里也使用过如下所示:
result,_ := sum(1, 2)
这样即可忽略函数 sum 返回的错误信息,也不用再做判断。
提示:这里使用的 error 是 Go 语言内置的一个接口
- 用于表示程序的错误信息。
命名返回参数
不止函数的参数可以有变量名称,函数的返回值也可以
- 也就是说你可以为每个返回值都起一个名字
- 这个名字可以像参数一样在函数体内使用。
func sum(a, b int) (sum int,err error){
if a<0 || b<0 {
return 0,errors.New("a或者b不能是负数")
}
sum=a+b
err=nil
return
}
返回值的命名和参数、变量都是一样的,名称在前,类型在后。
以上示例中,命名的两个返回值名称,一个是 sum,一个是 err
- 这样就可以在函数体中使用它们了。
通过下面示例中的这种方式直接为命名返回参数赋值,也就等于函数有了返回值
- 所以就可以忽略 return 的返回值了,也就是说
示例中只有一个 return,return 后没有要返回的值。
sum=a+b
err=nil
通过命名返回参数的赋值方式,和直接使用 return 返回值的方式结果是一样的
- 所以调用以上 sum 函数,返回的结果也一样。
虽然 Go 语言支持函数返回值命名,但是并不是太常用
- 根据自己的需求情况,酌情选择是否对函数返回值命名。
可变参数
可变参数,就是函数的参数数量是可变的
- 比如最常见的
fmt.Println函数。同样一个函数,可以不传参数,也可以传递一个参数,也可以两个参数,也可以是多个等等
- 这种函数就是具有可变参数的函数
如下所示:
fmt.Println()
fmt.Println("飞雪")
fmt.Println("飞雪","无情")
下面所演示的是 Println 函数的声明
从中可以看到,定义可变参数,只要在参数类型前加三个点
…即可
func Println(a ...interface{}) (n int, err error)
现在也可以定义自己的可变参数的函数了。
还是以 sum 函数为例,在下面的代码中,我通过可变参数的方式
- 计算调用者传递的所有实参的和
func sum1(params ...int) int {
sum := 0
for _, i := range params {
sum += i
}
return sum
}
为了便于和 sum 函数区分,我定义了函数 sum1,该函数的参数是一个可变参数
- 然后通过
for range循环来计算这些参数之和。可变参数的类型其实就是切片,比如示例中 params 参数的类型是
[]int
- 所以可以使用
for range进行循环。
fmt.Println(sum1(1,2))
fmt.Println(sum1(1,2,3))
fmt.Println(sum1(1,2,3,4))
这里需要注意,如果你定义的函数中既有普通参数,又有可变参数
那么可变参数一定要放在参数列表的最后一个
比如
sum1(tip string,params …int)
- params 可变参数一定要放在最末尾。
包级函数
不管是自定义的函数 sum、sum1,还是我们使用到的函数 Println
- 都会从属于一个包,也就是 package。
sum 函数属于 main 包,Println 函数属于 fmt 包。
同一个包中的函数哪怕是私有的(函数名称首字母小写)也可以被调用。
如果不同包的函数要被调用,那么函数的作用域必须是公有的
也就是函数名称的首字母要大写,比如 Println。
函数名称首字母小写代表私有函数,只有在同一个包中才可以被调用
函数名称首字母大写代表公有函数,不同的包也可以调用
任何一个函数都会从属于一个包。
Go 语言没有用
public、private这样的修饰符来修饰函数是公有还是私有
- 而是通过函数名称的大小写来代表,这样省略了烦琐的修饰符,更简洁。
匿名函数和闭包
匿名函数就是没有名字的函数,这是它和正常函数的主要区别。
在下面的示例中,变量 sum2 所对应的值就是一个匿名函数。
- 需要注意的是,这里的 sum2 只是一个函数类型的变量,并不是函数的名字。
func main() {
sum2 := func(a, b int) int {
return a + b
}
fmt.Println(sum2(1, 2))
}
通过 sum2,我们可以对匿名函数进行调用
- 以上示例算出的结果是 3,和使用正常的函数一样。
有了匿名函数,就可以在函数中再定义函数(函数嵌套)
- 定义的这个匿名函数,也可以称为内部函数。
更重要的是,在函数内定义的内部函数
- 可以使用外部函数的变量等,这种方式也称为闭包。
func main() {
cl:=colsure()
fmt.Println(cl())
fmt.Println(cl())
fmt.Println(cl())
}
func colsure() func() int {
i:=0
return func() int {
i++
return i
}
}
运行这个代码,你会看到输出打印的结果是:
1
2
3
这都得益于匿名函数闭包的能力,让我们自定义的 colsure 函数
- 可以返回一个匿名函数,并且持有外部函数 colsure 的变量 i。
因而在 main 函数中,每调用一次
cl(),i 的值就会加 1。
在 Go 语言中,函数也是一种类型
- 它也可以被用来声明函数类型的变量、参数或者作为另一个函数的返回值类型。
不同于函数的方法
在 Go 语言中,方法和函数是两个概念,但又非常相似
不同点在于方法必须要有一个接收者,这个接收者是一个类型
这样方法就和这个类型绑定在一起,称为这个类型的方法。
在下面的示例中,
type Age uint表示定义一个新类型 Age
- 该类型等价于 uint,可以理解为类型 uint 的重命名。
其中 type 是 Go 语言关键字
- 表示定义一个类型。
type Age uint
func (age Age) String(){
fmt.Println("the age is",age)
}
示例中方法 String() 就是类型 Age 的方法
- 类型 Age 是方法 String() 的接收者。
和函数不同,定义方法时会在关键字 func 和方法名 String 之间加一个接收者 (age Age)
- 接收者使用小括号包围。
接收者的定义和普通变量、函数参数等一样
- 前面是变量名,后面是接收者类型。
现在方法 String() 就和类型 Age 绑定在一起了,String() 是类型 Age 的方法。
- 定义了接收者的方法后,就可以通过点操作符调用方法
如下面的代码所示:
func main() {
age:=Age(25)
age.String()
}
运行这段代码,可以看到如下输出:
the age is 25
接收者就是函数和方法的最大不同
- 此外,上面所讲到的函数具备的能力,方法也都具备。
提示:因为 25 也是 unit 类型,unit 类型等价于我定义的 Age 类型
- 所以 25 可以强制转换为 Age 类型。
值类型接收者和指针类型接收者
方法的接收者除了可以是值类型,也可以是指针类型。
定义的方法的接收者类型是指针
- 所以对指针的修改是有效的,如果不是指针,修改就没有效果
如下所示:
func (age *Age) Modify(){
*age = Age(30)
}
调用一次 Modify 方法后,再调用 String 方法查看结果,会发现已经变成了 30
- 说明基于指针的修改有效
如下所示:
age:=Age(25)
age.String()
age.Modify()
age.String()
提示:
在调用方法的时候,传递的接收者本质上都是副本
- 只不过一个是这个值副本,一是指向这个值指针的副本。
指针具有指向原有值的特性,所以修改了指针指向的值,也就修改了原有的值。
我们可以简单地理解为值接收者使用的是值的副本来调用方法
- 而指针接收者使用实际的值来调用方法。
示例中调用指针接收者方法的时候,使用的是一个值类型的变量,并不是一个指针类型
- 其实这里使用指针变量调用也是可以的
如下面的代码所示:
(&age).Modify()
这就是 Go 语言编译器帮我们自动做的事情:
如果使用一个值类型变量调用指针类型接收者的方法
- Go 语言编译器会自动帮我们取指针调用,以满足指针接收者的要求。
同样的原理,如果使用一个指针类型变量调用值类型接收者的方法
- Go 语言编译器会自动帮我们解引用调用,以满足值类型接收者的要求。
总之,方法的调用者,既可以是值也可以是指针,不用太关注这些
- Go 语言会帮我们自动转义,大大提高开发效率,同时避免因不小心造成的 Bug。
不管是使用值类型接收者,还是指针类型接收者,要先确定你的需求:
- 在对类型进行操作的时候是要改变当前接收者的值,还是要创建一个新值进行返回?
这些就可以决定使用哪种接收者。
结构体与接口
结构体定义
结构体是一种聚合类型,里面可以包含任意类型的值
- 这些值就是我们定义的结构体的成员,也称为字段。
在 Go 语言中,要自定义一个结构体,需要使用
type+struct关键字组合。在下面的例子中,自定义了一个结构体类型,名称为 person,表示一个人。
这个 person 结构体有两个字段:
- name 代表这个人的名字,age 代表这个人的年龄。
type person struct {
name string
age uint
}
在定义结构体时,字段的声明方法和平时声明一个变量是一样的,都是变量名在前,类型在后
- 只不过在结构体中,变量名称为成员名或字段名。
结构体的成员字段并不是必需的
- 也可以一个字段都没有,这种结构体成为空结构体。
根据以上信息,我们可以总结出结构体定义的表达式
如下面的代码所示:
type structName struct{
fieldName typeName
....
....
}
其中:
- type 和 struct 是 Go 语言的关键字
- 二者组合就代表要定义一个新的结构体类型。
- structName 是结构体类型的名字。
- fieldName 是结构体的字段名,而 typeName 是对应的字段类型。
- 字段可以是零个、一个或者多个。
结构体也是一种类型,所以以后自定义的结构体
- 会称为某结构体或某类型,两者是一个意思。
比如 person 结构体和 person 类型其实是一个意思。
定义好结构体后就可以使用了
- 因为它是一个聚合类型,所以比普通的类型可以携带更多数据。
结构体声明使用
结构体类型和普通的字符串、整型一样,也可以使用同样的方式声明和初始化。
在下面的例子中,我声明了一个 person 类型的变量 p
- 因为没有对变量 p 初始化,所以默认会使用结构体里字段的零值。
var p person
当然在声明一个结构体变量的时候
- 也可以通过结构体字面量的方式初始化
如下面的代码所示:
p:=person{"飞雪无情",30}
采用简短声明法,同时采用字面量初始化的方式
- 把结构体变量 p 的 name 初始化为
飞雪无情,age 初始化为 30,以逗号分隔。声明了一个结构体变量后就可以使用了
下面我们运行以下代码,验证 name 和 age 的值是否和初始化的一样。
fmt.Println(p.name,p.age)
在 Go 语言中,访问一个结构体的字段和调用一个类型的方法一样,都是使用点操作符
.。
- 采用字面量初始化结构体时,初始化值的顺序很重要,必须和字段定义的顺序一致。
在 person 这个结构体中,第一个字段是 string 类型的 name,第二个字段是 uint 类型的 age
- 所以在初始化的时候,初始化值的类型顺序必须一一对应,才能编译通过。
也就是说,在示例
{“飞雪无情”,30}中
- 表示 name 的字符串飞雪无情必须在前,表示年龄的数字 30 必须在后。
那么是否可以不按照顺序初始化呢?
- 当然可以,只不过需要指出字段名称
如下所示:
p:=person{age:30,name:"飞雪无情"}
其中,第一位我放了整型的 age,也可以编译通过
- 因为采用了明确的
field:value方式进行指定
- 这样 Go 语言编译器会清晰地知道你要初始化哪个字段的值。
有没有发现,这种方式和 map 类型的初始化很像,都是采用冒号分隔。
- Go 语言尽可能地重用操作,不发明新的表达式,便于我们记忆和使用。
当然你也可以只初始化字段 age,字段 name 使用默认的零值
如下面的代码所示,仍然可以编译通过。
p:=person{age:30}
字段结构体
结构体的字段可以是任意类型,也包括自定义的结构体类型,比如下面的代码:
type person struct {
name string
age uint
addr address
}
type address struct {
province string
city string
}
在这个示例中,我定义了两个结构体:person 表示人,address 表示地址。
在结构体 person 中,有一个 address 类型的字段 addr,这就是自定义的结构体。
- 通过这种方式,用代码描述现实中的实体会更匹配,复用程度也更高。
对于嵌套结构体字段的结构体,其初始化和正常的结构体大同小异
- 只需要根据字段对应的类型初始化即可
如下面的代码所示:
p:=person{
age:30,
name:"飞雪无情",
addr:address{
province: "北京",
city: "北京",
},
}
如果需要访问结构体最里层的 province 字段的值,同样也可以使用点操作符
- 只不过需要使用两个点
如下面的代码所示:
fmt.Println(p.addr.province)
第一个点获取 addr,第二个点获取 addr 的 province。
接口的定义
接口是和调用方的一种约定,它是一个高度抽象的类型,不用和具体的实现细节绑定在一起。
接口要做的是定义好约定,告诉调用方自己可以做什么,但不用知道它的内部实现
- 这和我们见到的具体的类型如 int、map、slice 等不一样。
接口的定义和结构体稍微有些差别,虽然都以 type 关键字开始
- 但接口的关键字是 interface,表示自定义的类型是一个接口。
也就是说 Stringer 是一个接口,它有一个方法
String() string整体如下面的代码所示:
type Stringer interface {
String() string
}
提示:Stringer 是 Go SDK 的一个接口,属于 fmt 包。
针对 Stringer 接口来说,它会告诉调用者可以通过它的
String()方法获取一个字符串
- 这就是接口的约定。
至于这个字符串怎么获得的,长什么样,接口不关心,调用者也不用关心,因为这些是由接口实现者来做的。
接口的实现
接口的实现者必须是一个具体的类型,继续以 person 结构体为例
- 让它来实现 Stringer 接口
如下代码所示:
func (p person) String() string{
return fmt.Sprintf("the name is %s,age is %d",p.name,p.age)
}
给结构体类型 person 定义一个方法,这个方法和接口里方法的签名(名称、参数和返回值)一样
- 这样结构体 person 就实现了 Stringer 接口。
注意:如果一个接口有多个方法,那么需要实现接口的每个方法才算是实现了这个接口。
实现了 Stringer 接口后就可以使用了。
- 首先我先来定义一个可以打印 Stringer 接口的函数
如下所示:
func printString(s fmt.Stringer){
fmt.Println(s.String())
}
这个被定义的函数 printString,它接收一个 Stringer 接口类型的参数
- 然后打印出 Stringer 接口的 String 方法返回的字符串。
printString 这个函数的优势就在于它是面向接口编程的
- 只要一个类型实现了 Stringer 接口,都可以打印出对应的字符串,而不用管具体的类型实现。
因为 person 实现了 Stringer 接口
- 所以变量 p 可以作为函数 printString 的参数
可以用如下方式打印:
printString(p)
结果为:
the name is 飞雪无情,age is 30
现在让结构体 address 也实现 Stringer 接口,如下面的代码所示:
func (addr address) String() string{
return fmt.Sprintf("the addr is %s%s",addr.province,addr.city)
}
因为结构体 address 也实现了 Stringer 接口
- 所以 printString 函数不用做任何改变,可以直接被使用,打印出地址
如下所示:
printString(p.addr)
//输出:the addr is 北京北京
这就是面向接口的好处,只要定义和调用双方满足约定,就可以使用
- 而不用管具体实现。
接口的实现者也可以更好的升级重构,而不会有任何影响,因为接口约定没有变。
值接收者和指针接收者
如果要实现一个接口,必须实现这个接口提供的所有方法,
我们也知道定义一个方法,有值类型接收者和指针类型接收者两种。
二者都可以调用方法,因为 Go 语言编译器自动做了转换
- 所以值类型接收者和指针类型接收者是等价的。
但是在接口的实现中,值类型接收者和指针类型接收者不一样。
结构体类型实现了 Stringer 接口,那么结构体对应的指针是否也实现了该接口呢?
通过下面这个代码进行测试:
printString(&p)
测试后会发现,把变量 p 的指针作为实参传给 printString 函数也是可以的,编译运行都正常。
- 这就证明了以值类型接收者实现接口的时候,不管是类型本身,还是该类型的指针类型,都实现了该接口。
示例中值接收者(p person)实现了 Stringer 接口
- 那么类型 person 和它的指针类型*person就都实现了 Stringer 接口。
现在,我把接收者改成指针类型,如下代码所示:
func (p *person) String() string{
return fmt.Sprintf("the name is %s,age is %d",p.name,p.age)
}
修改成指针类型接收者后会发现,示例中这行 printString(p) 代码编译不通过
提示如下错误:
./main.go:17:13: cannot use p (type person) as type fmt.Stringer in argument to printString:
person does not implement fmt.Stringer (String method has pointer receiver)
意思就是类型 person 没有实现 Stringer 接口。
- 这就证明了以指针类型接收者实现接口的时候,只有对应的指针类型才被认为实现了该接口。
用如下表格总结这两种接收者类型的接口实现规则:
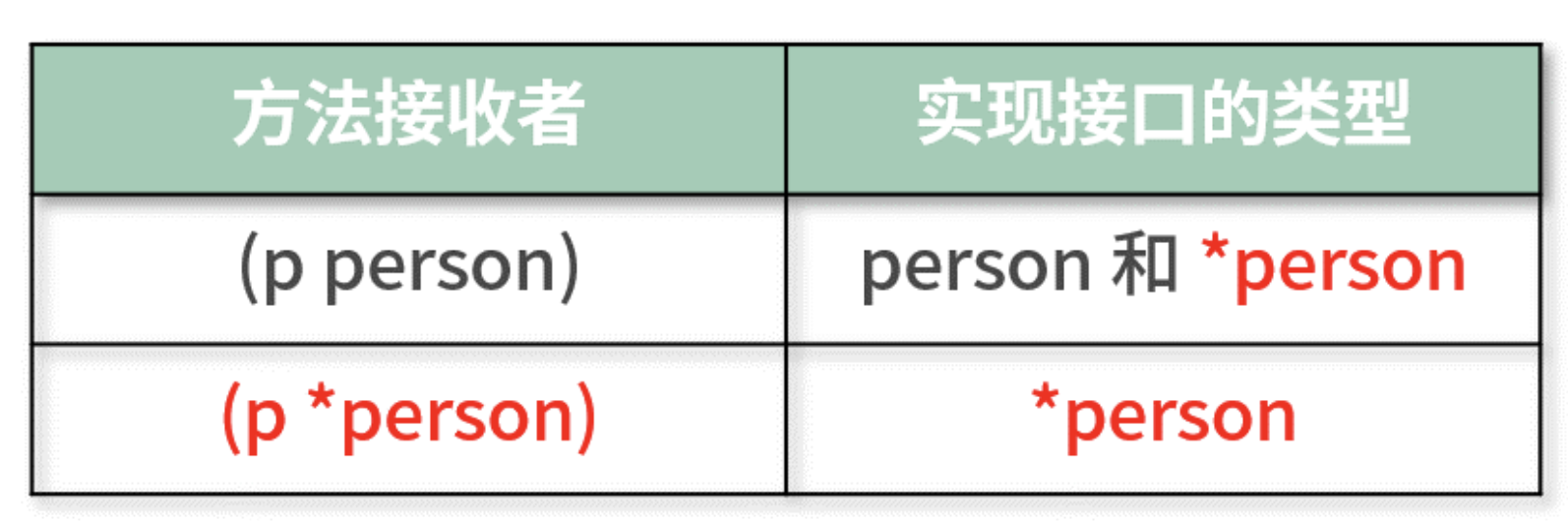
可以这样解读:
- 当值类型作为接收者时,person 类型和
*person类型都实现了该接口。- 当指针类型作为接收者时,只有
*person类型实现了该接口。可以发现,实现接口的类型都有
*person,这也表明指针类型比较万能
- 不管哪一种接收者,它都能实现该接口。
工厂函数
工厂函数一般用于创建自定义的结构体,便于使用者调用
还是以 person 类型为例,用如下代码进行定义:
func NewPerson(name string) *person {
return &person{name:name}
}
我定义了一个工厂函数 NewPerson,它接收一个 string 类型的参数
- 用于表示这个人的名字,同时返回一个*person。
通过工厂函数创建自定义结构体的方式,可以让调用者不用太关注结构体内部的字段
- 只需要给工厂函数传参就可以了。
用下面的代码,即可创建一个
*person类型的变量 p1:
p1:=NewPerson("张三")
工厂函数也可以用来创建一个接口
- 它的好处就是可以隐藏内部具体类型的实现,让调用者只需关注接口的使用即可。
现在我以
errors.New这个 Go 语言自带的工厂函数为例
- 演示如何通过工厂函数创建一个接口,并隐藏其内部实现
如下代码所示:
//工厂函数,返回一个error接口,其实具体实现是*errorString
func New(text string) error {
return &errorString{text}
}
//结构体,内部一个字段s,存储错误信息
type errorString struct {
s string
}
//用于实现error接口
func (e *errorString) Error() string {
return e.s
}
其中,errorString 是一个结构体类型,它实现了 error 接口,所以可以通过 New 工厂函数
- 创建一个
*errorString类型,通过接口 error 返回。这就是面向接口的编程,假设重构代码,哪怕换一个其他结构体实现 error 接口
- 对调用者也没有影响,因为接口没变。
继承和组合
在 Go 语言中没有继承的概念,所以结构、接口之间也没有父子关系,Go 语言提倡的是组合
- 利用组合达到代码复用的目的,这也更灵活。
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
//ReadWriter是Reader和Writer的组合
type ReadWriter interface {
Reader
Writer
}
ReadWriter 接口就是 Reader 和 Writer 的组合,组合后
ReadWriter 接口具有 Reader 和 Writer 中的所有方法
- 这样新接口 ReadWriter 就不用定义自己的方法了,组合 Reader 和 Writer 的就可以了。
不止接口可以组合,结构体也可以组合
- 现在把 address 结构体组合到结构体 person 中,而不是当成一个字段
如下所示:
type person struct {
name string
age uint
address
}
直接把结构体类型放进来,就是组合,不需要字段名。
- 组合后,被组合的 address 称为内部类型,person 称为外部类型。
修改了 person 结构体后,声明和使用也需要一起修改,如下所示:
p:=person{
age:30,
name:"飞雪无情",
address:address{
province: "北京",
city: "北京",
},
}
//像使用自己的字段一样,直接使用
fmt.Println(p.province)
因为 person 组合了 address,所以 address 的字段就像 person 自己的一样,可以直接使用。
类型组合后,外部类型不仅可以使用内部类型的字段
- 也可以使用内部类型的方法,就像使用自己的方法一样。
如果外部类型定义了和内部类型同样的方法,那么外部类型的会覆盖内部类型,这就是方法的覆写。
方法覆写不会影响内部类型的方法实现。
类型断言
有了接口和实现接口的类型,就会有类型断言。
类型断言用来判断一个接口的值是否是实现该接口的某个具体类型。
func (p *person) String() string{
return fmt.Sprintf("the name is %s,age is %d",p.name,p.age)
}
func (addr address) String() string{
return fmt.Sprintf("the addr is %s%s",addr.province,addr.city)
}
可以看到,
*person和 address 都实现了接口 Stringer然后我通过下面的示例讲解类型断言:
var s fmt.Stringer
s = p1
p2:=s.(*person)
fmt.Println(p2)
如上所示,接口变量 s 称为接口 fmt.Stringer 的值,它被 p1 赋值。
然后使用类型断言表达式
s.(*person),尝试返回一个 p2。
如果接口的值 s 是一个
*person,那么类型断言正确,可以正常返回 p2。如果接口的值 s 不是一个
*person,那么在运行时就会抛出异常,程序终止运行。
这里返回的 p2 已经是
*person类型了,也就是在类型断言的时候,同时完成了类型转换。
在上面的示例中,因为 s 的确是一个
*person,所以不会异常,可以正常返回 p2。但是如果我再添加如下代码,对 s 进行 address 类型断言,就会出现一些问题:
a:=s.(address)
fmt.Println(a)
这个代码在编译的时候不会有问题,因为 address 实现了接口 Stringer
但是在运行的时候,会抛出如下异常信息:
panic: interface conversion: fmt.Stringer is *main.person, not main.address
这显然不符合我们的初衷,我们本来想判断一个接口的值是否是某个具体类型
- 但不能因为判断失败就导致程序异常。
考虑到这点,Go 语言为我们提供了类型断言的多值返回,如下所示:
a,ok:=s.(address)
if ok {
fmt.Println(a)
}else {
fmt.Println("s不是一个address")
}
类型断言返回的第二个值
ok就是断言是否成功的标志
- 如果为 true 则成功,否则失败。
错误处理
错误
在 Go 语言中,错误是可以预期的,并且不是非常严重
- 不会影响程序的运行。
对于这类问题,可以用返回错误给调用者的方法,让调用者自己决定如何处理。
error 接口
在 Go 语言中,错误是通过内置的 error 接口表示的。
- 只有一个 Error 方法用来返回具体的错误信息
如下面的代码所示:
type error interface {
Error() string
}
在下面的代码中,演示了一个字符串转整数的例子:
func main() {
i,err:=strconv.Atoi("a")
if err!=nil {
fmt.Println(err)
}else {
fmt.Println(i)
}
}
这里故意使用了字符串
a,尝试把它转为整数。
a是无法转为数字的,所以运行这段程序,会打印出如下错误信息:
strconv.Atoi: parsing "a": invalid syntax
这个错误信息就是通过接口 error 返回的。
来看关于函数
strconv.Atoi的定义,如下所示:
func Atoi(s string) (int, error)
一般而言,error 接口用于当方法或者函数执行遇到错误时进行返回,而且是第二个返回值。
通过这种方式,可以让调用者自己根据错误信息决定如何进行下一步处理。
因为方法和函数基本上差不多,区别只在于有无接收者
- 所以以后当我称方法或函数,表达的是一个意思,不会把这两个名字都写出来。
error 工厂函数
除了可以使用其他函数,自己定义的函数也可以返回错误信息给调用者
如下面的代码所示:
func add(a,b int) (int,error){
if a<0 || b<0 {
return 0,errors.New("a或者b不能为负数")
}else {
return a+b,nil
}
}
add 函数会在 a 或者 b 任何一个为负数的情况下,返回一个错误信息
如果 a、b 都不为负数,错误信息部分会返回 nil,这也是常见的做法。
- 所以调用者可以通过错误信息是否为
nil进行判断。
下面的 add 函数示例,是使用
errors.New这个工厂函数生成的错误信息
- 它接收一个字符串参数,返回一个 error 接口。
sum,err:=add(-1,2)
if err!=nil {
fmt.Println(err)
}else {
fmt.Println(sum)
}
自定义 error
上面采用工厂返回错误信息的方式只能传递一个字符串,也就是携带的信息只有字符串
如果想要携带更多信息(比如错误码信息)该怎么办呢?
- 这个时候就需要自定义 error。
自定义 error 其实就是先自定义一个新类型
比如结构体,然后让这个类型实现 error 接口,如下面的代码所示:
type commonError struct {
errorCode int //错误码
errorMsg string //错误信息
}
func (ce *commonError) Error() string{
return ce.errorMsg
}
有了自定义的 error,就可以使用它携带更多的信息
现在改造上面的例子,返回刚刚自定义的 commonError,如下所示:
return 0, &commonError{
errorCode: 1,
errorMsg: "a或者b不能为负数"}
我通过字面量的方式创建一个
*commonError返回,其中 errorCode 值为 1
- errorMsg 值为 a 或者 b 不能为负数。
error 断言
有了自定义的 error,并且携带了更多的错误信息后,就可以使用这些信息了。
你需要先把返回的 error 接口转换为自定义的错误类型。
下面代码中的
err.(*commonError)就是类型断言在 error 接口上的应用
- 也可以称为 error 断言。
sum, err := add(-1, 2)
if cm,ok:=err.(*commonError);ok{
fmt.Println("错误代码为:",cm.errorCode,",错误信息为:",cm.errorMsg)
} else {
fmt.Println(sum)
}
如果返回的 ok 为 true,说明 error 断言成功,正确返回了
*commonError类型的变量 cm
- 所以就可以像示例中一样使用变量 cm 的 errorCode 和 errorMsg 字段信息了。
Error Wrapping
error 接口虽然比较简洁,但是功能也比较弱。
想象一下,假如有这样的需求:基于一个存在的 error 再生成一个 error,需要怎么做呢?
- 这就是错误嵌套。
这种需求是存在的,比如调用一个函数,返回了一个错误信息 error
- 在不想丢失这个 error 的情况下,又想添加一些额外信息返回新的 error。
这时候,首先想到的应该是自定义一个
struct,如下面的代码所示:
type MyError struct {
err error
msg string
}
这个结构体有两个字段,其中 error 类型的 err 字段用于存放已存在的 error
- string 类型的 msg 字段用于存放新的错误信息
- 这种方式就是 error 的嵌套。
现在让 MyError 这个 struct 实现 error 接口
- 然后在初始化 MyError 的时候传递存在的 error 和新的错误信息
如下面的代码所示:
func (e *MyError) Error() string {
return e.err.Error() + e.msg
}
func main() {
//err是一个存在的错误,可以从另外一个函数返回
newErr := MyError{err, "数据上传问题"}
}
这种方式可以满足我们的需求,但是非常烦琐
- 因为既要定义新的类型还要实现 error 接口。
所以从 Go 语言 1.13 版本开始,Go 标准库新增了 Error Wrapping 功能
- 让我们可以基于一个存在的 error 生成新的 error,并且可以保留原 error 信息
如下面的代码所示:
e := errors.New("原始错误e")
w := fmt.Errorf("Wrap了一个错误:%w", e)
fmt.Println(w)
Go 语言没有提供 Wrap 函数,而是扩展了
fmt.Errorf函数
- 然后加了一个
%w,通过这种方式,便可以生成wrapping error。
errors.Unwrap 函数
既然 error 可以包裹嵌套生成一个新的 error,那么也可以被解开
- 即通过
errors.Unwrap函数得到被嵌套的 error。Go 语言提供了
errors.Unwrap用于获取被嵌套的 error
- 比如以上例子中的错误变量 w ,就可以对它进行 unwrap,获取被嵌套的原始错误 e。
fmt.Println(errors.Unwrap(w))
可以看到这样的信息,即:原始错误 e。
原始错误e
errors.Is 函数
有了 Error Wrapping 后,你会发现原来用的判断两个 error 是不是同一个 error 的方法失效了
- 比如 Go 语言标准库经常用到的如下代码中的方式:
if err == os.ErrExist
为什么会出现这种情况呢?
由于 Go 语言的 Error Wrapping 功能
- 令人不知道返回的 err 是否被嵌套,又嵌套了几层?
于是 Go 语言为我们提供了
errors.Is函数,用来判断两个 error 是否是同一个如下所示:
func Is(err, target error) bool
以上就是
errors.Is函数的定义,可以解释为:
- 如果 err 和 target 是同一个,那么返回 true。
- 如果 err 是一个 wrapping error,target 也包含在这个嵌套 error 链中的话,也返回 true。
可以简单地概括为,两个 error 相等或 err 包含 target 的情况下返回 true,其余返回 false。
我们可以用上面的示例判断错误 w 中是否包含错误 e
- 试试运行下面的代码,来看打印的结果是不是 true。
fmt.Println(errors.Is(w,e))
errors.As 函数
同样的原因,有了 error 嵌套后,error 断言也不能用了
- 因为你不知道一个 error 是否被嵌套,又嵌套了几层。
所以 Go 语言为解决这个问题提供了
errors.As函数
- 比如前面 error 断言的例子,可以使用
errors.As函数重写,效果是一样的如下面的代码所示:
var cm *commonError
if errors.As(err,&cm){
fmt.Println("错误代码为:",cm.errorCode,",错误信息为:",cm.errorMsg)
} else {
fmt.Println(sum)
}
所以在 Go 语言提供的 Error Wrapping 能力下
- 我们写的代码要尽可能地使用 Is、As 这些函数做判断和转换。
Deferred函数
在一个自定义函数中,你打开了一个文件,然后需要关闭它以释放资源。
- 不管你的代码执行了多少分支,是否出现了错误,文件是一定要关闭的,这样才能保证资源的释放。
如果这个事情由开发人员来做,随着业务逻辑的复杂会变得非常麻烦,而且还有可能会忘记关闭。
基于这种情况,Go 语言为我们提供了 defer 函数,可以保证文件关闭后一定会被执行
- 不管你自定义的函数出现异常还是错误。
下面的代码是 Go 语言标准包 ioutil 中的 ReadFile 函数,它需要打开一个文件
然后通过 defer 关键字确保在 ReadFile 函数执行结束后
f.Close()方法被执行,这样文件的资源才一定会释放。
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
//省略无关代码
return readAll(f, n)
}
defer 关键字用于修饰一个函数或者方法,使得该函数或者方法在返回前才会执行
- 也就说被延迟,但又可以保证一定会执行。
以上面的 ReadFile 函数为例,被 defer 修饰的
f.Close方法延迟执行
- 也就是说会先执行
readAll(f, n)- 然后在整个 ReadFile 函数 return 之前执行
f.Close方法。defer 语句常被用于成对的操作,如文件的打开和关闭,加锁和释放锁,连接的建立和断开等。
- 不管多么复杂的操作,都可以保证资源被正确地释放。
Panic 异常
Go 语言是一门静态的强类型语言,很多问题都尽可能地在编译时捕获,但是有一些只能在运行时检查
- 比如数组越界访问、不相同的类型强制转换等,这类运行时的问题会引起 panic 异常。
除了运行时可以产生 panic 外,我们自己也可以抛出 panic 异常。
- 假设我需要连接 MySQL 数据库,可以写一个连接 MySQL 的函数connectMySQL
如下面的代码所示:
func connectMySQL(ip,username,password string){
if ip =="" {
panic("ip不能为空")
}
//省略其他代码
}
在 connectMySQL 函数中,如果 ip 为空会直接抛出 panic 异常。
这种逻辑是正确的,因为数据库无法连接成功的话,整个程序运行起来也没有意义
- 所以就抛出 panic 终止程序的运行。
panic 是 Go 语言内置的函数,可以接受
interface{}类型的参数
- 也就是任何类型的值都可以传递给 panic 函数
如下所示:
func panic(v interface{})
interface{}是空接口的意思,在 Go 语言中代表任意类型。
panic 异常是一种非常严重的情况,会让程序中断运行,使程序崩溃
- 所以如果是不影响程序运行的错误,不要使用 panic,使用普通错误 error 即可。
并发基础
协程(Goroutine)
Go 语言中没有线程的概念,只有协程,也称为 goroutine。
相比线程来说,协程更加轻量
- 一个程序可以随意启动成千上万个
goroutine。
goroutine 被 Go runtime 所调度,这一点和线程不一样。
也就是说,Go 语言的并发是由 Go 自己所调度的
- 自己决定同时执行多少个
goroutine,什么时候执行哪几个。这些对于我们开发者来说完全透明,只需要在编码的时候告诉 Go 语言要启动几个 goroutine
- 至于如何调度执行,我们不用关心。
要启动一个
goroutine非常简单,Go 语言为我们提供了 go 关键字
- 相比其他编程语言简化了很多
如下面的代码所示:
func main() {
go fmt.Println("飞雪无情")
fmt.Println("我是 main goroutine")
time.Sleep(time.Second)
}
这样就启动了一个 goroutine,用来调用
fmt.Println函数,打印`飞雪无情”。所以这段代码里有两个 goroutine,一个是 main 函数启动的
main goroutine
- 一个是我自己通过 go 关键字启动的 goroutine。
从示例中可以总结出 go 关键字的语法,如下所示:
go function()
go 关键字后跟一个方法或者函数的调用,就可以启动一个 goroutine
- 让方法在这个新启动的 goroutine 中运行。
运行以上示例,可以看到如下输出:
我是 main goroutine
飞雪无情
从输出结果也可以看出,程序是并发的,go 关键字启动的 goroutine 并不阻塞 main goroutine 的执行
- 所以我们才会看到如上打印结果。
示例中的
time.Sleep(time.Second)表示等待一秒,这里是让 main goroutine 等一秒不然
main goroutine执行完毕程序就退出了
- 也就看不到启动的新 goroutine 中
飞雪无情的打印结果了。
Channel
那么如果启动了多个 goroutine,它们之间该如何通信呢?
- 这就是 Go 语言提供的 channel(通道)要解决的问题。
声明一个 channel
在 Go 语言中,声明一个 channel 非常简单,使用内置的 make 函数即可
如下所示:
ch:=make(chan string)
其中 chan 是一个关键字,表示是 channel 类型。
- 后面的 string 表示 channel 里的数据是 string 类型。
通过 channel 的声明也可以看到,chan 是一个集合类型。
定义好 chan 后就可以使用了,一个 chan 的操作只有两种:发送和接收。
接收:获取 chan 中的值,操作符为
<- chan。发送:向 chan 发送值,把值放在 chan 中,操作符为
chan <-。
这里注意发送和接收的操作符,都是
<-,只不过位置不同。接收的 <- 操作符在 chan 的左侧,发送的
<-操作符在 chan 的右侧。
现在我把上个示例改造下,使用 chan 来代替 time.Sleep 函数的等待工作
如下面的代码所示:
func main() {
ch:=make(chan string)
go func() {
fmt.Println("飞雪无情")
ch <- "goroutine 完成"
}()
fmt.Println("我是 main goroutine")
v:=<-ch
fmt.Println("接收到的chan中的值为:",v)
}
运行这个示例,可以发现程序并没有退出,可以看到
飞雪无情的输出结果
- 达到了
time.Sleep函数的效果如下所示:
我是 main goroutine
飞雪无情
接收到的chan中的值为: goroutine 完成
可以这样理解:在上面的示例中
- 我们在新启动的 goroutine 中向 chan 类型的变量 ch 发送值
在 main goroutine 中,从变量 ch 接收值
- 如果 ch 中没有值,则阻塞等待到 ch 中有值可以接收为止
相信你应该明白为什么程序不会在新的 goroutine 完成之前退出了
因为通过 make 创建的 chan 中没有值,而 main goroutine 又想从 chan 中获取值,获取不到就一直等待
- 等到另一个 goroutine 向 chan 发送值为止。
channel 有点像在两个 goroutine 之间架设的管道,一个 goroutine 可以往这个管道里发送数据
- 另外一个可以从这个管道里取数据,有点类似于我们说的队列。
无缓冲 channel
上面的示例中,使用 make 创建的 chan 就是一个无缓冲 channel
- 它的容量是 0,不能存储任何数据。
所以无缓冲 channel 只起到传输数据的作用,数据并不会在 channel 中做任何停留。
这也意味着,无缓冲 channel 的发送和接收操作是同时进行的
- 它也可以称为同步 channel。
有缓冲 channel
有缓冲 channel 类似一个可阻塞的队列,内部的元素先进先出。
通过 make 函数的第二个参数可以指定 channel 容量的大小
- 进而创建一个有缓冲 channel
如下面的代码所示:
cacheCh:=make(chan int,5)
我创建了一个容量为 5 的 channel,内部的元素类型是 int
- 也就是说这个 channel 内部最多可以存放 5 个类型为 int 的元素
一个有缓冲 channel 具备以下特点:
有缓冲 channel 的内部有一个缓冲队列
发送操作是向队列的尾部插入元素,如果队列已满,则阻塞等待
- 直到另一个 goroutine 执行,接收操作释放队列的空间;
接收操作是从队列的头部获取元素并把它从队列中删除
- 如果队列为空,则阻塞等待,直到另一个 goroutine 执行,发送操作插入新的元素。
因为有缓冲 channel 类似一个队列,可以获取它的容量和里面元素的个数。
如下面的代码所示:
cacheCh:=make(chan int,5)
cacheCh <- 2
cacheCh <- 3
fmt.Println("cacheCh容量为:",cap(cacheCh),",元素个数为:",len(cacheCh))
其中,通过内置函数 cap 可以获取 channel 的容量,也就是最大能存放多少个元素
- 通过内置函数 len 可以获取 channel 中元素的个数。
无缓冲 channel 其实就是一个容量大小为 0 的 channel。
比如
make(chan int,0)。
关闭 channel
channel 还可以使用内置函数 close 关闭,如下面的代码所示:
close(cacheCh)
如果一个 channel 被关闭了,就不能向里面发送数据了,如果发送的话,会引起 painc 异常。
但是还可以接收 channel 里的数据
- 如果 channel 里没有数据的话,接收的数据是元素类型的零值。
单向 channel
有时候,我们有一些特殊的业务需求,比如限制一个 channel 只可以接收但是不能发送
- 或者限制一个 channel 只能发送但不能接收,这种 channel 称为单向 channel。
单向 channel 的声明也很简单,只需要在声明的时候带上 <- 操作符即可
如下面的代码所示:
onlySend := make(chan<- int)
onlyReceive:=make(<-chan int)
注意,声明单向 channel <- 操作符的位置和上面讲到的发送和接收操作是一样的。
在函数或者方法的参数中,使用单向 channel 的较多
- 这样可以防止一些操作影响了 channel。
下面示例中的 counter 函数,它的参数 out 是一个只能发送的 channel
所以在 counter 函数体内使用参数 out 时,只能对其进行发送操作
- 如果执行接收操作,则程序不能编译通过。
func counter(out chan<- int) {
//函数内容使用变量out,只能进行发送操作
}
select+channel 示例
假设要从网上下载一个文件,我启动了 3 个 goroutine 进行下载
并把结果发送到 3 个 channel 中。其中,哪个先下载好
- 就会使用哪个 channel 的结果。
在这种情况下,如果我们尝试获取第一个 channel 的结果,程序就会被阻塞
- 无法获取剩下两个 channel 的结果,也无法判断哪个先下载好。
这个时候就需要用到多路复用操作了,在 Go 语言中,通过 select 语句可以实现多路复用
其语句格式如下:
select {
case i1 = <-c1:
//todo
case c2 <- i2:
//todo
default:
// default todo
}
整体结构和 switch 非常像,都有 case 和 default
- 只不过 select 的 case 是一个个可以操作的 channel。
多路复用可以简单地理解为,N 个 channel 中,任意一个 channel 有数据产生
- select 都可以监听到,然后执行相应的分支,接收数据并处理。
有了 select 语句,就可以实现下载的例子了。
如下面的代码所示:
func main() {
//声明三个存放结果的channel
firstCh := make(chan string)
secondCh := make(chan string)
threeCh := make(chan string)
//同时开启3个goroutine下载
go func() {
firstCh <- downloadFile("firstCh")
}()
go func() {
secondCh <- downloadFile("secondCh")
}()
go func() {
threeCh <- downloadFile("threeCh")
}()
//开始select多路复用,哪个channel能获取到值,
//就说明哪个最先下载好,就用哪个。
select {
case filePath := <-firstCh:
fmt.Println(filePath)
case filePath := <-secondCh:
fmt.Println(filePath)
case filePath := <-threeCh:
fmt.Println(filePath)
}
}
func downloadFile(chanName string) string {
//模拟下载文件,可以自己随机time.Sleep点时间试试
time.Sleep(time.Second)
return chanName+":filePath"
}
如果这些 case 中有一个可以执行,select 语句会选择该 case 执行
- 如果同时有多个 case 可以被执行,则随机选择一个
这样每个 case 都有平等的被执行的机会。
如果一个 select 没有任何 case,那么它会一直等待下去。
同步原语
资源竞争
在一个
goroutine中,如果分配的内存没有被其他 goroutine 访问
- 只在该
goroutine中被使用,那么不存在资源竞争的问题。
但如果同一块内存被多个
goroutine同时访问
- 就会产生不知道谁先访问也无法预料最后结果的情况,这就是资源竞争
- 这块内存可以称为共享的资源。
//共享的资源
var sum = 0
func main() {
//开启100个协程让sum+10
for i := 0; i < 100; i++ {
go add(10)
}
//防止提前退出
time.Sleep(2 * time.Second)
fmt.Println("和为:",sum)
}
func add(i int) {
sum += i
}
示例中,你期待的结果可能是
和为 1000,但当运行程序后,可能如预期所示
- 但也可能是 990 或者 980。
导致这种情况的核心原因是资源 sum 不是并发安全的
- 因为同时会有多个协程交叉执行 sum+=i,产生不可预料的结果。
既然已经知道了原因,解决的办法也就有了
- 只需要确保同时只有一个协程执行
sum+=i操作即可。要达到该目的,可以使用
sync.Mutex互斥锁。
使用 go build、go run、go test 这些 Go 语言工具链提供的命令时
- 添加
-race标识可以帮你检查 Go 语言代码是否存在资源竞争。
sync.Mutex
互斥锁,顾名思义,指的是在同一时刻只有一个协程执行某段代码
- 其他协程都要等待该协程执行完毕后才能继续执行。
在下面的示例中,我声明了一个互斥锁 mutex
- 然后修改 add 函数,对 sum+=i 这段代码加锁保护。
这样这段访问共享资源的代码片段就并发安全了,可以得到正确的结果。
var(
sum int
mutex sync.Mutex
)
func add(i int) {
mutex.Lock()
sum += i
mutex.Unlock()
}
以上被加锁保护的 sum+=i 代码片段又称为临界区。
在同步的程序设计中,临界区段指的是一个访问共享资源的程序片段
- 而这些共享资源又有无法同时被多个协程访问的特性。
当有协程进入临界区段时,其他协程必须等待,这样就保证了临界区的并发安全。
互斥锁的使用非常简单
- 它只有两个方法 Lock 和 Unlock,代表加锁和解锁。
当一个协程获得 Mutex 锁后
- 其他协程只能等到 Mutex 锁释放后才能再次获得锁。
Mutex 的 Lock 和 Unlock 方法总是成对出现,而且要确保 Lock 获得锁后,一定执行 UnLock 释放锁
- 所以在函数或者方法中会采用 defer 语句释放锁
如下面的代码所示:
func add(i int) {
mutex.Lock()
defer mutex.Unlock()
sum += i
}
这样可以确保锁一定会被释放,不会被遗忘。
sync.RWMutex
在
sync.Mutex中,我对共享资源 sum 的加法操作进行了加锁
- 这样可以保证在修改 sum 值的时候是并发安全的。
如果读取操作也采用多个协程呢?如下面的代码所示:
func main() {
for i := 0; i < 100; i++ {
go add(10)
}
for i:=0; i<10;i++ {
go fmt.Println("和为:",readSum())
}
time.Sleep(2 * time.Second)
}
//增加了一个读取sum的函数,便于演示并发
func readSum() int {
b:=sum
return b
}
这个示例开启了 10 个协程,它们同时读取 sum 的值。
因为 readSum 函数并没有任何加锁控制,所以它不是并发安全的
即一个 goroutine 正在执行 sum+=i 操作的时候
另一个 goroutine 可能正在执行
b:=sum操作这就会导致读取的 num 值是一个过期的值,结果不可预期。
如果要解决以上资源竞争的问题,可以使用互斥锁
sync.Mutex如下面的代码所示:
func readSum() int {
mutex.Lock()
defer mutex.Unlock()
b:=sum
return b
}
因为 add 和 readSum 函数使用的是同一个 sync.Mutex,所以它们的操作是互斥的
也就是一个 goroutine 进行修改操作 sum+=i 的时候
- 另一个 gouroutine 读取 sum 的操作
b:=sum会等待,直到修改操作执行完毕。
现在我们解决了多个 goroutine 同时读写的资源竞争问题,但是又遇到另外一个问题——性能。
因为每次读写共享资源都要加锁,所以性能低下,这该怎么解决呢?
现在我们分析读写这个特殊场景,有以下几种情况:
写的时候不能同时读,因为这个时候读取的话可能读到脏数据(不正确的数据)
读的时候不能同时写,因为也可能产生不可预料的结果
读的时候可以同时读,因为数据不会改变
- 所以不管多少个 goroutine 读都是并发安全的。
所以就可以通过读写锁
sync.RWMutex来优化这段代码,提升性能。现在我将以上示例改为读写锁,来实现我们想要的结果,如下所示:
var mutex sync.RWMutex
func readSum() int {
//只获取读锁
mutex.RLock()
defer mutex.RUnlock()
b:=sum
return b
}
对比互斥锁的示例,读写锁的改动有两处:
把锁的声明换成读写锁
sync.RWMutex。把函数 readSum 读取数据的代码换成读锁,也就是 RLock 和 RUnlock。
这样性能就会有很大的提升,因为多个 goroutine 可以同时读数据,不再相互等待。
sync.WaitGroup
在以上示例中,相信你注意到了这段
time.Sleep(2 * time.Second)代码
- 这是为了防止主函数 main 返回使用,一旦 main 函数返回了,程序也就退出了。
因为我们不知道 100 个执行 add 的协程和 10 个执行 readSum 的协程什么时候完全执行完毕
- 所以设置了一个比较长的等待时间,也就是两秒。
小提示:一个函数或者方法的返回 (return) 也就意味着当前函数执行完毕。
所以存在一个问题,如果这 110 个协程在两秒内执行完毕,main 函数本该提前返回
- 但是偏偏要等两秒才能返回,会产生性能问题。
如果这 110 个协程执行的时间超过两秒,因为设置的等待时间只有两秒,程序就会提前返回
- 导致有协程没有执行完毕,产生不可预知的结果。
那么有没有办法解决这个问题呢?也就是说有没有办法监听所有协程的执行,一旦全部执行完毕,程序马上退出
- 这样既可保证所有协程执行完毕,又可以及时退出节省时间,提升性能。
没错,channel 的确可以解决这个问题,不过非常复杂,Go 语言为我们提供了更简洁的解决办法
- 它就是
sync.WaitGroup。
在使用
sync.WaitGroup改造示例之前,我先把 main 函数中的代码进行重构,抽取成一个函数 run这样可以更好地理解,如下所示:
func main() {
run()
}
func run(){
for i := 0; i < 100; i++ {
go add(10)
}
for i:=0; i<10;i++ {
go fmt.Println("和为:",readSum())
}
time.Sleep(2 * time.Second)
}
这样执行读写的 110 个协程代码逻辑就都放在了 run 函数中
在 main 函数中直接调用 run 函数即可。
现在只需通过
sync.WaitGroup对 run 函数进行改造,让其恰好执行完毕,如下所示:
func run(){
var wg sync.WaitGroup
//因为要监控110个协程,所以设置计数器为110
wg.Add(110)
for i := 0; i < 100; i++ {
go func() {
//计数器值减1
defer wg.Done()
add(10)
}()
}
for i:=0; i<10;i++ {
go func() {
//计数器值减1
defer wg.Done()
fmt.Println("和为:",readSum())
}()
}
//一直等待,只要计数器值为0
wg.Wait()
}
sync.WaitGroup的使用比较简单,一共分为三步:
声明一个
sync.WaitGroup,然后通过 Add 方法设置计数器的值
- 需要跟踪多少个协程就设置多少,这里是 110
在每个协程执行完毕时调用 Done 方法,让计数器减 1
- 告诉
sync.WaitGroup该协程已经执行完毕最后调用 Wait 方法一直等待,直到计数器值为 0,也就是所有跟踪的协程都执行完毕。
通过
sync.WaitGroup可以很好地跟踪协程。在协程执行完毕后
- 整个 run 函数才能执行完毕,时间不多不少,正好是协程执行的时间。
sync.WaitGroup适合协调多个协程共同做一件事情的场景比如下载一个文件,假设使用 10 个协程,每个协程下载文件的 1⁄10 大小
- 只有 10 个协程都下载好了整个文件才算是下载好了。
这就是我们经常听到的多线程下载,通过多个线程共同做一件事情,显著提高效率。
小提示:
其实你也可以把 Go 语言中的协程理解为平常说的线程
- 从用户体验上也并无不可,但是从技术实现上,你知道他们是不一样的就可以了。
sync.Once
在实际的工作中,你可能会有这样的需求:
- 让代码只执行一次,哪怕是在高并发的情况下,比如创建一个单例。
针对这种情形,Go 语言为我们提供了
sync.Once来保证代码只执行一次,如下所示:
func main() {
doOnce()
}
func doOnce() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
//用于等待协程执行完毕
done := make(chan bool)
//启动10个协程执行once.Do(onceBody)
for i := 0; i < 10; i++ {
go func() {
//把要执行的函数(方法)作为参数传给once.Do方法即可
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
这是 Go 语言自带的一个示例,虽然启动了 10 个协程来执行 onceBody 函数
- 但是因为用了
once.Do方法,所以函数 onceBody 只会被执行一次。也就是说在高并发的情况下,sync.Once 也会保证 onceBody 函数只执行一次。
sync.Once适用于创建某个对象的单例、只加载一次的资源等只执行一次的场景。
sync.Cond
在 Go 语言中,
sync.WaitGroup用于最终完成的场景
- 关键点在于一定要等待所有协程都执行完毕。
而
sync.Cond可以用于发号施令,一声令下所有协程都可以开始执行
- 关键点在于协程开始的时候是等待的,要等待
sync.Cond唤醒才能执行。
sync.Cond从字面意思看是条件变量,它具有阻塞协程和唤醒协程的功能
- 所以可以在满足一定条件的情况下唤醒协程,但条件变量只是它的一种使用场景。
下面我以 10 个人赛跑为例来演示
sync.Cond的用法。在这个示例中有一个裁判,裁判要先等这 10 个人准备就绪,然后一声发令枪响
这 10 个人就可以开始跑了,如下所示:
//10个人赛跑,1个裁判发号施令
func race(){
cond :=sync.NewCond(&sync.Mutex{})
var wg sync.WaitGroup
wg.Add(11)
for i:=0;i<10; i++ {
go func(num int) {
defer wg.Done()
fmt.Println(num,"号已经就位")
cond.L.Lock()
cond.Wait()//等待发令枪响
fmt.Println(num,"号开始跑……")
cond.L.Unlock()
}(i)
}
//等待所有goroutine都进入wait状态
time.Sleep(2*time.Second)
go func() {
defer wg.Done()
fmt.Println("裁判已经就位,准备发令枪")
fmt.Println("比赛开始,大家准备跑")
cond.Broadcast()//发令枪响
}()
//防止函数提前返回退出
wg.Wait()
}
以上示例中有注释说明,已经很好理解,我这里再大概讲解一下步骤:
通过
sync.NewCond函数生成一个*sync.Cond,用于阻塞和唤醒协程然后启动 10 个协程模拟 10 个人,准备就位后调用
cond.Wait()方法阻塞当前协程等待发令枪响
- 这里需要注意的是调用
cond.Wait()方法时要加锁
time.Sleep用于等待所有人都进入 wait 阻塞状态
- 这样裁判才能调用
cond.Broadcast()发号施令裁判准备完毕后,就可以调用
cond.Broadcast()通知所有人开始跑了。
sync.Cond 有三个方法,它们分别是:
Wait
- 阻塞当前协程,直到被其他协程调用 Broadcast 或者 Signal 方法唤醒
- 使用的时候需要加锁,使用
sync.Cond中的锁即可,也就是 L 字段。Signal
唤醒一个等待时间最长的协程。
Broadcast
唤醒所有等待的协程。
注意:
在调用 Signal 或者 Broadcast 之前
- 要确保目标协程处于 Wait 阻塞状态,不然会出现死锁问题。
如果你以前学过 Java,会发现 sync.Cond 和 Java 的等待唤醒机制很像
- 它的三个方法 Wait、Signal、Broadcast 就分别对应 Java 中的 wait、notify、notifyAll。
指针详解
什么是指针
我们都知道程序运行时的数据是存放在内存中的,而内存会被抽象为一系列具有连续编号的存储空间
那么每一个存储在内存中的数据都会有一个编号,这个编号就是内存地址。
- 有了这个内存地址就可以找到这个内存中存储的数据,而内存地址可以被赋值给一个指针。
小提示:
内存地址通常为 16 进制的数字表示,比如 0x45b876。
可以总结为:
在编程语言中,指针是一种数据类型,用来存储一个内存地址,该地址指向存储在该内存中的对象。
- 这个对象可以是字符串、整数、函数或者你自定义的结构体。
小技巧:
你也可以简单地把指针理解为内存地址。
举个通俗的例子,每本书中都有目录,目录上会有相应章节的页码,你可以把页码理解为一系列的内存地址
- 通过页码你可以快速地定位到具体的章节(也就是说,通过内存地址可以快速地找到存储的数据)。
指针的声明和定义
在 Go 语言中,获取一个变量的指针非常容易,使用取地址符
&就可以比如下面的例子:
func main() {
name:="飞雪无情"
nameP:=&name//取地址
fmt.Println("name变量的值为:",name)
fmt.Println("name变量的内存地址为:",nameP)
}
我在示例中定义了一个 string 类型的变量 name,它的值为
飞雪无情然后通过取地址符 & 获取变量 name 的内存地址,并赋值给指针变量 nameP
- 该指针变量的类型为
*string。运行以上示例你可以看到如下打印结果:
name变量的值为: 飞雪无情
name变量的内存地址为: 0xc000010200
这一串 0xc000010200 就是内存地址
- 这个内存地址可以赋值给指针变量 nameP。
指针类型非常廉价,只占用 4 个或者 8 个字节的内存大小。
以上示例中 nameP 指针的类型是
*string,用于指向 string 类型的数据。
- 在 Go 语言中使用类型名称前加 * 的方式,即可表示一个对应的指针类型。
比如 int 类型的指针类型是
*int,float64 类型的指针类型是*float64
- 自定义结构体 A 的指针类型是
*A。总之,指针类型就是在对应的类型前加
*号。
下面通过一个图让你更好地理解普通类型变量、指针类型变量、内存地址、内存等之间的关系。
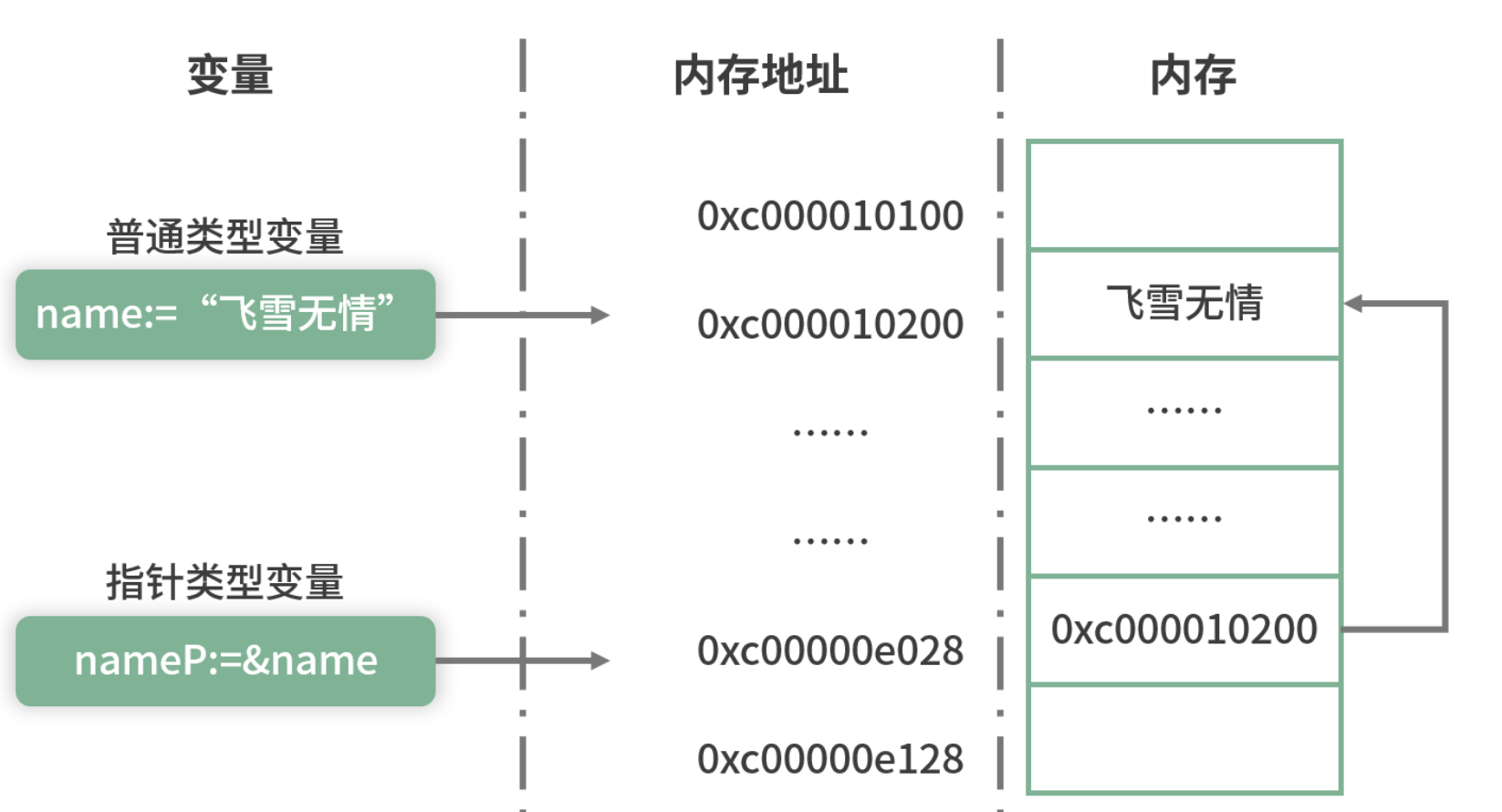
上图就是我刚举的例子所对应的示意图
- 从图中可以看到普通变量 name 的值
飞雪无情被放到内存地址为 0xc000010200 的内存块中。指针类型变量也是变量,它也需要一块内存用来存储值
- 这块内存对应的地址就是 0xc00000e028,存储的值是 0xc000010200。
指针变量 nameP 的值正好是普通变量 name 的内存地址,所以就建立指向关系。
小提示:
指针变量的值就是它所指向数据的内存地址,普通变量的值就是我们具体存放的数据。
不同的指针类型是无法相互赋值的
比如你不能对一个 string 类型的变量取地址然后赋值给
*int指针类型编译器会提示你
Cannot use ‘&name’ (type *string) as type *int in assignment。
此外,除了可以通过简短声明的方式声明一个指针类型的变量外
也可以使用 var 关键字声明
- 如下面示例中的
var intP *int就声明了一个*int类型的变量 intP。
var intP *int
intP = &name //指针类型不同,无法赋值
可以看到指针变量也和普通的变量一样
- 既可以通过 var 关键字定义,也可以通过简短声明定义。
小提示:
通过 var 声明的指针变量是不能直接赋值和取值的
- 因为这时候它仅仅是个变量,还没有对应的内存地址,它的值是 nil。
和普通类型不一样的是,指针类型还可以通过内置的 new 函数来声明
如下所示:
intP1:=new(int)
内置的 new 函数有一个参数,可以传递类型给它。
- 它会返回对应的指针类型,比如上述示例中会返回一个
*int类型的 intP1。
指针的操作
在 Go 语言中指针的操作无非是两种:
- 一种是获取指针指向的值,一种是修改指针指向的值。
首先介绍如何获取,我用下面的代码进行演示:
nameV:=*nameP
fmt.Println("nameP指针指向的值为:",nameV)
可以看到,要获取指针指向的值,只需要在指针变量前加 * 号即可
- 获得的变量 nameV 的值就是
飞雪无情,方法比较简单。修改指针指向的值也非常简单,比如下面的例子:
*nameP = "公众号:飞雪无情" //修改指针指向的值
fmt.Println("nameP指针指向的值为:",*nameP)
fmt.Println("name变量的值为:",name)
对
*nameP赋值等于修改了指针 nameP 指向的值。运行程序你将看到如下打印输出:
nameP指针指向的值为: 公众号:飞雪无情
name变量的值为: 公众号:飞雪无情
通过打印结果可以看到,不光 nameP 指针指向的值被改变了
- 变量 name 的值也被改变了,这就是指针的作用。
因为变量 name 存储数据的内存就是指针 nameP 指向的内存
- 这块内存被 nameP 修改后,变量 name 的值也被修改了。
我们已经知道,通过 var 关键字直接定义的指针变量是不能进行赋值操作的
- 因为它的值为 nil,也就是还没有指向的内存地址。
比如下面的示例:
var intP *int
*intP =10
运行的时候会提示
invalid memory address or nil pointer dereference。这时候该怎么办呢?
- 其实只需要通过 new 函数给它分配一块内存就可以了
如下所示:
var intP *int = new(int)
//更推荐简短声明法,这里是为了演示
//intP:=new(int)
指针参数
假如有一个函数 modifyAge,想要用来修改年龄,如下面的代码所示。
但运行它,你会看到 age 的值并没有被修改,还是 18,并没有变成 20。
age:=18
modifyAge(age)
fmt.Println("age的值为:",age)
func modifyAge(age int) {
age = 20
}
导致这种结果的原因是 modifyAge 中的 age 只是实参 age 的一份拷贝
- 所以修改它不会改变实参 age 的值。
如果要达到修改年龄的目的,就需要使用指针,现在对刚刚的示例进行改造
如下所示:
age:=18
modifyAge(&age)
fmt.Println("age的值为:",age)
func modifyAge(age *int) {
*age = 20
}
也就是说,当你需要在函数中通过形参改变实参的值时,需要使用指针类型的参数。
指针接收者
对于是否使用指针类型作为接收者,有以下几点参考:
如果接收者类型是 map、slice、channel 这类引用类型,不使用指针;
如果需要修改接收者,那么需要使用指针;
如果接收者是比较大的类型,可以考虑使用指针,因为内存拷贝廉价,所以效率高。
所以对于是否使用指针类型作为接收者,还需要你根据实际情况考虑。
什么情况下使用指针
从以上指针的详细分析中,我们可以总结出指针的两大好处:
可以修改指向数据的值;
在变量赋值,参数传值的时候可以节省内存。
参数传递
修改参数
假设你定义了一个函数,并在函数里对参数进行修改
- 想让调用者可以通过参数获取你最新修改的值。
func main() {
p:=person{name: "张三",age: 18}
modifyPerson(p)
fmt.Println("person name:",p.name,",age:",p.age)
}
func modifyPerson(p person) {
p.name = "李四"
p.age = 20
}
type person struct {
name string
age int
}
在这个示例中,我期望通过
modifyPerson函数把参数 p 中的 name 修改为李四
- 把 age 修改为 20。
代码没有错误,但是运行一下,你会看到如下打印输出:
person name: 张三 ,age: 18
怎么还是张三与 18 呢?我换成指针参数试试,如下所示:
modifyPerson(&p)
func modifyPerson(p *person) {
p.name = "李四"
p.age = 20
}
这些代码用于满足指针参数的修改,把接收的参数改为指针参数
- 以及在调用 modifyPerson 函数时,通过
&取地址符传递一个指针。现在再运行程序,就可以看到期望的输出了,如下所示:
person name: 李四 ,age: 20
值类型
在 Go 语言中,person 是一个值类型,而
&p获取的指针是*person类型的
- 即指针类型。
那么为什么值类型在参数传递中无法修改呢?
- 这也要从内存讲起。
内存都有一个编号,称为内存地址。
所以要想修改内存中的数据,就要找到这个内存地址。
现在,我来对比值类型变量在函数内外的内存地址,如下所示:
func main() {
p:=person{name: "张三",age: 18}
fmt.Printf("main函数:p的内存地址为%p\n",&p)
modifyPerson(p)
fmt.Println("person name:",p.name,",age:",p.age)
}
func modifyPerson(p person) {
fmt.Printf("modifyPerson函数:p的内存地址为%p\n",&p)
p.name = "李四"
p.age = 20
}
其中,我把原来的示例代码做了更改,分别打印出在 main 函数中变量 p 的内存地址
- 以及在 modifyPerson 函数中参数 p 的内存地址。
运行以上程序,可以看到如下结果:
main函数:p的内存地址为0xc0000a6020
modifyPerson函数:p的内存地址为0xc0000a6040
person name: 张三 ,age: 18
你会发现它们的内存地址都不一样
这就意味着,在
modifyPerson函数中修改的参数 p 和 main 函数中的变量 p 不是同一个
- 这也是我们在 modifyPerson 函数中修改参数 p
- 但是在 main 函数中打印后发现并没有修改的原因。
导致这种结果的原因是
- Go 语言中的函数传参都是值传递。
值传递指的是传递原来数据的一份拷贝,而不是原来的数据本身。
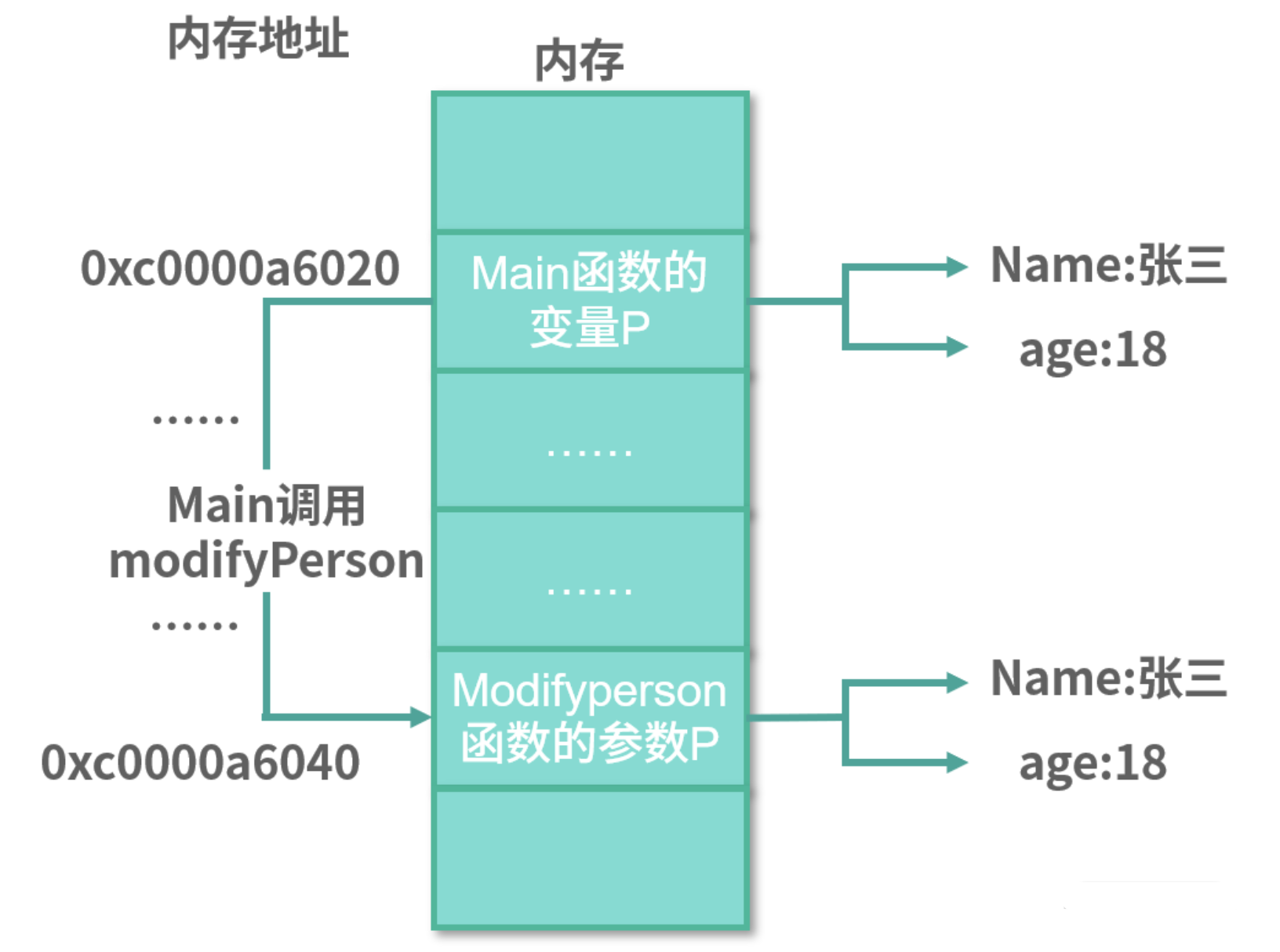
以 modifyPerson 函数来说,在调用 modifyPerson 函数传递变量 p 的时候
- Go 语言会拷贝一个 p 放在一个新的内存中
这样新的 p 的内存地址就和原来不一样了
- 但是里面的 name 和 age 是一样的,还是张三和 18。
这就是副本的意思,变量里的数据一样,但是存放的内存地址不一样。
除了 struct 外,还有浮点型、整型、字符串、布尔、数组,这些都是值类型。
指针类型
指针类型的变量保存的值就是数据对应的内存地址
- 所以在函数参数传递是传值的原则下,拷贝的值也是内存地址。
现在对以上示例稍做修改,修改后的代码如下:
func main() {
p:=person{name: "张三",age: 18}
fmt.Printf("main函数:p的内存地址为%p\n",&p
modifyPerson(&p)
fmt.Println("person name:",p.name,",age:",p.age)
}
func modifyPerson(p *person) {
fmt.Printf("modifyPerson函数:p的内存地址为%p\n",p)
p.name = "李四"
p.age = 20
}
运行这个示例,你会发现打印出的内存地址一致,并且数据也被修改成功了,如下所示:
main函数:p的内存地址为0xc0000a6020
modifyPerson函数:p的内存地址为0xc0000a6020
person name: 李四 ,age: 20
所以指针类型的参数是永远可以修改原数据的
- 因为在参数传递时,传递的是内存地址。
小提示:
值传递的是指针,也是内存地址。通过内存地址可以找到原数据的那块内存
- 所以修改它也就等于修改了原数据。
引用类型
map
对于上面的例子,假如我不使用自定义的 person 结构体和指针
能不能用 map 达到修改的目的呢?
func main() {
m:=make(map[string]int)
m["飞雪无情"] = 18
fmt.Println("飞雪无情的年龄为",m["飞雪无情"])
modifyMap(m)
fmt.Println("飞雪无情的年龄为",m["飞雪无情"])
}
func modifyMap(p map[string]int) {
p["飞雪无情"] =20
}
我定义了一个
map[string]int类型的变量 m
- 存储一个 Key 为飞雪无情、Value 为 18 的键值对
然后把这个变量 m 传递给函数 modifyMap。
- modifyMap 函数所做的事情就是把对应的值修改为 20。
现在运行这段代码,通过打印输出来看是否修改成功,结果如下所示:
飞雪无情的年龄为 18
飞雪无情的年龄为 20
确实修改成功了。你是不是有不少疑惑?没有使用指针,只是用了 map 类型的参数
按照 Go 语言值传递的原则
- modifyMap 函数中的 map 是一个副本,怎么会修改成功呢?
要想解答这个问题,就要从 make 这个 Go 语言内建的函数说起。
在 Go 语言中,任何创建 map 的代码(不管是字面量还是 make 函数)
- 最终调用的都是 runtime.makemap 函数。
小提示:
用字面量或者 make 函数的方式创建 map,并转换成 makemap 函数的调用
- 这个转换是 Go 语言编译器自动帮我们做的。
从下面的代码可以看到,makemap 函数返回的是一个
*hmap 类型
- 也就是说返回的是一个指针,所以我们创建的 map 其实就是一个
*hmap。
// makemap implements Go map creation for make(map[k]v, hint).
func makemap(t *maptype, hint int, h *hmap) *hmap{
//省略无关代码
}
因为 Go 语言的 map 类型本质上就是 *hmap,所以根据替换的原则
我刚刚定义的
modifyMap(p map)函数其实就是modifyMap(p *hmap)。
- 这是不是和上一小节讲的指针类型的参数调用一样了?
这也是通过 map 类型的参数可以修改原始数据的原因,因为它本质上就是个指针。
为了进一步验证创建的 map 就是一个指针
- 我修改上述示例,打印 map 类型的变量和参数对应的内存地址
如下面的代码所示:
func main(){
//省略其他没有修改的代码
fmt.Printf("main函数:m的内存地址为%p\n",m)
}
func modifyMap(p map[string]int) {
fmt.Printf("modifyMap函数:p的内存地址为%p\n",p)
//省略其他没有修改的代码
}
例子中的两句打印代码是新增的,其他代码没有修改,这里就不再贴出来了。
运行修改后的程序,你可以看到如下输出:
飞雪无情的年龄为 18
main函数:m的内存地址为0xc000060180
modifyMap函数:p的内存地址为0xc000060180
飞雪无情的年龄为 20
从输出结果可以看到,它们的内存地址一模一样,所以才可以修改原始数据,得到年龄是 20 的结果。
而且我在打印指针的时候,直接使用的是变量 m 和 p,并没有用到取地址符 &
- 这是因为它们本来就是指针,所以就没有必要再使用 & 取地址了。
所以在这里,Go 语言通过 make 函数或字面量的包装为我们省去了指针的操作
- 让我们可以更容易地使用 map。其实就是语法糖,这是编程界的老传统了。
注意:这里的 map 可以理解为引用类型,但是它本质上是个指针,只是可以叫作引用类型而已。
- 在参数传递时,它还是值传递,并不是其他编程语言中所谓的引用传递。
chan
它也可以理解为引用类型,而它本质上也是个指针。
通过下面的源代码可以看到,所创建的 chan 其实是个
*hchan
- 所以它在参数传递中也和 map 一样。
func makechan(t *chantype, size int64) *hchan {
//省略无关代码
}
严格来说,Go 语言没有引用类型
- 但是我们可以把 map、chan 称为引用类型,这样便于理解。
除了 map、chan 之外,Go 语言中的函数、接口、slice 切片都可以称为引用类型。
小提示:指针类型也可以理解为是一种引用类型。
类型的零值
在 Go 语言中,定义变量要么通过声明、要么通过 make 和 new 函数
- 不一样的是 make 和 new 函数属于显式声明并初始化。
如果我们声明的变量没有显式声明初始化,那么该变量的默认值就是对应类型的零值。
从下面的表格可以看到,可以称为引用类型的零值都是 nil。
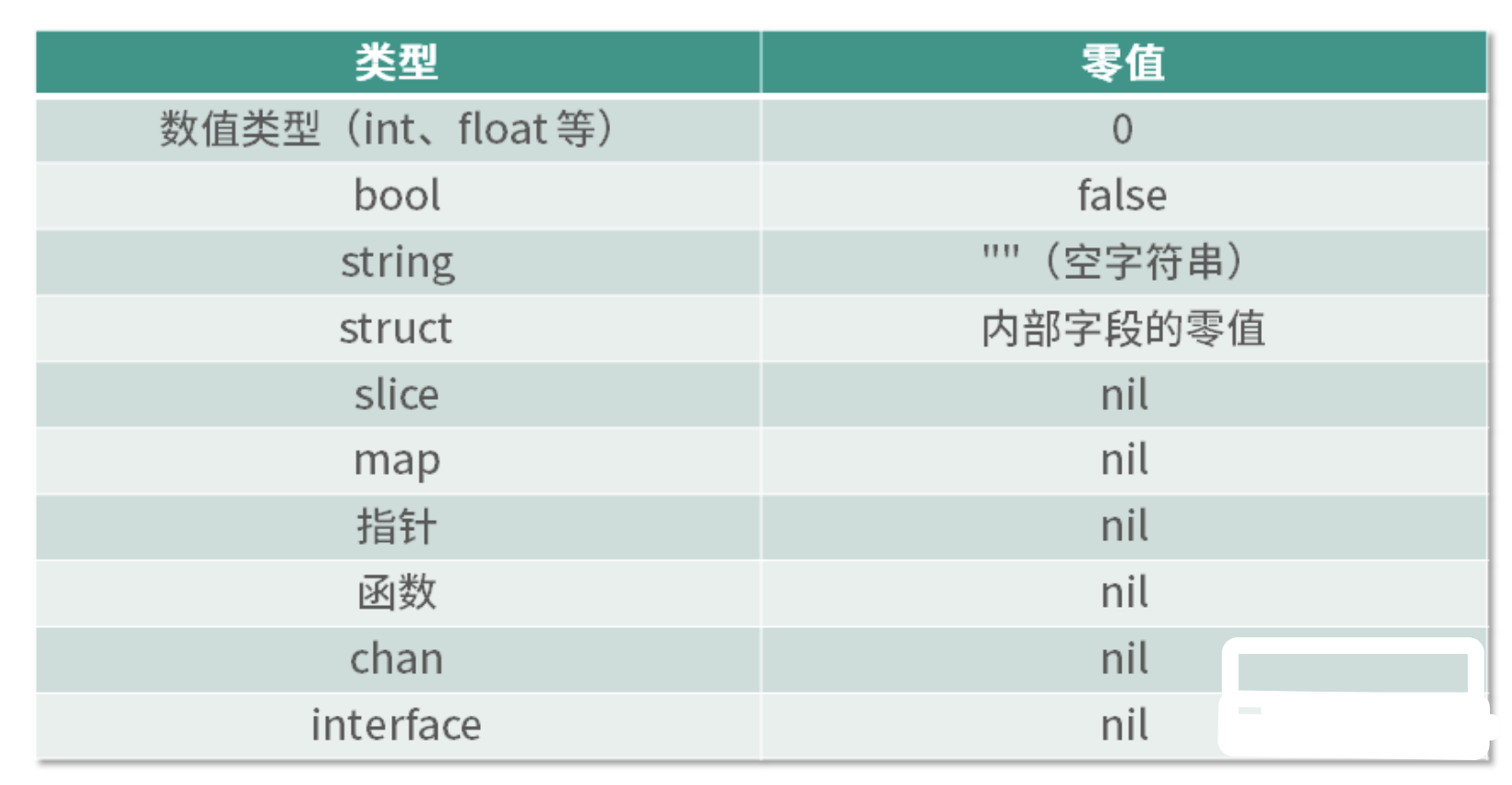
内存分配
Go 语言程序所管理的虚拟内存空间会被分为两部分:
- 堆内存和栈内存。
栈内存主要由 Go 语言来管理,开发者无法干涉太多,堆内存才是开发者发挥能力的舞台
- 因为程序的数据大部分分配在堆内存上,一个程序的大部分内存占用也是在堆内存上。
小提示:
- 我们常说的 Go 语言的内存垃圾回收是针对堆内存的垃圾回收。
变量的声明、初始化就涉及内存的分配
- 比如声明变量会用到 var 关键字,如果要对变量初始化,就会用到 = 赋值运算符。
new 函数只用于分配内存,并且把内存清零,也就是返回一个指向对应类型零值的指针。
- new 函数一般用于需要显式地返回指针的情况,不是太常用。
make 函数只用于 slice、chan 和 map 这三种内置类型的创建和初始化
因为这三种类型的结构比较复杂
- 比如 slice 要提前初始化好内部元素的类型
- slice 的长度和容量等,这样才可以更好地使用它们。
make 函数
在使用 make 函数创建 map 的时候,其实调用的是 makemap 函数
如下所示:
// makemap implements Go map creation for make(map[k]v, hint).
func makemap(t *maptype, hint int, h *hmap) *hmap{
//省略无关代码
}
makemap 函数返回的是
*hmap类型
- 而 hmap 是一个结构体
它的定义如下面的代码所示:
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
可以看到,平时使用的 map 关键字其实非常复杂
- 它包含 map 的大小 count、存储桶 buckets 等。
要想使用这样的 hmap,不是简单地通过 new 函数返回一个
*hmap就可以
- 还需要对其进行初始化,这就是 make 函数要做的事情
如下所示:
m:=make(map[string]int,10)
是不是发现 make 函数和上一小节中自定义的 NewPerson 函数很像?
其实 make 函数就是 map 类型的工厂函数
- 它可以根据传递它的 K-V 键值对类型,创建不同类型的 map
- 同时可以初始化 map 的大小。
小提示:
make 函数不只是 map 类型的工厂函数,还是 chan、slice 的工厂函数。
它同时可以用于 slice、chan 和 map 这三种类型的初始化。
new 函数
func main() {
var sp *string
sp = new(string)//关键点
*sp = "飞雪无情"
fmt.Println(*sp)
}
以上代码的关键点在于通过内置的 new 函数生成了一个
*string,并赋值给了变量 sp。现在再运行程序就正常了。
内置函数 new 的作用是什么呢?
可以通过它的源代码定义分析,如下所示:
// The new built-in function allocates memory. The first argument is a type,
// not a value, and the value returned is a pointer to a newly
// allocated zero value of that type.
func new(Type) *Type
它的作用就是根据传入的类型申请一块内存
- 然后返回指向这块内存的指针,指针指向的数据就是该类型的零值。
比如传入的类型是 string,那么返回的就是 string 指针
- 这个 string 指针指向的数据就是空字符串
如下所示:
sp1 = new(string)
fmt.Println(*sp1)//打印空字符串,也就是string的零值。
通过 new 函数分配内存并返回指向该内存的指针后
- 就可以通过该指针对这块内存进行赋值、取值等操作。