 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
基础知识
官方网站:
中文网在线标准库文档:
Google创造Go语言的目的:
计算机硬件技术更新频繁:
- 性能提高很快,目前主流的编程语言发展落后于硬件
- 不能合理利用多核
CPU的优势提升软件系统性能软件系统复杂度越来越高,维护成本越来越高
- 目前缺乏一个足够简洁高效的编程语言
企业运行维护很多C/C++的项目,C/C++程序运行速度很快,但是编译速度很慢
- 同时还存在内存泄漏的一系列的困扰需要解决
Go岗位
区块链研发工程师
服务器/游戏软件工程师
分布式/云计算软件工程师
Go语言特点
Go语言保证了既能够达到静态编译语言的安全和性能,又达到了动态语言开发类维护的高效率。
GO = C + Python:
- 说明Go语言既有C静态语言程序的运行速度,又能达到Python的动态语言的快速开发。
天然并发:
从语言层面支持并发,实现简单。
GoRoutine,轻量级线程,可实现大并发处理,高效利用多核。管道通信机制:
- Go语言特有的管道Channel,通过
Channel,可以实现不同的GoRoute之间的相互通信。函数返回多个值。
新的创新内容:
- 例如切片、延时执行Defer等。
安装
下载地址:https://go.dev/dl/
- 默认安装路径是
/usr/local/go
配置环境变量:
$ vim ~/.bash_profile
export GOPATH=/usr/local/go
export GOBIN=$GOPATH/bin
export PATH=$PATH:$GOBIN
$ source ~/.bash_profile
验证安装:
go version
go env
第一个Go程序
一个简单的 Go 程序文件
hello.go。
package main // package main 定义了包名。必须在源文件中非注释的第一行指明这个文件属于哪个包
import (
"fmt"
) /* import "fmt" 告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。 */
func main() { // func main() 是程序开始执行的函数(函数的入口)。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数。
/* 这是hello world的程序 */ // /*...*/ 是注释,在程序执行时将被忽略。单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾,且不可以嵌套使用,多行注释一般用于包的文档描述或注释成块的代码片段。
fmt.Println("Hello,Go World!") // fmt.Println(...) 可以将字符串输出到控制台,并在最后自动增加换行字符 \n。 Print 和 Println 这两个函数也支持使用变量
}
构建该程序:
go build hello.go
生成一个名为
hello的可执行文件,可以运行它。
./hello
使用
go install
- 不仅构建程序,还将结果文件安装到
GOPATH指定的目录中,以供全局使用。
- 通常是在
$GOPATH/bin目录下。- 可以在任何地方运行程序。
go install hello.go
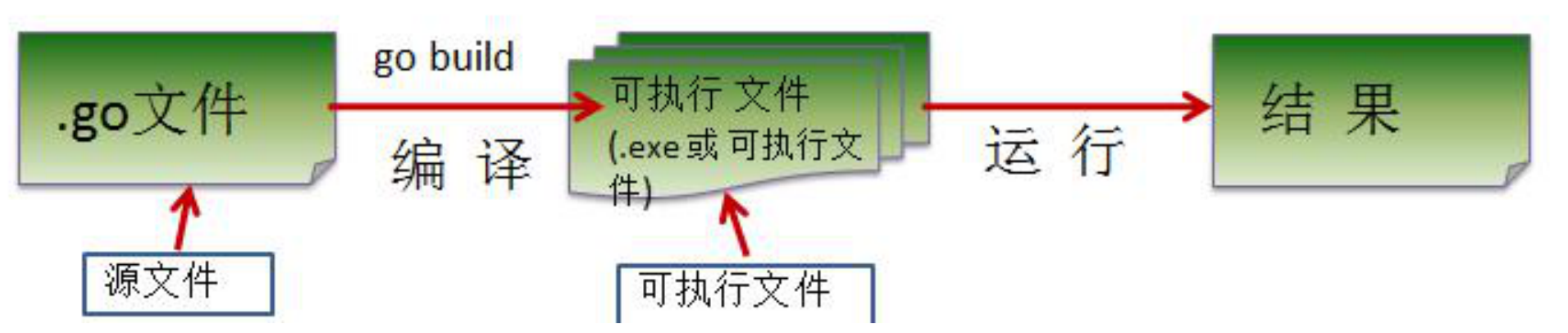
执行流程分析
如果是对源码编译后,再执行,
Go的执行流程如下图:
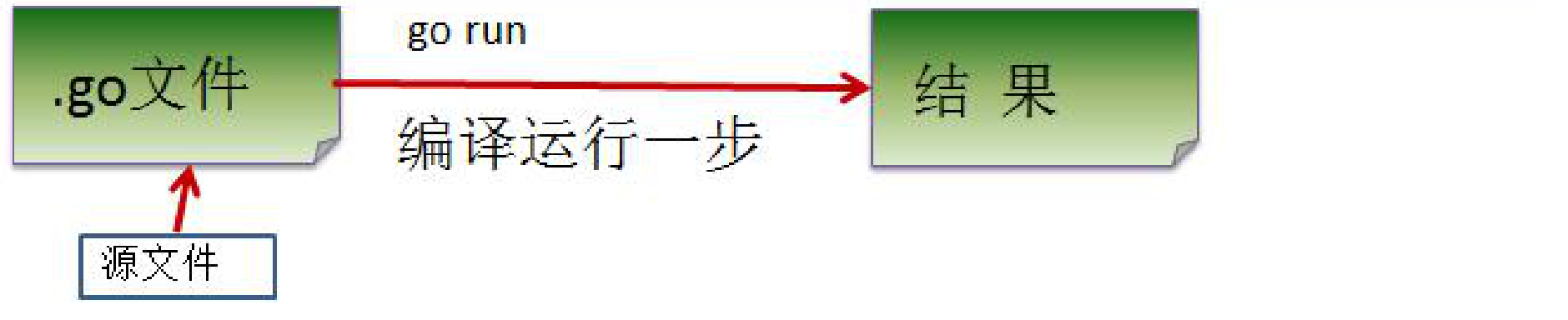
如果是对源码直接 执行
go run源码,Go 的执行流程如下图:
两种执行流程的方式区别:
- 如果先编译生成了可执行文件
- 那么可以将该可执行文件拷贝到没有 go 开发环境的机器上,仍然可以运行。
- 如果是直接
go run go源代码
- 那么如果要在另外一个机器上这么运行,也需要
go开发环境,否则无法执行。- 在编译时,编译器会将程序运行依赖的库文件包含在可执行文件中
- 所以,可执行文件变大了很多。
开发注意事项
Go 源文件以
go为扩展名。Go 应用程序的执行入口是
main()函数。Go 语言严格区分大小写。
Go 方法由一条条语句构成,每个语句后不需要分号(Go 语言会在每行后自动加分号)。
Go 编译器是一行行进行编译的
- 因此一行就写一条语句,不能把多条语句写在同一个,否则报错。
Go 语言定义的变量或者
import的包如果没有使用到,代码不能编译通过。大括号都是成对出现的,缺一不可。
通过
go run xxx.go直接运行Go代码。编译后再运行
go build xxx.go,./xxx。
标识符
命名规则:
由26个英文字母大小写,0-9,_ 组成
数字不可以开头:
var num int//这样写是OK的vat 3num int//这样是错误的Golang中严格区分大小写
标识符不能包含空格
下划线
_本身在Go中是一个特殊的标识符,称为空标识符
- 可以代表任何其他的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)
- 所以仅能被作为占位符使用,不能作为标识符使用
不能以系统保留关键字作为标识符(一共25个),比如
break , if等等命名注意事项
- 包名:保持和package的名字和目录是一样的,尽量采取用意义的包名,简短,有意义
- 不要和标准库有冲突,例如 fmt
- 变量名、函数名、常量名:采用驼峰法
- 如果变量名、函数名、常量名首字母大写,则可以被其他包访问:如果首字母小写,则只能在本包中使用
转义字符
常用的转义字符有如下:
\t: 表示一个制表符,通常使用它可以排版\n:换行符\\:一个\\":一个”\r:一个回车
package main
import "fmt" //fmt 包中提供格式化,输出,输入的函数
func main() {
//要求:请使用一句输出语句,达到输入如下图形的效果
fmt.Println("姓名\t 年龄\t 籍贯\t 地址\njohn\t20\t 河北\t 北京")
}
注释
行注释:
- // 注释内容
块注释(多行注释):
/*注释内容*/
变量
声明变量的规则:
- 以字母或下划线开头,由一个或多个字母、数字、下划线组成
关键字:var
定义变量:
- 注意Go语言变量一旦定义后续必须要用到,否则会报错
定义变量格式:
- var 变量名 变量类型
var a int
var s string
变量赋值:
- var 变量名 变量类型 = 值
- 根据值自行判定变量类型
- 在函数内第一次赋值时可以使用:=替代var来定义赋值变量(在函数外不可以)
- 编译器也可以自动决定类型
- 在函数外定义变量是包内变量(不是全局变量)
- 如果变量已经使用 var 声明过了,再使用
:=声明变量,就产生编译错误
var a int = 5
var b string = "abbc"
var c,d,e,f = 3,5,true,"def" //不需要显示声明类型,自动推断
变量赋值与其他主流语言的区别:
- 赋值可以进行自动类型推断
- 在一个赋值语句中可以对多个变量进行同时赋值
func TestExchange(t *testing.T) {
a := 1
b := 2
//定义中间变量进行变量值的互换
//tmp := a
//a = b
//b = tmp
//在Go中可以这么写
a, b = b, a
t.Log(a, b)
}
程序中+号的使用
当左右两边都是数值型时,则做加法运算
当左右两边有一方为字符串,则做拼接运算
全局变量:
- 全局变量是定义在函数外部的变量,它在程序整个运行周期内都有效
- 在函数中可以访问到全局变量。
package main
import "fmt"
//定义全局变量num
var num int64 = 10
func testGlobalVar() {
fmt.Printf("num=%d\n", num) //函数中可以访问全局变量num
}
func main() {
testGlobalVar() //num=10
}
常量
关键字
const:
- const可以作为各种类型进行使用
const a,b = 3,4
var c int = int(math.Sqrt(a*a + b*b))
变量赋值与其它主流语言的区别:
- Go语言可以快速设置连续值
const (
Monday = iota + 1
Tuesday
Wednesday
Thursday
Friday
Saturday
Sunday
)
func TestConstant(t *testing.T) {
t.Log(Thursday, Sunday) //输出结果为:4 7
}
//iota,特殊常量值,是一个系统定义的可以被编译器修改的常量值。
//iota只能被用在常量的赋值中,在每一个const关键字出现时,被重置为0,
//然后每出现一个常量,iota所代表的数值会自动增加1,
//iota可以理解成常量组中常量的计数器,不论该常量的值是什么,只要有一个常量,那么iota 就加1。
数据类型
布尔型
- 布尔型的值只可以是true或者false
数字类型
- 整型int、浮点型
float32,float64GO语言支持整型和浮点型数字
- 并且支持复数,其中位的运算采用补码
字符串类型
- 字符串就是一串固定长度的字符连接起来的字符序列。
- Go 的字符串是由单个字节连接起来的。
- Go 语言的字符串的字节使用 UTF-8 编码标识
Unicode文本。派生类型
- 指针类型(Pointer)
- 数组类型
- 结构化类型(struct)
- Channel 类型
- 函数类型
- 切片类型
- 接口类型(interface)
- Map 类型
零值(初始值)
- 当一个变量或者新值被创建时,如果没有为其明确指定初始值。
- Go语言会自动初始化其值为此类型对应的零值,各类型零值如下:
- bool:false
- integer:0
- float:0.0
- string:
""pointer, function, interface, slice, channel, map:nil- 对于复合类型,Go语言会自动递归地将每一个元素初始化为其类型对应的零值:
- 比如:数组,结构体。
与其他主流编程语言的差异
- Go语言不允许隐式类型转换
- 别名和原有类型也不能进行隐式类型转换
string是值类型:默认初始化值是空字符串,不是nil- 不支持指针运算
数组
数组定义
在Go语言中,数组从声明时就确定,使用时可以修改数组成员
- 但是数组大小不可变化。
var 数组变量名 [元素数量]T
// 定义一个长度为3元素类型为int的数组a
var a [3]int
比如:
var a [5]int, 数组的长度必须是常量
- 并且长度是数组类型的一部分。
一旦定义,长度不能变。
[5]int和[10]int是不同的类型。
var a [3]int
var b [4]int
a = b //不可以这样做,因为此时a和b是不同的类型
数组的初始化
初始化数组时可以使用初始化列表来设置数组元素的值。
func main() {
var testArray [3]int //数组会初始化为int类型的零值
var numArray = [3]int{1, 2} //使用指定的初始值完成初始化
var cityArray = [3]string{"北京", "上海", "深圳"} //使用指定的初始值完成初始化
fmt.Println(testArray) //[0 0 0]
fmt.Println(numArray) //[1 2 0]
fmt.Println(cityArray) //[北京 上海 深圳]
}
按照上面的方法每次都要确保提供的初始值和数组长度一致
- 一般情况下可以让编译器根据初始值的个数自行推断数组的长度。
func main() {
var testArray [3]int
var numArray = [...]int{1, 2}
var cityArray = [...]string{"北京", "上海", "深圳"}
fmt.Println(testArray) //[0 0 0]
fmt.Println(numArray) //[1 2]
fmt.Printf("type of numArray:%T\n", numArray) //type of numArray:[2]int
fmt.Println(cityArray) //[北京 上海 深圳]
fmt.Printf("type of cityArray:%T\n", cityArray) //type of cityArray:[3]string
}
还可以使用指定索引值的方式来初始化数组。
func main() {
a := [...]int{1: 1, 3: 5}
fmt.Println(a) // [0 1 0 5]
fmt.Printf("type of a:%T\n", a) //type of a:[4]int
}
数组的遍历
func main() {
var a = [...]string{"北京", "上海", "深圳"}
// 方法1:for循环遍历
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
// 方法2:for range遍历
for index, value := range a {
fmt.Println(index, value)
}
}
多维数组
二维数组的定义:
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
fmt.Println(a) //[[北京 上海] [广州 深圳] [成都 重庆]]
fmt.Println(a[2][1]) //支持索引取值:重庆
}
二维数组的遍历:
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
for _, v1 := range a {
for _, v2 := range v1 {
fmt.Printf("%s\t", v2)
}
fmt.Println()
}
}
数组是值类型
数组是值类型,赋值和传参会复制整个数组
- 因此改变副本的值,不会改变本身的值。
func modifyArray1(x [3]int){
x[0] = 100
}
func modifyArray2(x [3][2]int){
x[2][0] = 100
}
func main(){
a := [3]int{10,20,30}
modifyArray1(a) // 在modify中修改a的副本
fmt.Println(a) // [10,20,30] a保持不变
b := [3][2]int{
{1,1},
{1,1},
{1,1},
}
modifyArray2(b) // 在modify中修改的是b的副本
fmt.Println(b) // [[1 1] [1 1] [1 1]]
}
切片
数组的局限:数组的长度是固定的,并且长度属于类型的一部分。
切片可以理解为长度可以动态变化的数组
- 它是基于数组类型做的一层封装,非常灵活,支持自动扩容。
切片(
Slice)是一个拥有相同类型元素的可变长度的序列。切片是一个引用类型,它的内部结构包含
地址、长度和容量。
- 切片一般用于快速地操作一块数据集合。
切片中可以容纳元素的个数称为容量,容量大于等于长度
- 可以通过
len(slice)和cap(clice)分别获取切片的长度和容量。可以通过
make(type,len,cap)的方式创建出自动以初始长度和容量的切片
- 在追加元素的过程中,如果容量不够用时,就存在动态扩容问题
- 动态扩容采用的是倍增策略,即:
新容量=2*就容量。扩容后的切片会得到一片新的连续内存地址,所有元素的地址都会随之发生改变。
切片的定义
var name []T
func main() {
// 声明切片类型
var a []string //声明一个字符串切片
var b = []int{} //声明一个整型切片并初始化
var c = []bool{false, true} //声明一个布尔切片并初始化
var d = []bool{false, true} //声明一个布尔切片并初始化
fmt.Println(a) //[]
fmt.Println(b) //[]
fmt.Println(c) //[false true]
fmt.Println(a == nil) //true
fmt.Println(b == nil) //false
fmt.Println(c == nil) //false
// fmt.Println(c == d) //切片是引用类型,不支持直接比较,只能和nil比较
}
切片表达式
切片表达式从字符串、数组、指向数组或切片的指针构造字符串或切片,有两种变体:
- 一种指定start和end两个索引界限值得简单形式
- 另一种是除了start和end索引界限值外还制定容量的完整形式。
简单切片表达式:
切片的底层就是一个数组,可以基于数组通过切片表达式得到切片
- 切片中的
start和end表示一个索引范围(左包含,右不包含)
func main(){
a := [5]int{1,2,3,4,5} //长度为5,数据类型为int的数组
s := a[1:3] // s:= a[start:end]
fmt.Printf("s:%v len(s):%v cap(s):%v\n",s,len(s),cap(s))
//s:[2 3] len(s):2 cap(s):4
}
为了方便,通常可以省略切片表达式中的任何索引
- 省略了
start则默认是0,省略了end则默认到结尾。
a[2:] // a[2:len(a)]
a[:3] // a[0:3]
a[:] // a[0:len(a)]
完整切片表达式:
对于数组,指向数组的指针,或切片(注意不能是字符串)支持完整切片表达式。
a[start:end:max]
上面的代码会构造与简单切片表达式
a[start:end]相同类型,相同长度和元素的切片
- 另外,它会将得到的结果切片的容量设置为
max-start。在完整切片表达式中只有第一个索引值(start)可以省略,默认为0。
func main(){
a := [5]int{1,2,3,4,5}
t := a[1:3:5]
fmt.Printf("t:%v len(t):%v cap(t):%v\n",t,len(t),cap(t))
// t:[2,3] len(t):2 cap(t):4
}
完整切片表达式需要满足的条件是
0<=start<=end<=max<=cap(a)
- 其他条件和简单切片表达式相同。
使用make()函数构造切片
上面都是基于数组来创建的切片
- 如果需要动态的创建哪一个切片,就需要使用内置函数
make()
make([]T,size,cap)
// T:切片的元素类型
// size:切片中元素的数量
// cap:切片的容量
func main(){
a := make([]int,2,10)
fmt.Println(a) // [0,0]
fmt.Println(len(a)) // 2
fmt.Println(cap(a)) // 10
}
a的内部存储空间已经分配了10个,但是实际上只用了2个,容量并不会影响当前元素的个数
- 所以
len(a)返回2,cap(a)则返回该切片的容量。
切片的本质
切片的本质就是对底层数组的封装,包含三个信息:
- 底层数组的指针,切片的长度和切片的容量。
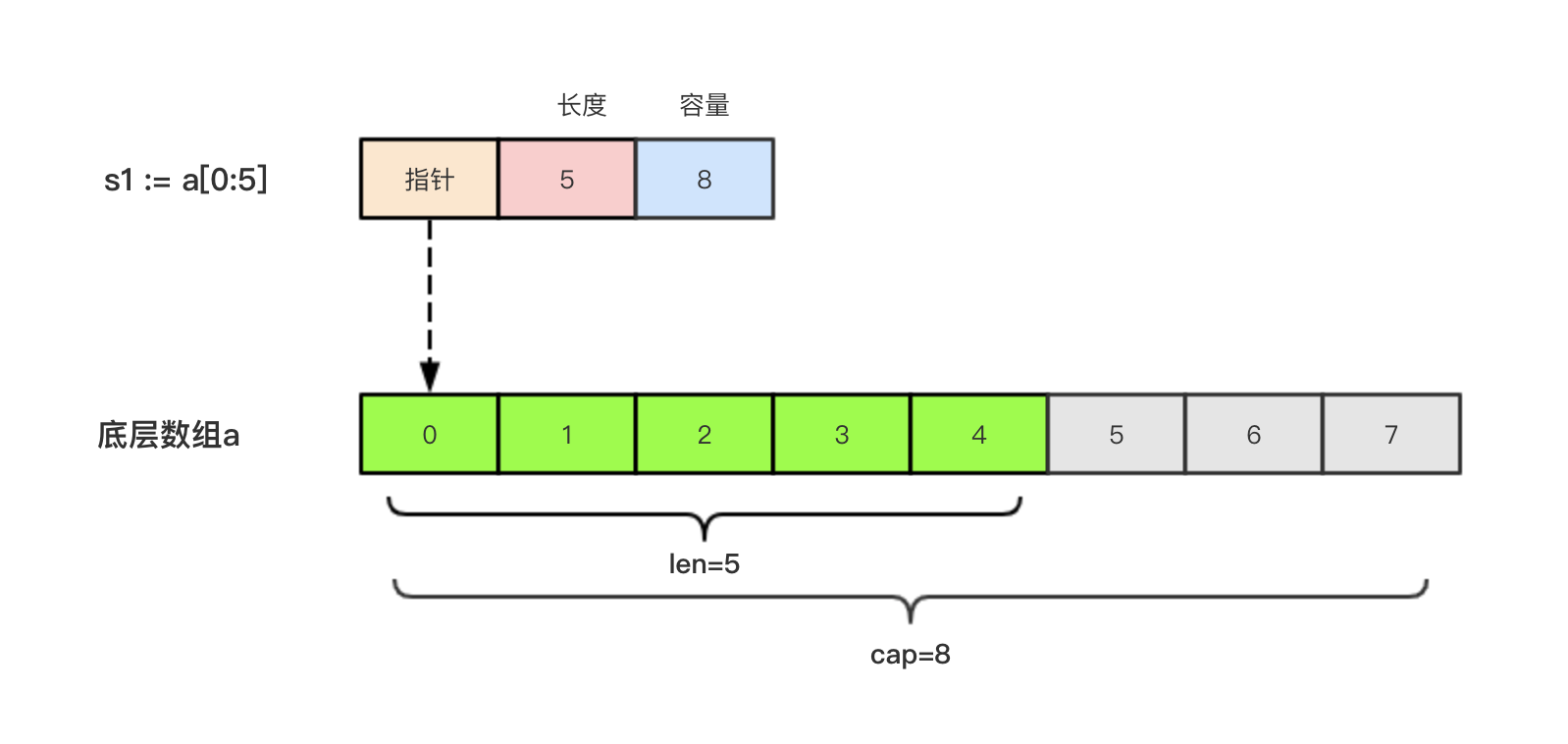
现在有一个数组
a:=[8]int{0,1,2,3,4,5,6,7},切片s1:=a[:5]相应的示意图如下:
切片
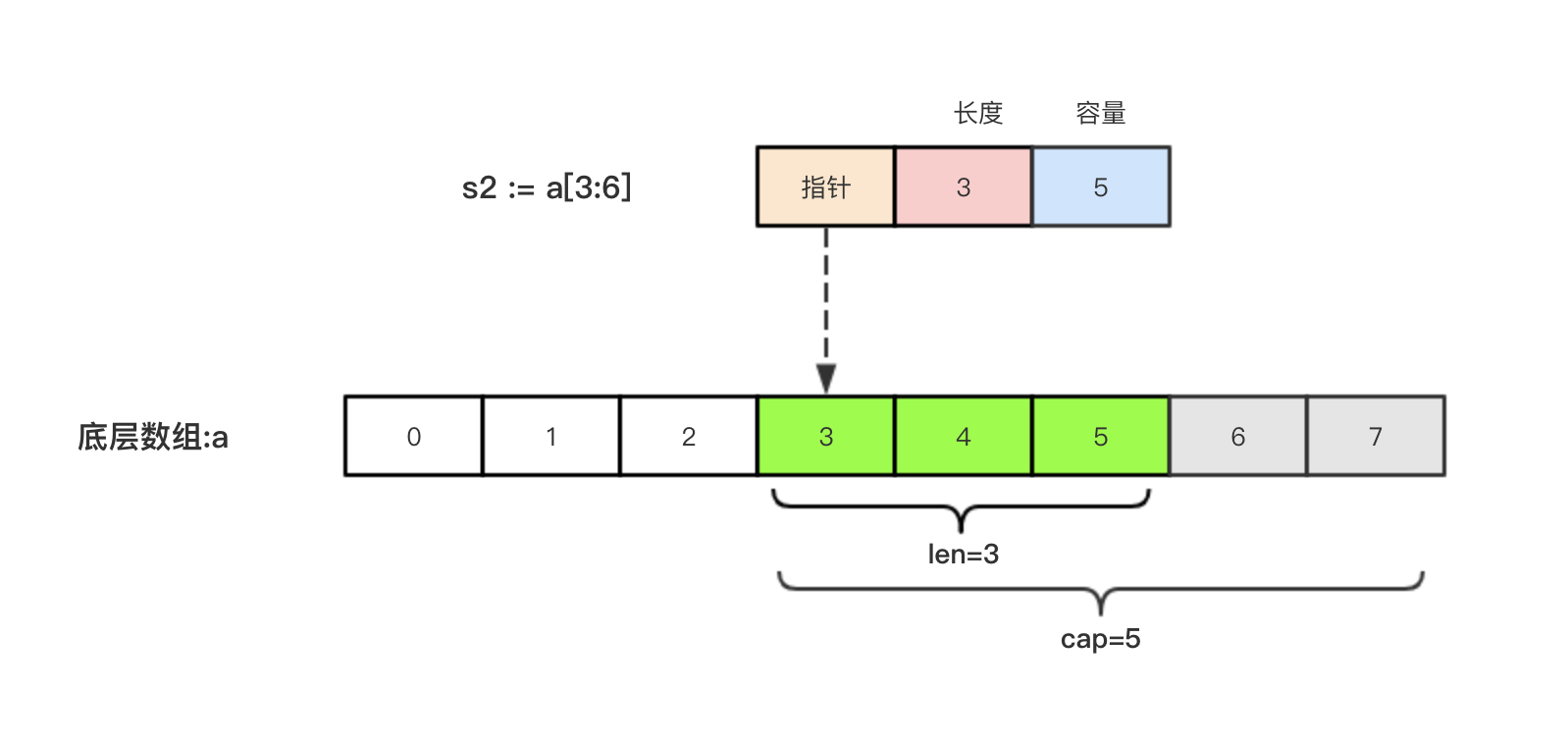
s2:=a[3:6],相应的示意图如下:
切片的赋值拷贝
拷贝前后两个变量共享底层数组
- 对一个切片的修改会影响另一个切片的内容。
func main(){
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) [100 0 0]
fmt.Println(s2) [100 0 0]
}
切片的遍历
切片的遍历方式和数组是一致的,支持索引遍历和
for range遍历。
func main(){
s := []int{2,3,1}
for i:=0;i<len(s);i++{
fmt.Println(i, s[i])
}
for index,value:=range s{
fmt.Println(index,value)
}
}
向切片中添加元素
Go语言的内建函数
append()可以为切片动态添加元素
- 可以一次添加一个元素,可以添加多个元素,也可以添加另外一个切片中的元素
func main(){
var s []int
s = append(s, 1) //s[1]
s = append(s,2,3,4) // [1 2 3 4]
s = append(s, s...) // [1 2 3 4 1 2 3 4]
}
通过var声明的零值切片可以在
append()函数直接使用无需初始化。没有必要初始化一个切片再传入
append()函数使用。
s := []int{} // 没有必要初始化
s = append(s, 1,2,3)
var s = make([]int) // 没有必要初始化
s = append(s,1,2,3)
从切片中删除元素
Go语言中并没有删除切片元素的专用方法,可以通过使用切片本身的特性来删除元素。
func main(){
// 从切片中删除元素
a := []int{30,32,34,36,38}
// 删除索引为2的元素
a = append(a[:2],a[3:]...)
}
从切片a中删除索引为
index的元素
- 操作方法是
a = append(a[:index], a[index+1:]...)
函数
函数的声明:
函数的声明:
- 使用 func 关键字,后面依次接
函数名,参数列表,返回值列表,用 {} 包裹的代码逻辑体
- 形式参数列表描述了函数的参数名以及参数类型
- 这些参数作为局部变量,其值由参数调用者提供
- 返回值列表描述了函数返回值的变量名以及类型
- 如果函数返回一个无名变量或者没有返回值,返回值列表的括号是可以省略的
func 函数名(形式参数列表)(返回值列表){
函数体
}
函数名:由字母、数字、下划线组成。
- 但函数名的第一个字母不能是数字:函数名也不能重复命名。
参数:参数由参数变量和参数变量的类型组成,多个参数之间使用
,分割返回值:返回值由返回值变量和其变量类型组成
- 也可以只写返回值的类型,多个返回值必须用
()包裹,并用,分割
举个例子,定义一个 sum 函数,接收两个 int 类型的参数
- 在运行中,将其值分别赋值给 a,b,并规定必须返回一个int类型的值
func sum(a int, b int) (int){
return a + b
}
func main() {
fmt.Println(sum(1,2))
}
无参数无返回值函数
函数可以有参数也可以没有参数,可以有返回值也可以没有返回值
func main() {
demo1()
}
func demo1(){
fmt.Println("执行demo1函数")
}
//上面代码等同于
//func main(){
// fmt.Println("执行demo1函数")
//}
可变参数函数
Go语言支持可变参数函数
可变参数指调用参数时,参数的个数可以是任意个
可变参数必须在参数列表最后的位置
- 在参数名和类型之间添加三个点表示可变参数函数
func 函数(参数,参数,名称 ... 类型 ){
//函数体
}
func main() {
demo("看书", "写代码", "看抖音视频")
}
func demo(hover ... string) {
for a, b := range hover {
fmt.Println(a, b)
}
}
多返回值
函数如果有多个返回值时必须用
()将所有返回值包裹起来。
匿名函数
匿名函数就是没有名称的函数
正常函数可以通过名称多次调用,而匿名函数由于没有函数名
- 所以大部分情况都是在当前位置声明并立即调用(函数变量除外)
匿名函数声明完需要调用,在函数结束大括号后面紧跟小括号
- 匿名函数都是声明在其他函数内部
func (){
}()//括号表示调用
//无参数匿名函数
func main(){
func(){
fmt.Println("这是匿名函数")
}()//括号表示调用
}
//有参数匿名函数
func main() {
func(s string) {
fmt.Println(s, "这是匿名函数")
}("传递参数") //调用时传递参数
}
//有参数有返回值匿名函数
func main() {
r := func(s string) int {
fmt.Println(s, "这是匿名函数")
return 110
}("传递参数") //调用时传递参数
fmt.Println(r)
}
函数作为参数或返回值
变量可以作为函数的参数或返回值类型,而函数既然可以当做变量看待
- 函数变量也可以当做函数的参数或返回值
函数作为参数时,类型写成对应的类型即可
func main() {
a(func(s string) {
fmt.Println(s)
})
}
func a(b func(s string)) {
fmt.Println("a执行")
b("传递给s的内容")
}
//函数作为返回值
func main() {
//此时result指向返回值函数.
result := a()
//调用函数,才能获取结果
fmt.Println(result())
}
func a() func() int {
return func() int {
return 110go
}
}
Defer语句
Go语言中的
defer语句会将其后面跟随的语句进行延迟处理。在
defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行
- 也就是说,先被
defer的语句最后被执行,最后被defer的语句,最先被执行。由于
defer语句延迟调用的特性,所以defer语句能非常方便的处理资源释放问题。
- 比如:资源清理、文件关闭、解锁及记录时间等。
func main() {
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end")
}
输出结果:
start
end
3
2
1
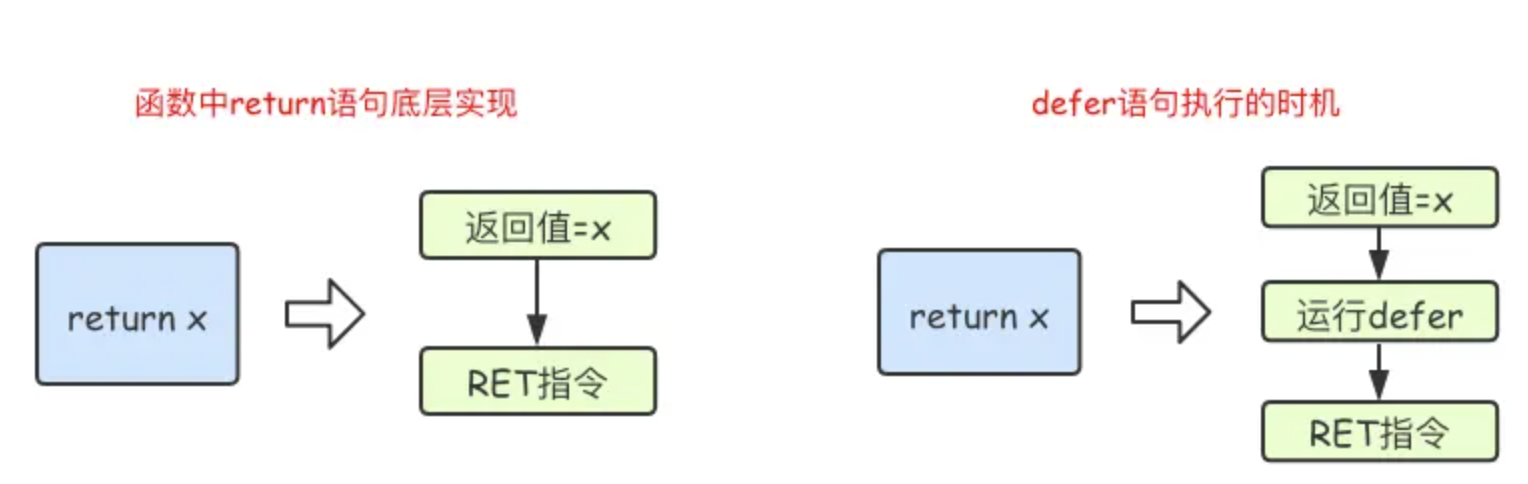
defer执行时机:
- 在Go语言的函数中
return语句在底层并不是原子操作
- 它分为给返回值赋值和RET指令两步。
- 而
defer语句执行的时机就在返回值赋值操作后,RET指令执行前。
全局变量
全局变量是定义在函数外部的变量,它在程序整个运行周期内都有效。
在函数中可以访问到全局变量。
package main
import "fmt"
// 定义全局变量
var num int64 = 10 // 不能使用 num := 10
func globalVar(){
fmt.Println(num) // 函数中可以访问到全局变量num
}
func main(){
globalVar() // num=10
}
结构体
Go语言中的基本数据类型可以表示一些事物的基本属性
- 但是当想表达一个事物的全部或者部分属性时
- 这时候再用单一的基本数据类型明显就无法满足需求。
Go语言提供了一种自定义数据类型,可以封装多个基本数据类型
- 这种数据类型叫结构体,
struct。Go语言中通过
struct来实现面向对象。
结构体的定义
使用
type和struct关键字来定义结构体。
type 类型名 struct{
字段名 字段类型
字段名 字段类型
...
}
// 类型名: 标识自定义结构体的名称,在同一个包内不能重复
// 字段名: 标识结构体字段名。结构体中的字段名必须唯一
// 字段类型: 标识结构体字段的具体类型
type person struct{ // 定义一个person的结构体
name string
age int8
city string
}
同类型的字段也可以写在一行。
type person struct{
name,city string
age int8
}
结构体实例化
只有当结构体实例化时,才会真正地分配内存,也就是必须实例化后才能使用结构体的字段。
结构体本身也是一种类型
- 可以像声明内置类型一样使用
var关键字来声明结构体类型。通过
.来访问结构体字段(成员变量),例如p.name和p.age等。
var 结构体实例 结构体类型
type person struct {
name string
city string
age int8
}
func main() {
var p1 person
p1.name = "娜扎"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) //p1={娜扎 北京 18}
fmt.Printf("p1=%#v\n", p1) //p1=main.person{name:"娜扎", city:"北京", age:18}
}
匿名结构体
在定义一些临时数据结构等常见下可以使用匿名结构体。
package main
import (
"fmt"
)
func main() {
var user struct{Name string; Age int}
user.Name = "小王子"
user.Age = 18
fmt.Printf("%#v\n", user)
}
创建指针类型结构体
通过使用
new关键字对结构体进行实例化,得到的是结构体地址。
var p = new(person)
fmt.Printf("%T\n",p) // *main.person
fmt.Printf("p=%#v\n",p) // p=&main.person{name:"",age:0,city:""}
从打印结果来看,此时
p是一个结构体指针。在Go语言中支持对结构体指针直接使用
.来访问结构体成员。
var p = new(person)
p.name = "Negan"
p.age = 68
p.city = "亚历山大"
fmt.Printf("p=%#v\n",p) // p=&main.person{name:"Negan",age:68,city:"亚历山大"}
取结构体的地址实例化
使用
&对结构体进行取地址操作相当于对该结构体类型进行了一次new实例化操作。
p := &person{}
fmt.Printf("%T\n",p) // *main.person
fmt.Printf("p=%v\n",p) // p=&main.person{name:"",age:0,city:""}
p.name = "Negan"
p.age = 68
p.city = "救世堂"
fmt.Printf("p=%#v\n",p) // p=&main.person{name:"Negan",age:68,city:"救世堂"}
p.name="Negan"其实在底层是(*p3).name="Negan"
- 这是Go语言实现的语法糖。
结构体初始化
没有初始化的结构体,其成员变量都是对应其类型的零值。
type person struct{
name string
age int8
city string
}
func main(){
var p person
fmt.Printf("p=%#v\n",p) // p=main.person{name:“”,age:0,city:""}
}
使用键值对初始化
使用键值对对结构体进行初始化,键对应结构体的字段,值对应该字段的初始值。
p := person{
name:"Negan",
age:68,
city:"亚历山大"
}
fmt.Printf("p=%#v\n",p) // p=main.person{name:"Negan",age:68,city:"亚历山大"}
也可以使用结构体指针进行键值对初始化。
p := &person{
name:"Negan",
age:68,
city:"亚历山大"
}
fmt.Printf("p=%#v\n",p) //p=&main.person{name:"Negan",age:68,city:"亚历山大"}
当某些字段没有初始值的时候,该字段可以不写
- 此时没有指定初始值的字段的值就是该字段类型的零值。
p := &person{
city:"救世堂"
}
fmt.Printf("p=%#v\n",p) // p=&main.person{name:"",age:0,city:"救世堂"}
使用值的列表初始化
初始化结构体的时候可以简写,也就是初始化的时候不写键,直接写值。
使用这种格式初始化时,需要注意:
- 必须初始化结构体的所有字段
- 初始值的填充循序必须与字段在结构体中的声明顺序一致
- 该方式不能和键值初始化方式混用
p := &person{
"Negan",
68,
"救世堂"
}
fmt.Printf("p=%#v\n",p) // p=&main.person{name:"Negan",age:68,city:"救世堂"}
结构体的继承
Go语言中使用结构体可以实现其他编程语言中的面向对象继承。
// Animal 动物
type Animal struct{
name string
}
func (a *Animal) move(){
fmt.Printf("%s会动", a.name)
}
type Dog struct {
Feet int8
*Animal // 通过嵌套匿名结构体实现继承
}
func (d *Dog) wang(){
fmt.Printf("%s会汪汪汪~\n",d.name)
}
func main() {
d := &Dog{
Feet: 4,
Animal:&Animal{
name: "旺财",
},
}
d.wang() // 旺财会汪汪汪~
d.move() // 旺财会动
}
结构体字段的可见性
结构体中字段大写开头表示公开访问
- 小写表示私有(仅在定义当前结构体的包中可访问)。
嵌套结构体
一个结构体中可以嵌套包含另一个结构体或者结构体指针。
// Address 地址结构体
type Address struct{
Province string
City string
}
// User 用户结构体
type User struct{
Name string
Gender string
Address Address
}
func main() {
user := User{
Name: "Negan",
Gender:"男",
Address: Address{
Province: "陕西",
City: "西安",
},
}
fmt.Printf("user=%#v\n", user)
// user=main.User{Name:"Negan", Gender:"男", Address:main.Address{Province:"陕西", City:"西安"}}
}
嵌套匿名结构体
当访问结构体成员时会现在结构体中查找该字段,找不到再去匿名结构体中查找。
// Address 地址结构体
type Address struct {
Province string
City string
}
// User 用户结构体
type User struct{
Name string
Gender string
Address // 匿名结构体
}
func main() {
var user User
user.Name = "Negan"
user.Gender = "男"
user.Address.Province = "陕西" // 通过匿名结构体.字段名访问
user.City = "西安" // 直接访问匿名结构体的字段名
fmt.Printf("user=%#v\n", user)
// user=main.User{Name:"Negan", Gender:"男", Address:main.Address{Province:"陕西", City:"西安"}}
}
嵌套结构体的字段名冲突
嵌套结构体内部可能存在相同的字段名
- 这个时候为了避免歧义需要制定具体的内嵌结构体的字段。
// Address 地址结构体
type Address struct{
Province string
City string
CreateTime string
}
// Email 邮箱结构体
type Email struct{
Account string
CreateTime string
}
// User 用户结构体
type User struct {
Name string
Gender string
Address
Email
}
func main() {
var user User
user.Name = "Negan"
user.Gender = "男"
user.Address.CreateTime = "2020"
user.Email.CreateTime = "2020"
fmt.Printf("%#v\n", user)
}
指针
指针是一个地址,指针类型是依托于某一个类型而存在的。
Go里面的基本数据类型int、float64、string等
- 它们所对应的指针类型为
*int、*float64、*string等。指针的定义:
- 语法格式:
var 指针变量名 *数据类型 = &变量。&为取地址符号,通过&符号获取某个变量的地址,然后赋值给指针变量。
import (
"fmt"
)
func main() {
var num int = 666
var numPtr *int = &num
fmt.Println(numPtr) // num 变量的地址值 0xc00001c098
fmt.Println(&numPtr) // 指针变量本身的地址值 0xc00000a028
}
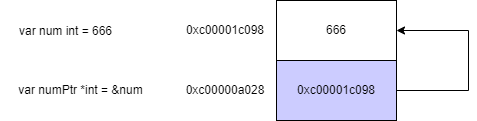
npmPtr指针变量指向变量num,0xc00001c098为num变量的地址
0xc00000a028为指针变量本身的地址值。
使用
new(T)函数创建指针变量:
new(T)函数为每个类型分配一片内存
- 内存单元保存的是对应类型的零值,函数返回一个指针类型。
import (
"fmt"
)
func main() {
numPtr := new(int)
fmt.Println(numPtr) // 0xc000122058
fmt.Println(*numPtr) // 0
}
错误的类型地址赋值:
- 当指针所依托的类型与变量的类型不一致时,Go 编译器会报错,类型不匹配。
func main() {
var num float64 = 666
var numPtr *int = &num // cannot use &num (value of type *float64) as type *int in variable declaration
}
获取和修改指针所指向变量的值
- 通过指针获取所指向变量的值
- 对指针使用
*操作符可以获取所指向变量的值。
func main() {
var num int = 666
var numPtr *int = &num
// 获取 num 的值
fmt.Println(*numPtr) // 666
}
通过指针修改所指向变量的值
- 同时也可以对指针使用
*操作符修改所指向变量的值。
import (
"fmt"
)
func main() {
var num int = 666
var numPtr *int = &num
// 修改 num 的值
*numPtr = 555
fmt.Println(num) // 555
}
值类型和引用类型
值类型:
- 基本数据类型int系列,float系列,bool,string,数组和结构体 struct
引用类型:
- 指针,slice切片,map,管道chan,interface等都是引用数据类型
值类型:
- 变量直接存储值,内存通常在栈中分配

引用类型:
变量存储的是一个地址,这个地址对于的空间才是真正的存储数据(值)
- 内存通常在堆上分配,当没有任何变量引用这个地址时
- 改地址对应的数据空间就成为了一个垃圾,由GC来回收

内存的栈区和堆区:

并发
Go语言中的并发通过
goroutine实现。
goroutine类似于线程,属于用户态线程
- 可以根据需要创建成千上万个
goroutine并发工作。
goroutine是由Go语言的运行时(runtime)调度完成,而线程是由操作系统调度完成。Go语言还提供
channel在多个goroutine间进行通信。
Goroutine
Go程序会将
goroutine中的任务合理地分配给每个CPU。当需要让某个任务并发执行的时候
- 只需要把这个任务包装成一个函数,开启一个
goroutine去执行这个函数就行。一个
goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
启动单个goroutine
使用
goroutine只需要在调用函数的时候在前面加上go关键字
- 就可以为一个函数创建一个
goroutine。
func hello(){
fmt.Println("hello Goroutine")
}
func main(){
go hello()
fmt.Println("this is a main goroutine")
}
在程序启动时,Go程序就会为
main()函数创建一个默认的goroutine。当
main()函数返回的时候该goroutine就结束了
- 所有在
main()函数中启动的goroutine会一同结束。
出让资源
通过
runtime.Gosched()出让资源,让其他goroutine优先执行。
func main() {
go func(){
for i := 0; i < 5; i++{
fmt.Println("go")
}
}()
for i:=0;i<2;i++{
// 让出时间片,让别的goroutine先执行
runtime.Gosched()
fmt.Println("hello")
}
}
自杀
通过
runtime.Goexit()实现自杀,自杀前会执行提前定义的defer语句
- 同时调用它的
goroutine也会跟着自杀。
func test(){
// 遗嘱:临终前说的话
defer fmt.Println("这是test的遗嘱")
// 自杀,触发提前执行遗嘱,暴毙,后面的日志不好过了,调用它的goroutine也暴毙
runtime.Goexit()
// 自杀了,后面的日子不好过了
fmt.Println("生活承诺的很多美好事情。。。(不会打印)")
}
func wildMan(){
for i:=0;i<6;i++{
fmt.Println("我是野人,我不喜欢约束,我讨厌制约我的主goroutine")
time.Sleep(time.Second)
}
}
func main() {
// 一个会暴毙的goroutine
go func(){
fmt.Println("这里包含一个会暴毙的goroutine")
test() // runtime.Goexit()
fmt.Println("这句应该不能出现")
}()
// 一个讨厌主goroutine的野人goroutine,主goroutine结束后,会把它一起带走
go wildMan()
for i:=0;i<=3;i++{
time.Sleep(time.Second)
}
}
主
goroutine结束后,会带走未结束的子goroutine。同时如果主
goroutine暴毙,会令所有的子goroutine失去牵制,等所有的子goroutine都结束后程序会崩溃:
fatal error: no goroutines (main called runtime.Goexit) - deadlock!。
启动多个Goroutine
使用
sync.WaitGroup来实现goroutine的同步。
var wg sync.WaitGroup
func test(){
defer wg.Done()
// 遗嘱:临终前说的话
defer fmt.Println("这是test的遗嘱")
// 自杀,触发提前执行遗嘱,暴毙,后面的日志不好过了,调用它的goroutine也暴毙
runtime.Goexit()
// 自杀了,后面的日子不好过了
fmt.Println("生活承诺的很多美好事情。。。(不会打印)")
}
func wildMan(){
defer wg.Done()
for i:=0;i<6;i++{
fmt.Println("我是野人,我不喜欢约束,我讨厌制约我的主goroutine")
time.Sleep(time.Second)
}
}
func main() {
wg.Add(2)
// 一个会暴毙的goroutine
go func(){
fmt.Println("这里包含一个会暴毙的goroutine")
test() // runtime.Goexit()
fmt.Println("这句应该不能出现")
}()
// 一个讨厌主goroutine的野人goroutine,主goroutine结束后,会把它一起带走
go wildMan()
for i:=0;i<=3;i++{
time.Sleep(time.Second)
}
//runtime.Goexit()
fmt.Println("主goroutine正常退出,会带走所有的子goroutine")
wg.Wait() // 等待所有登记的goroutine都结束
}
Channel
channe1可以让一个goroutine发送特定值到另一个goroutine的通信机制。Go语言中的通道(
channel)是一种特殊类型,通道像一个传送带或者队列
- 总是遵循先进先出的规则,保证数据的收发顺序
每一个通道都是一个具体类型的导管,也即是声明
channel时候需要为其制定元素类型。
channel类型
channel是一种类型,一种应用类型,声明通道类型的格式如下:
var 变量 chan 元素类型
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道
创建channel
通道是引用类型,通道类型的控制是
nil
var ch chan int
fmt.Println(ch) // <nil>
声明的通道需要使用
make函数初始化后才能使用创建
channel的格式如下:
make(chan 元素类型,[缓冲大小])
channel操作
通道有读、写和关闭三种操作。
读和写都是用
<-符号。
// 初始化一个channel
ch := make(chan int)
// write to channel
ch <- 123
// read from channel
x := <- ch
<- ch // 忽略结果
// close channel
chose(ch)
channel类型
channel
分不带缓冲区的channel和带缓冲区的channel。
无缓冲区
无缓冲
channel从无缓冲的channel中读取消息会阻塞
- 直到有
goroutine向该channel中发送消息。同理,向无缓冲区的
channel中发送消息也会阻塞
- 直到有
goroutine从channel中读取消息。使用无缓冲通道进行通道将导致发送和接收的
goroutine同步化
- 因此无缓冲通道也被称为
同步通道。
func recv(c chan int){
ret := <-c
fmt.Println("接收成功",ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 启动goroutine从通道接收值
ch <- 10 // 发送值
fmt.Println("发送成功")
}
有缓存的通道
有缓存的
channel的声明方式为指定make函数的第二个参数
- 该参数为
channel缓存的容量。有缓存的
channel类似于一个阻塞队列(采用环形数组实现)。当缓存未满时,向
channel中发送消息不会阻塞
- 当缓存满时,发送操作将会阻塞,直到有其他
goroutine从中读取消息。相应的,当
channel中消息不为空是,读取消息不会出现阻塞
- 当
channel为空时,读取操作会发生阻塞,直到有goroutine向channel中写入消息。可以通过使用内置的
len()函数获取通道内元素的数量
- 使用
cap()函数获取通道的容量。
func main() {
ch := make(chan int, 1) // 创建一个容量为1的有缓存区通道
ch <- 10
fmt.Println("len(ch) = ",len(ch)) // len(ch) = 1
fmt.Println("cap(ch) = ",cap(ch)) // cap(ch) = 1
fmt.Println("发送成功")
}
互斥锁
有时候在Go代码中可能存在多个
goroutine同时操作一个资源(临界区)
- 这种情况会发生
竟态问题(数据竟态)。互斥锁是一种常用的控制共享资源访问的方法
- 它能够保证同时只有一个
goroutine可以访问共享资源。Go语言中使用
sync包的Mutex类型来实现互斥锁。
func main() {
// 必须保证并发安全的数据
type Account struct {
money float32
}
var wg sync.WaitGroup
account := Account{money: 1000}
fmt.Println(account)
//资源互斥锁(谁抢到锁,谁先访问资源,其他人阻塞等待)
//全局就这么一把锁,谁先抢到谁操作,其他人被阻塞直到被释放
var mt sync.Mutex
wg.Add(2)
// 银行卡取钱
go func() {
defer wg.Done()
// 拿到互斥锁
mt.Lock()
// 加锁的访问
fmt.Println("取钱前:", account.money)
account.money -= 500
time.Sleep(time.Nanosecond)
fmt.Println("取钱后:", account.money)
// 释放互斥锁
mt.Unlock()
}()
go func(){
defer wg.Done()
// 拿到互斥锁(如果别人先抢到,则阻塞等待)
mt.Lock()
fmt.Println("存钱前:", account.money)
account.money += 500
time.Sleep(time.Nanosecond)
fmt.Println("存钱后:", account.money)
// 释放互斥锁
mt.Unlock()
}()
wg.Wait()
}
通过信号量控制并发数
控制并发数属于常用的调度,规定并发的任务都必须现在某个监视管道中进行注册
- 而这个监视管道的缓存能力是固定的
- 比如说5,那么注册在该管道中的并发能力也是5。
var sema chan int
// 该函数只允许5次并发执行
func f1(i int) int {
sema <- 1
<- time.After(2*time.Second)
<- sema
return i*i
}
// 信号量:通过控制管道的"带宽"(缓存能力)控制并发数
func main() {
// 定义信号量为5"带宽"的管道
sema = make(chan int, 5)
var wg sync.WaitGroup
for i:=0;i<100;i++{
wg.Add(1)
go func(index int) {
ret := f1(index)
fmt.Println(index,ret)
wg.Done()
}(i)
}
wg.Wait()
}
定时器
Go提供了两种方式的计时器:
定时执行任务的计时器和周期性执行任务的计时器
固定时间定时器
func main() {
// 创建两秒的定时器
timer := time.NewTimer(2 * time.Second)
fmt.Println("当前时间:", time.Now())
//当前时间: 2020-05-13 09:12:41.0018223 +0800 CST m=+0.006835901
//两秒后,从单向时间管道中读取内容(当前时间)
// timer.C是一个单向的时间管道
t := <- timer.C
fmt.Println("t = ",t)
// t = 2020-05-13 09:12:43.0313903 +0800 CST m=+2.006835901
}
上面的示例演示了如何使用定时器延时两秒执行一项任务。
上面的示例也可以写成下面的形式。
func main() {
fmt.Println("开始计时")
// 创建2秒的定时器,得到其单向输出时间管道,阻塞两秒后读出数据
<- time.After(2 * time.Second)
fmt.Println("时间到")
}
提前终止计时器
计时器被中途stop掉了,被延时的
goroutine将永远得不到执行,
func main() {
// 创建3秒的定时器
timer := time.NewTimer(3*time.Second)
// 3秒后从定时器时间管道中读取时间
go func(){
<- timer.C
fmt.Println("子goroutine可以打印了,因为定时器的时间到了")
}()
// 停止定时器,停止状态下,计时器失效,被timer.C锁阻塞的子goroutine永远读不出数据
timer.Stop()
// 主goroutien为子goroutine留出足够的时间
time.Sleep(6*time.Second)
fmt.Println("Game Over")
}
中途重置定时器
下面的例子中,timer在配置为延时10秒执行后
- 又被重置为1秒,所以其时间延时为一秒。
需要注意的是:
如果在reset的一刹那,定时器已经到时或者已被stop掉,则reset是无效的。
func main() {
// 创建10秒的定时器
timer := time.NewTimer(10 * time.Second)
// 重置为1秒
// 如果已经到时,或者已经stop,则重置失败
ok := timer.Reset(1 * time.Second)
fmt.Println("OK = ", ok, time.Now())
// OK = true 2020-05-13 09:43:12.0831215 +0800 CST m=+0.073242201
// 1秒后即可读出时间
t := <- timer.C
fmt.Println("时间到", t)
// 时间到 2020-05-13 09:43:13.121344 +0800 CST m=+1.074218801
}