 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
配合以下文章一起看:
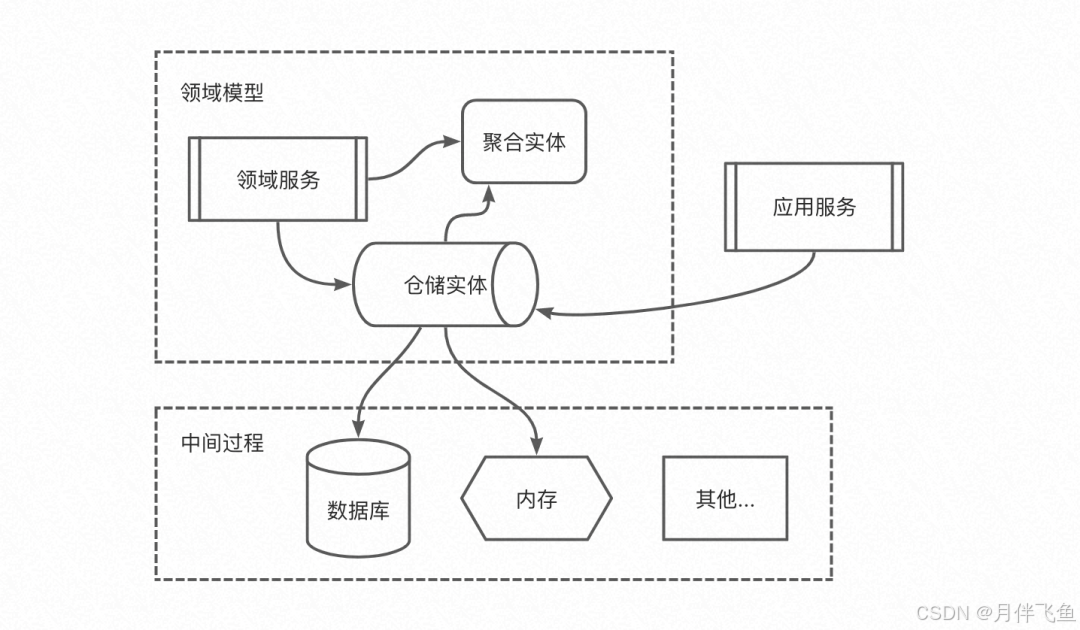
仓储就类似于仓库管理员,它是聚合的管理。
仓储介于领域模型和数据模型之间:
- 主要用于聚合的持久化和检索。
它隔离了领域模型和数据模型,以便我们关注于领域模型而不需要考虑如何进行持久化。
为什么要用仓储
解耦领域层和基础层
DDD严格的分层架构告诉我们:
每一层只能与其下方的一层发生耦合。
因此用户接口层只与应用层发生交互,应用层往下只与领域层发生交互,领域层往下只与基础层发生交互。
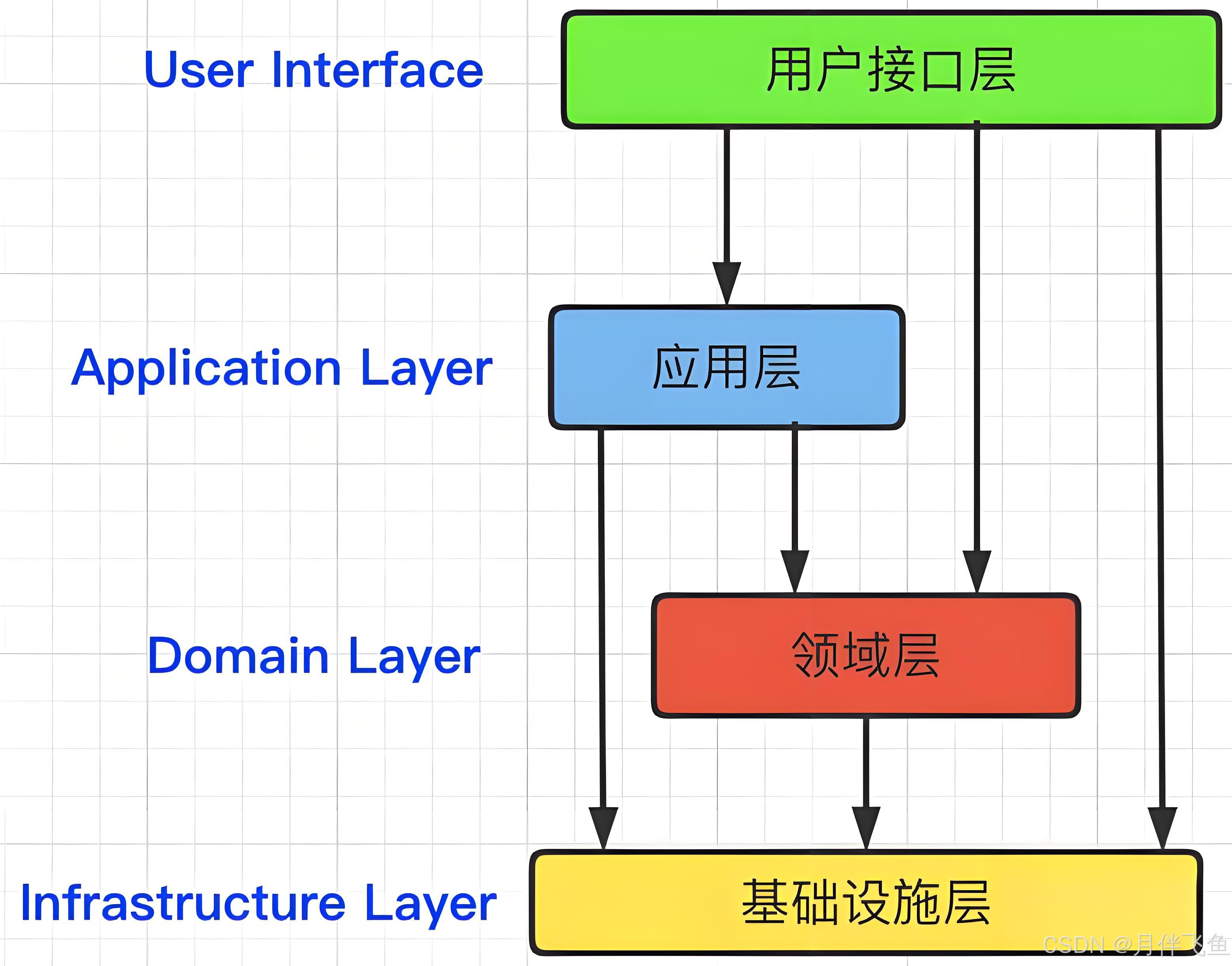
在传统的代码分层结构Controller—Service—Dao结构中:
经常能看到在
Service业务实现层的代码中嵌入SQL,或者在其中频繁出现修改数据对象并调用DAO的情况。
- 这样的话,基础层的数据处理逻辑就渗透到了业务逻辑代码中。
在DDD的分层结构中:
如果出现上述情况,则基础层的数据处理逻辑就渗透到了领域层。
- 领域层中的领域模型就难以聚焦在业务逻辑上,对外层的基础层产生了依赖。
而一旦涉及到数据逻辑的修改,就要到领域层中去修改代码。
本文要讲的仓储模式就是用来解耦领域层和基础层的,降低他们之间的耦合和相互影响。
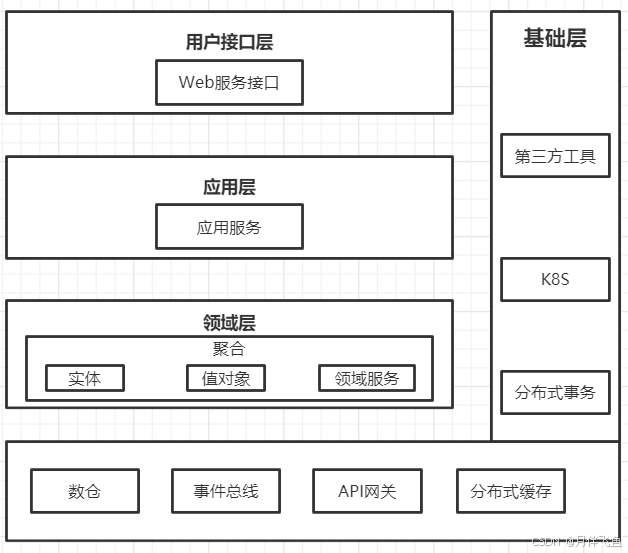
仓储模式
仓储模式包含仓储接口和仓储实现:
仓储接口
- 面向领域层提供基础层数据处理相关的接口。
仓储实现
- 完成仓储接口对应的数据持久化相关的逻辑处理。
一个聚合配备一个仓储,由仓储完成聚合数据的持久化。
- 领域层逻辑面向仓储接口编程,聚合内的数据持久化过程为
DO(领域对象)转PO(持久化对象)。
当需要更换数据库类型,或者更改数据处理逻辑时:
我们就可以保持业务逻辑接口不动,只修改仓储实现,保证了领域层业务逻辑和基础层逻辑隔离。
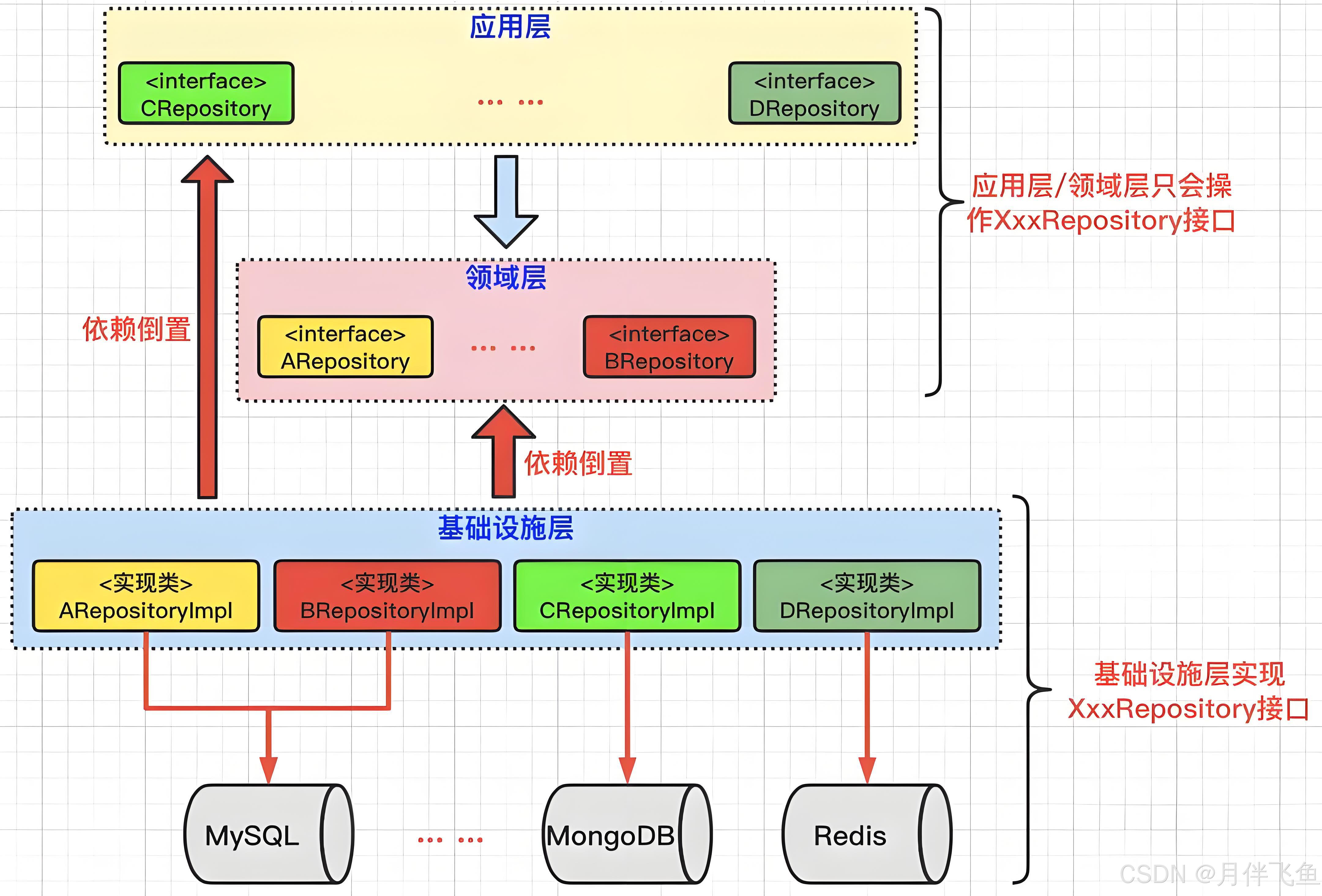
仓储的架构
仓储要依赖数据库、内存等具体的实现工具去做真正的持久化。
如下图所示(图中连线代表依赖关系):
我们可以把仓储的行为抽象为基本的接口,然后利用控制反转。
- 把实现该节点的仓储注入领域模型的运行态中。
实现了倒置依赖的依赖图如下:
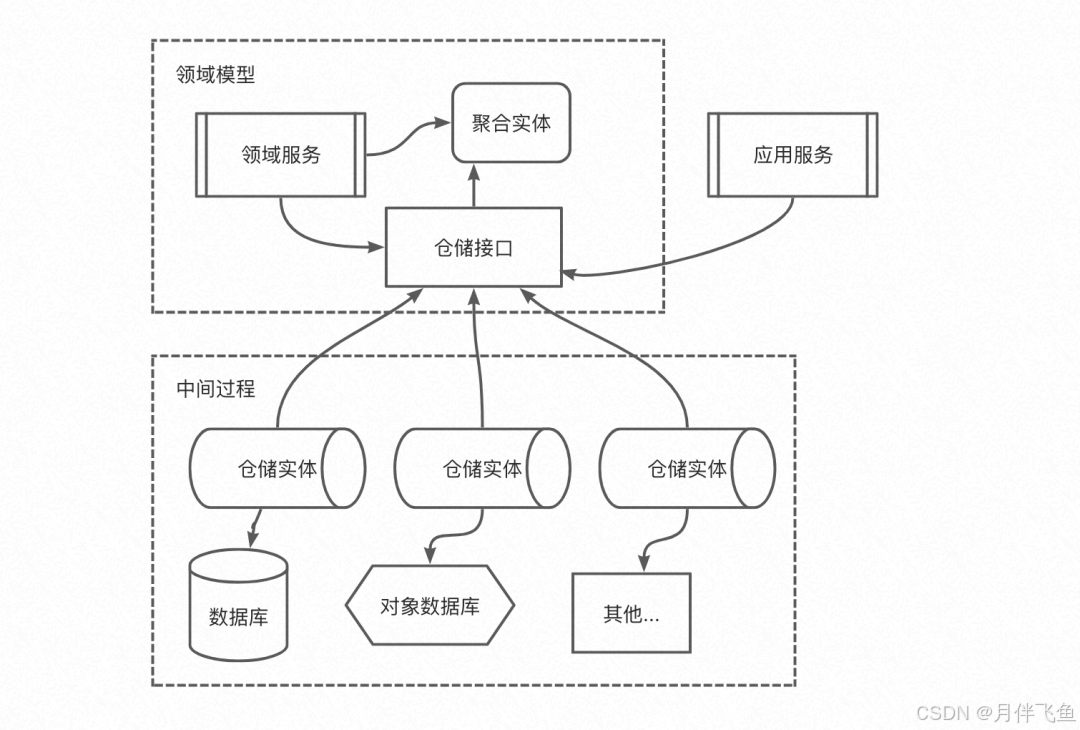
实现举例
如下示例为一个订单聚合中对订单实体的仓储模式实现。
订单DO定义:
/**
* 订单聚合
*/
public class OrderDO {
//订单ID
private long id;
//订单时间
private long orderTime;
}
订单PO定义:
/**
* 订单聚合的持久化PO
*/
public class OrderPO {
//订单ID
private long id;
//订单时间
private long orderTime;
}
仓储接口定义:
/**
* 订单聚合仓储接口
*/
public interface OrderRepository {
/**
* 添加订单
*/
void addOrder(OrderPO order);
/**
* 更新订单
*/
void updateOrder(OrderPO order);
/**
* 根据ID查找订单PO对象
*/
OrderPO findById(long id);
}
仓储接口实现:
/**
* 订单仓储实现
*/
public class OrderRepositoryImpl implements OrderRepository {
@Resource
private OrderDao orderDao;
@Override
public void addOrder(OrderPO order) {
orderDao.addOrder(order);
}
@Override
public void updateOrder(OrderPO order) {
orderDao.updateOrder(personPO);
}
@Override
public OrderPO findById(long id) {
return orderDao.findById(id);
}
}
订单领域服务实现:
后面基础层发生了变化,则领域层无需动任何代码。
- 只要仓储接口不变,领域层的逻辑就可以一直保持不变,维护了领域层的稳定性。
/**
* 定领域服务聚合类
*/
public class OrderDomainService {
@Resource
private OrderRepository orderRepository;
public void addOrder(OrderPO order) {
orderRepository.addOrder(order);
}
}
Respository(仓储)与DAO(数据访问层)的区别
之前一篇文章介绍过聚合:领域设计之理解聚合与聚合根!
在理解了聚合之后,我们可以知道:
DAO是技术手段,Respository是抽象方式。
DAO只是针对对象的操作,而Respository是针对 聚合 的操作。
DAO的操作方式如下:
订单和和订单明细都有一个对应的
DAO。订单和订单明细的关系并没有在对象之间得到体现。
@Service
@Transactional
public class OrderService {
public void createOrder(Order order, List<OrderDetail> orderDetailList) throws Exception {
Long orderId = orderDao.save(order);
for(OrderDetail detail : orderDetailList) {
detail.setOrderId(orderId);
orderDetailDao.save(detail);
}
}
}
Respository的操作方式如下:
// 订单和订单明细构成聚合
public class Order {
List<OrderDetail> orderDetail;
...
}
@Service
@Transactional
public class OrderService {
public void createOrder(Order order) throws Exception {
orderRespository.save(order);
}
}
StackOverFlow中有一个回答,讲的很好:

工厂模式
DO对象创建时,需要确保聚合根和它依赖的对象同时被创建。
如果这项工作交给聚合根来实现,则聚合根的构造函数将变得异常庞大。
所以把通用的初始化DO的逻辑,放到工厂中去实现。
通过工厂模式封装聚合内复杂对象的创建过程,完成聚合根,实体和值对象的创建。
DO对象创建时,通过仓储从数据库中获取PO对象,通过工厂完成PO到DO的转换。工厂中还可以包含DO到
PO对象的转换过程,方便完成数据的持久化。
/**
* Order聚合的工厂
* DO和PO的转换
*/
public class OrderFactory {
/**
* OrderPO到领域对象的数据初始化
*/
protected Order createPerson(OrderPO orderPO){
Order order = new Order();
order.setId(orderPO.getId());
order.setOrderTime(orderPO.getOrderTime());
return order;
}
/**
* 领域对象到持久化对象PO的转换
*/
protected OrderPO createPersonPO(Order order){
OrderPO orderPO = new OrderPO();
orderPO.setId(order.getId());
orderPO.setOrderTime(order.getOrderTime());
return orderPO;
}
}
参考资料:
《基于DDD和微服务的中台架构与实现》
《架构真经》
《领域驱动设计:软件核心复杂性应对之道》
《实现领域驱动设计》