 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上。
ES用 Java 编写,内部使用 Lucene 做索引与搜索:
- 使全文检索变得简单,隐藏 Lucene 的复杂性,提供一套简单的 RESTful API。
学习资源
官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
中文权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
ES的限制和劣势
不适合做数据存储,不支持事务,近实时而无法保证实时性,Index建立后Mapping无法修改。
翻页查询性能较差。
作为OLAP数据库,ES可以处理复杂聚合、大规模Rollup、大规模的Key-Value查询:
- 聚合查询性能比Doris、ClickHouse、Presto等差不少
- Rollup相对于Druid来说实时性、并发能力和查询速度处于劣势
- KV并发查询能力比HBase差不少
使用规范
分片(Shard):
非日志型(搜索型、线上业务型)的 shard 容量在 20~40GB(建议在 20G)
日志型的
shard容量在 35~100GB(建议 35G)单个
shard的文档个数不能超过 20 亿左右(Integer.MAX_VALUE - 128)一个节点管理的
shard数不要超过 200 个一个索引的
shard数一旦确定不能改变
索引(Index):
大索引需要拆分
反例:例如一个 10 多 T 的索引,按 date 查询、name 查询
正例:
index*name拆成多个index_name*${date}正例:
index*name按 hash 拆分index_name*{1,2,3,...100..}
Refresh频率:
ES 的定位是准实时搜索引擎,该值默认是 1s,表示写入后 1 秒后可被搜索到,所以这里的值取决于业务对实时性的要求。
注意这里并不是越小越好,刷新频率高也意味着对 ES 的开销也大,通常业务类型在 1-5s,日志型在 30s-120s。
如果集中导入数据可将其设置为-1,ES 会自动完成数据刷新(注意完成后更改回来,否则后续会出现搜索不到数据)。
字段设计:
text和keyword的用途必须分清:分词和关键词(确定字段是否需要分词)确定字段是否需要独立存储
字段类型不支持修改,必须谨慎
对不需要进行聚合/排序的字段禁用
doc_values不要在
text做模糊搜索
text类型:
- 适用于分词用于搜索,适用于 email 、内容、描述等需要分词的全文检索,不适用聚合。
- text 类型的字段不要使用聚合查询
- text
类型fileddata会加大对内存的占用,如果有需求使用,建议使用keyword
keyword类型:
- 无需分词,整段完整精确匹配,适用于:email 、地址、状态码、分类 tags。
避免大宽表:
- ES 默认最大 1000,但建议不要超过 100
查询相关:
聚合查询避免使用过多嵌套:
- 聚合查询的中间结果和最终结果都会在内存中进行,嵌套过多,会导致内存耗尽。
基本概念
index索引
类比称mysql中的database数据库,存储数据的地方。
type类型
用于定义数据结构,类似mysql的一张表,属于index中的逻辑分类。
mapping
定义存储字段类型。
document
类比mysql中一行数据,不同之处在于es中每个文档可以有不同的字段。
field字段
类比mysql中的字段,属于es的最小单位。
正排索引
文档ID到文档内容、单词的关联关系。
倒排索引
单词到文档ID的关联关系。
倒排索引主要包含两个部分。
单词词典:
记录所有文档的单词。
记录单词到倒排列表的关联信息。
倒排列表:
- 记录了单词对应的文档集合,由倒排索引项组成。
倒排索引项包含如下信息:
- 文档ID,用于获取原始信息。
- 单词频率,记录该单词在该文档中的出现次数,用于后续相关性算分。
- 位置,记录单词在文档中的位置,用于做词语搜索。
- 偏移,记录单词在文档的开始和结束位置,用于做高亮显示。
Term和Match
Term:
- 完全匹配,精确查询,搜索前不会再对搜索词进行分词拆解。
Match:
- 搜索的时会先进行分词拆分,拆完后,再来匹配。
基础知识
基本语法
query:
- 代表查询,搜索 类似于SQL的select关键字。
aggs:
- 代表聚合,类似于SQL的group by关键字,对查询出来的数据进行聚合,求平均值最大值等。
highlight:
- 对搜索出来的结果中的指定字段进行高亮显示,搜索 中华人民共和国万岁,结果里面符合搜索关键字 全部是红色的高亮显示。
sort:
- 指定字段对查询结果进行排序显示,类比SQL的order by关键字。
from和size:
- 对查询结果分页,类似于SQL的limit关键字。
post_filter:
- 后置过滤器,在聚合查询结果之后,再对查询结果进行过滤。
字段类型
string类型
text类型
keyword类型
数值类型
日期类型
布尔类型
二进制
query和filter
query:
即某条文档是否匹配一个查询语句,这种查询模式下做两件事:
搜索出匹配查询语句的文档
计算每条文档的匹配度,并放在
_score metadatafiled 中使用场景:
- 使用相关性评分的全文搜索场景,注重匹配度而不是精准度
如何使用:
- 通过 es
search_api执行,参数里包含 query 部分filter
即某条文档是否匹配,只做一件事:
- 搜索出符合 filter 条件语句的文档,不会打分
使用场景:
- 注重精准匹配,常见的如在某一段时间的记录、按照某个
key:value搜索
分词
分词是指将文本转换成一系列单词的过程,也叫做文本分析。
举一个分词简单的例子:
比如你输入
Mastering Elasticsearch,会自动帮你分成两个单词:
- 一个是
mastering- 另一个是
elasticsearch- 可以看出单词也被转化成了小写的
索引和搜索分词
文本分词会发生在两个地方:
- 创建索引:
- 当索引文档字符类型为
text时,在建立索引时将会对该字段进行分词。- 搜索:
- 当对一个
text类型的字段进行全文检索时,会对用户输入的文本进行分词。
分词器测试
可以通过
_analyzerAPI来测试分词的效果。
COPY# 过滤html 标签
POST _analyze
{
"tokenizer":"keyword", #原样输出
"char_filter":["html_strip"], # 过滤html标签
"text":"<b>hello world<b>" # 输入的文本
}
指定分词器
创建索引时指定分词器:
如果设置手动设置了分词器,ES将按照下面顺序来确定使用哪个分词器:
- 先判断字段是否有设置分词器,如果有,则使用字段属性上的分词器设置。
- 如果设置了
analysis.analyzer.default,则使用该设置的分词器。- 如果上面两个都未设置,则使用默认的
standard分词器。
字段指定分词器:
为
title属性指定分词器:
COPYPUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace"
}
}
}
}
设置默认分词器:
COPYPUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
}
}
}
}
}
搜索时如何确定分词器:
在搜索时,通过下面参数依次检查搜索时使用的分词器:
- 搜索时指定
analyzer参数。- 创建
mapping时指定字段的search_analyzer属性。- 创建索引时指定
setting的analysis.analyzer.default_search。- 查看创建索引时字段指定的
analyzer属性。- 如果上面几种都未设置,则使用默认的
standard分词器。
指定analyzer:
搜索时指定
analyzer查询参数。
COPYGET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
指定字段analyzer:
COPYPUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
指定默认default_seach:
COPYPUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
},
"default_seach":{
"type":"whitespace"
}
}
}
}
}
内置分词器
| 分词器 | 说明 |
|---|---|
| Standard Analyzer | 默认分词器,按词切分,小写处理,停用词处理默认关闭 |
| Simple Analyzer | 按照非字母切分,非字母的都被去除,小写处理 |
| Stop Analyzer | 小写处理,停用词过滤 |
| Whitespace Analyzer | 按照空格切分,不转小写 |
| Keyword Analyzer | 不分词,直接将输入内容进行输出 |
| Pattern Analyzer | 正则表达式,默认\W+(非字母符号分割) |
| Language | 提供30多种常见语言的分词器 |
| Customer Analyzer | 自定义分词器 |
| 分析器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| standard | 标准分析器是默认的分析器,如果没有指定,则使用该分析器。 它提供了基于文法的标记化(基于 Unicode 文本分割算法,如 Unicode 标准附件 # 29所规定) ,并且对大多数语言都有效。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. |
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] |
| simple | 简单分析器将文本分解为任何非字母字符的标记,如数字、空格、连字符和撇号、放弃非字母字符,并将大写字母更改为小写字母。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. |
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| whitespace | 空格分析器在遇到空白字符时将文本分解为术语 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. |
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] |
| stop | 停止分析器与简单分析器相同,但增加了删除停止字的支持。默认使用的是 _english_ 停止词。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. |
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] |
| keyword | 不分词,把整个字段当做一个整体返回 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. |
[The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] |
| pattern | 模式分析器使用正则表达式将文本拆分为术语。正则表达式应该匹配令牌分隔符,而不是令牌本身。正则表达式默认为 w+ (或所有非单词字符)。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. |
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| 多种西语系 arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english等等 | 一组旨在分析特定语言文本的分析程序。 |
中文分词
中文分词器最简单的是
ik分词器,还有jieba分词,哈工大分词器等。
| 分词器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
ik_smart |
ik分词器中的简单分词器,支持自定义字典,远程字典 | 学如逆水行舟,不进则退 | [学如逆水行舟,不进则退] |
ik_max_word |
ik_分词器的全量分词器,支持自定义字典,远程字典 | 学如逆水行舟,不进则退 | [学如逆水行舟,学如逆水,逆水行舟,逆水,行舟,不进则退,不进,则,退] |
集群
节点
Master
- 节点负责管理集群状态信息,包括处理创建、删除索引等请求,决定分片被分配到哪个节点,维护和更新集群状态。
- 值得注意的是,只有Master节点才能修改集群的状态信息,并负责同步给其他节点。
Coordinator:
- 协调节点负责接收客户端的请求,将请求路由到到合适的节点,并将结果汇集到一起。
Data:
数据节点是保存数据的节点,增加数据节点可以解决水平扩展和解决数据单点的问题。
按照冷热区分具体的还有:
data_contentdata_hotdata_warmdata_coldIngest:预处理节点是数据前置处理转换的节点,支持Pipeline管道设置,可以对数据进行过滤、转换等操作。
分片
分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。
单台机器无法存储大量数据,es可以将一个索引中的数据切分称多个shard,分布在多台机器上存储。
- 有了shard就可以横向扩展,存储更多数据。
主分片:
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
副分片:
一个副本分片只是一个主分片的拷贝。
副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
文档到分片的映射算法:
Hash保证数据均匀分布在分片中,Routing作为关键参数,默认为文档ID,
number_of_primary_shards为主分片数。
- 主分片数一旦设定,不能更改,为了保证文档对应的分片不会发生改变。
shard = hash(routing)%number_of_primary_shards
集群健康状态
ES的健康状态分为三种:
Greed,绿色:表示所有主分片和副本分片都正常分配。
Yellow,黄色:表示所有主分片都正常分配,但有副本分片未分配。
Red,红色:表示有主分片未分配。
ELK
ELK是一套完整的日志收集以及展示的解决方案,分别是ElasticSearch、Logstash 和 Kibana。
Logstash:一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
Kibana:提供了分析和可视化的 Web 平台,可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
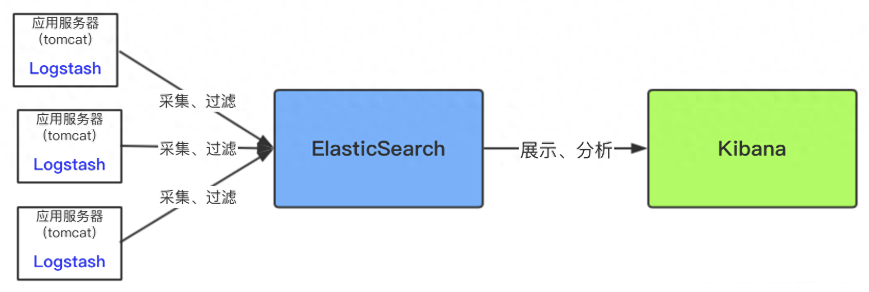
常见架构
这种架构对数据源服务器(即应用服务器)性能影响较大。
因为Logsash是需要安装和运行在需要收集的数据源服务器(即应用服务器)中,然后将收集到的数据实时进行过滤,过滤环节很耗时间和资源,过滤完成后才传输到ES中。
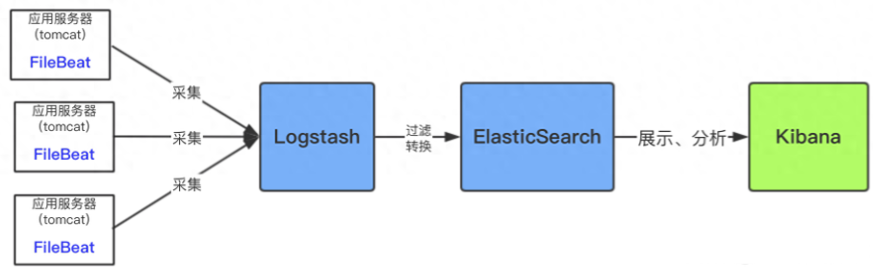
优化架构
FileBeat采集日志有效降低了收集日志对业务系统的系统资源的消耗。
通过LogStash服务器可以过滤,转换日志,这样即满足了日志的过滤转换,也保障了业务系统的性能。
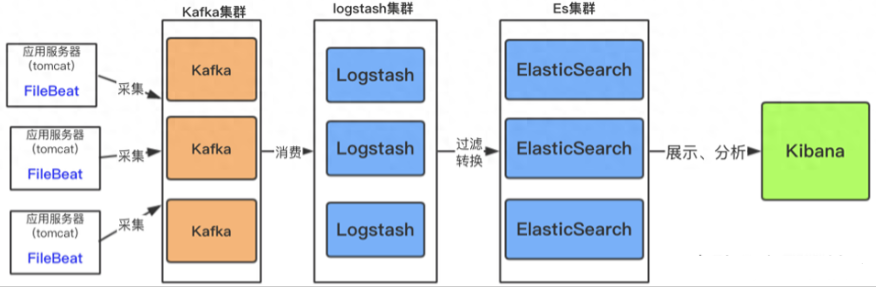
如果日志文件量特别大,以及收集的服务器日志比较多,需加入消息中间件做一下缓冲。
性能优化
数据预热
对于那些比较热的,经常会有人访问的数据,做一个专门的缓存预热子系统,对热数据每隔一段时间,就提前访问一下,让数据进入 ES内存 里面去,这样下次别人访问的时候,一定性能会好一些。
冷热分离
将冷数据写入一个索引中,然后热数据写入另外一个索引中。
这样可以确保热数据在被预热之后,尽量都让他们留在 ES内存 里,别让冷数据给冲掉。
基本原理
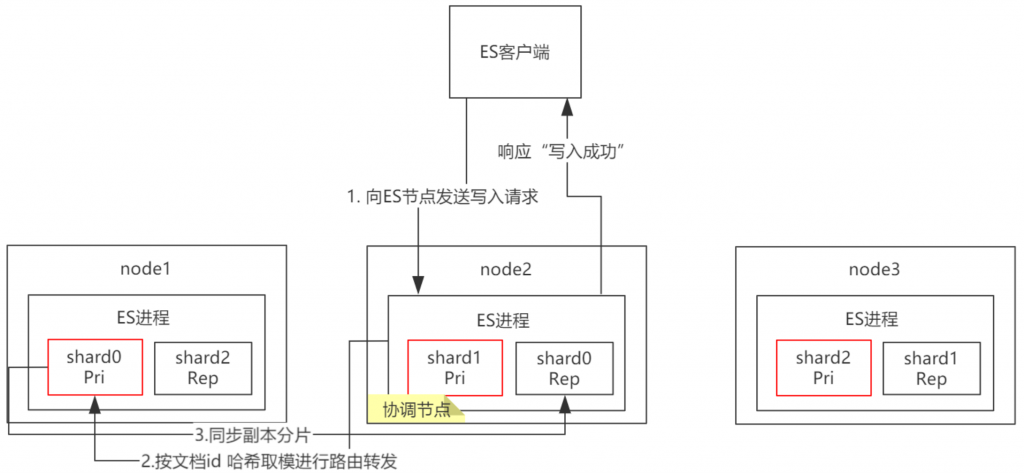
文档写入流程
客户端发送任何一个请求到任意一个节点,这个节点就成为协调节点 (coordinate node)。
协调节点对新增document(可以手动设置
doc id,也可以由系统分配)的id号进行哈希取值。再根据分片的数量进行取模,得到的数量就是具体的节点,然后将请求转发给对应node。
node上的primary shard处理请求,然后将数据同步到replica node。
协调节点如果发现primary shard所在的node和所有的replica shard所对应的 node 都搞定之后,就会将请求返回给客户端。
文档提取流程
客户端发送任何一个请求到任意一个node,这个节点就成为协调节点。
协调节点对文档id进行哈希路由,此时会使用round-robin随机轮询算法,在主分片以及所有的副本分片中随机选择一个,让读请求负载均衡。
数据提取完毕,返回document给协调节点。
协调节点再将数据返回给客户端。

文档搜索过程
文档搜索和提取的区别:
文档提取:一次性获取一个文档。
文档搜索:一次性获取多个文档。
客户端发送一个请求给协调节点(coordinate node)。
协调节点将搜索的请求转发给所有shard对应的primary shard或replica shard。
query phase:
- 每一个shard将自己搜索的结果(其实也就是一些唯一标识),返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最后的结果。
fetch phase :
- 接着由协调节点,根据唯一标识去各个节点进行拉取数据,最后汇总返回给客户端。

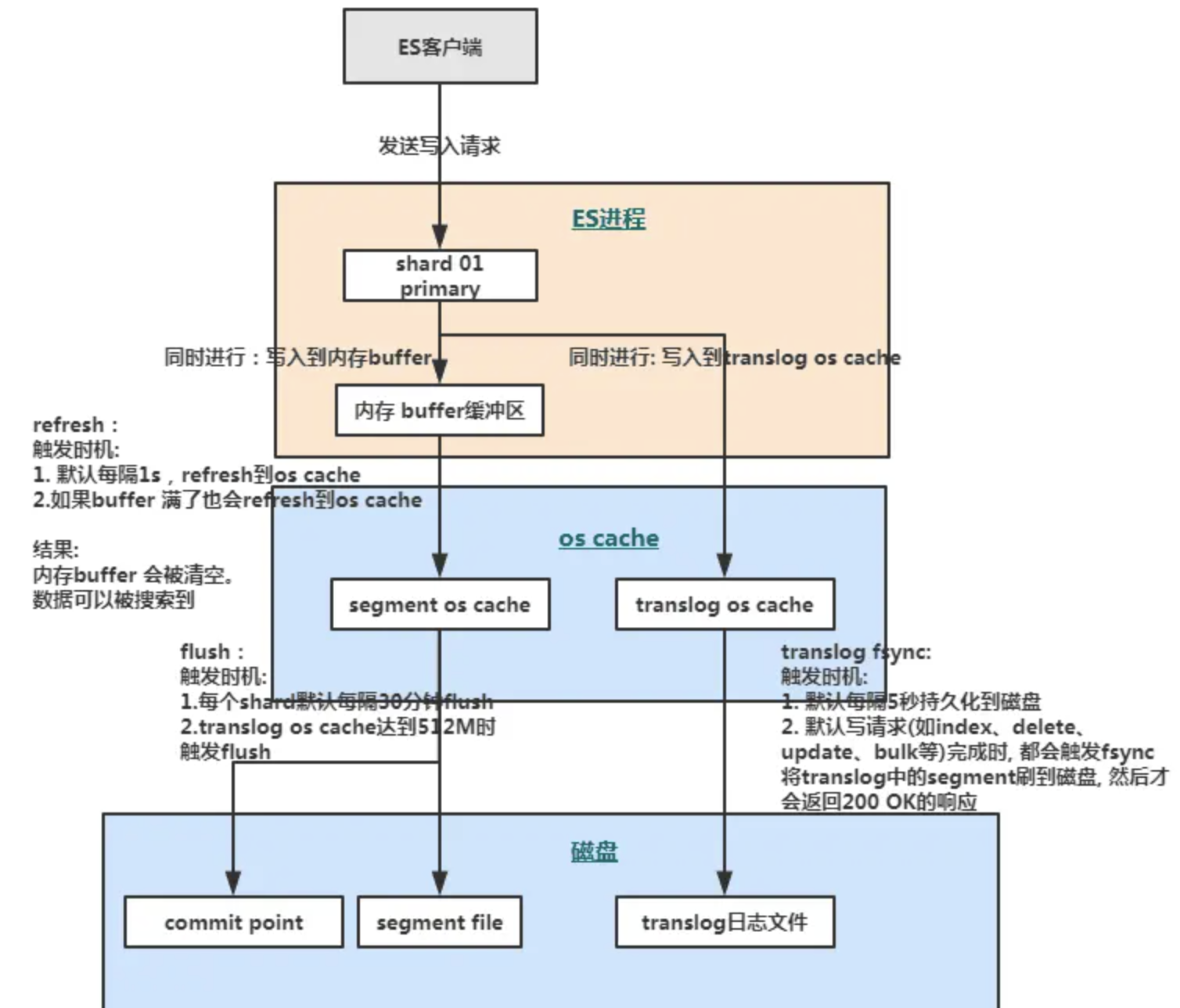
文档写入的底层原理
refresh:
ES 接收数据请求时先存入 ES 的内存中,默认每隔一秒会从内存 buffer 中将数据写入操作系统缓存 os cache。
到了 os cache 数据就能被搜索到(所以ES 是近实时的,因为1s 的延迟后执行 refresh 便可让数据被搜索到)。
fsync:
- translog 会每隔5秒或者在一个变更请求完成之后执行一次 fsync 操作,将 translog 从缓存刷入磁盘,这个操作比较耗时,如果对数据一致性要求不是跟高时建议将索引改为异步,如果节点宕机时会有5秒数据丢失。
flush:
- ES 默认每隔30分钟会将 os cache 中的数据刷入磁盘,同时清空 translog 日志文件。
merge:
- ES 的一个 index 由多个 shard 组成,而一个 shard 其实就是一个 Lucene 的 index,它又由多个 segment 组成,且 Lucene 会不断地把一些小的 segment 合并成一个大的 segment。
- 执行索引操作时,ES会先生成小的segment,ES 有离线的逻辑对小的 segment 进行合并,优化查询性能。
- 但是合并过程中会消耗较多磁盘 IO,会影响查询性能。
删除和更新过程
删除和更新都是写操作,但是由于 Elasticsearch 中的文档是不可变的,因此不能被删除或者改动以展示其变更。
- 所以 ES 利用 .del 文件 标记文档是否被删除,磁盘上的每个段都有一个相应的
.del文件。如果是删除操作,文档其实并没有真的被删除,而是在
.del文件中被标记为 deleted 状态。
- 该文档依然能匹配查询,但是会在结果中被过滤掉。
如果是更新操作,就是将旧的 doc 标识为 deleted 状态,然后创建一个新的 doc。
每次segment merge 的时候,会将多个 segment 文件合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,不写入到新的 segment 中,然后将新的 segment 文件写入磁盘,这里会写一个 commit point ,标识所有新的 segment 文件,然后打开 segment 文件供搜索使用,同时删除旧的 segment 文件。
应用场景
深度分页
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本)维护成本高,需要维护一个 scroll_id |
海量数据的导出需要查询海量结果集的数据 |
search_after |
高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果,它不适用于大幅度跳页查询 | 海量数据的分页 |
如果数据量小(from+size在10000条内),或者只关注结果集的TopN数据,可以使用
from/size分页。数据量大,深度翻页,后台批处理任务(数据迁移)之类的任务,使用
scroll方式。数据量大,深度翻页,用户实时、高并发查询需求,使用
search after方式。
From/Size参数:
在ES中,分页查询默认返回最顶端的10条匹配hits。
如果需要分页,需要使用from和size参数。
- from参数:需要跳过的hits数,默认为0。
- size参数:需要返回的hits数目的最大值。
这里表示从搜索结果中取第100条开始的10条数据。
POST /my_index/my_type/_search
{
"query": { "match_all": {}},
"from": 100,
"size": 10
}
Scroll:
可以把
Scroll理解为关系型数据库里的Cursor,并不适合用来做实时搜索,而更适合用于后台批处理任务,比如群发。
Scroll不是为了实时查询数据,而是为了一次性查询大量的数据(甚至是全部的数据)。
Scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个Scroll查询时的快照。
- 在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。
Scroll可以分为初始化和遍历两部分:
初始化时:
- 将所有符合搜索条件的搜索结果缓存起来。
- 注意:这里只是缓存的
doc_id,而并不是真的缓存了所有的文档数据,取数据是在fetch阶段完成的,可以想象成快照。遍历时:
- 从这个快照里取数据,也就是说,在初始化后,对索引插入、删除、更新数据都不会影响遍历结果。
POST /twitter/tweet/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
初始化指明
index和type,然后,加上参数scroll,表示暂存搜索结果的时间。会返回一个
_scroll_id,_scroll_id用来下次取数据用。缺点:
scroll_id会占用大量的资源(特别是排序的请求)。Scroll后接超时时间,频繁的发起Scroll请求,会出现一些列问题。- 生成的历史快照,对于数据的变更不会反映到快照上。
优点:
- 适用于非实时处理大量数据的情况,比如要进行数据迁移或者索引变更之类的。
POST /_search?scroll=1m
{
"scroll_id":"XXXXXXXXXXXXXXXXXXXXXXX I am scroll id XXXXXXXXXXXXXXX"
}
Scroll Scan:
ES提供了
Scroll Scan方式进一步提高遍历性能,但是Scroll Scan不支持排序,因此Scroll Scan适合不需要排序的场景。
search_type:赋值为scan,表示采用Scroll Scan的方式遍历,同时告诉Elasticsearch搜索结果不需要排序。scroll:传时间。size:表示的是每个 shard 返回的 size 数,最终结果最大为number_of_shards * size。
Scroll Scan与Scroll的区别:
- 没有排序,按index顺序返回,没有排序,可以提高取数据性能。
- 初始化时只返回
_scroll_id,没有具体的hits结果。- size控制的是每个分片的返回的数据量,而不是整个请求返回的数据量。
POST /my_index/my_type/_search?search_type=scan&scroll=1m&size=50
{
"query": { "match_all": {}}
}
Sliced Scroll:
每个
Scroll请求,可以分成多个Slice请求,可以理解为切片,各Slice独立并行,比用Scroll遍历要快很多倍。
POST /index/type/_search?scroll=1m
{
"query": { "match_all": {}},
"slice": {
"id": 0,
"max": 5
}
}
POST ip:port/index/type/_search?scroll=1m
{
"query": { "match_all": {}},
"slice": {
"id": 1,
"max": 5
}
}
Search After:
Search_after是 ES5 新引入的一种分页查询机制,其原理几乎就是和Scroll一样的。
SEARCH_AFTER不是自由跳转到任意页面的解决方案,而是并行滚动多个查询的解决方案。
最佳实践
Coordinator节点
当集群规模下,读写压力不大时可以考虑Master/Data混部。
Master和Data节点分离的好处是降低了Master的压力,避免被读写影响。
独立Coordinator节点进一步提高读写性能,相当于把Query和Fetch两个节点的压力分流。
节点JVM堆内存
ES 堆内存不要超过 32G,31G 最好(压缩普通对象指针问题)
机器内存富余可以多加节点:
- 如果查询多聚合少可以减少节点(把内存分给 Lucence,增大索引缓存)
- 如果聚合多查询少可以增加节点(把内存分给多个 Node,增加聚合内存)
ES的服务器,一半的内存都给到ES使用
内存对于Elasticsearch来说绝对是重要的,用于更多的内存数据提供更快的操作
而且还有一个内存消耗大户Lucene,Lucene的性能取决于和OS的交互,如果把所有的内存都分配给ElasticSearch,不留一点给Lucene,那全文检索性能会很差,建议是把50%的内存给ElasticSearch
高写集群
增加
refresh_interval:
- 对于数据实时性要求不高的场景,适当增加
refresh_interval时间。- ES默认的
refresh_interval是1s,即 doc 写入1s后即可被搜索到,如果业务对数据实时性要求不高的话,如日志场景,可将索引模版的refresh_interval设置成30s,这能够避免过多的小 segment 文件的生成及段合并的操作。Bulk 批量写入:
- 使用 Bulk 接口批量写入数据,每次 bulk 数据量大小控制在 10M 左右,可以提高写入吞吐。
集群参数调整
对于写入远远大于查询的集群(多半也可以理解成是离线集群,大部分时间都在同步数据):
- 适当调整
index buffer大小会提高吞吐量。
indices.memory.index_buffer_size: 10%
indices.memory.min_shard_index_buffer_size: 8mb
indices.memory.min_index_buffer_size: 48mb
这些参数都是node级别的,每个节点默认拿出10%的heap做为buffer加速写入,可以上当调大配置,在内存中尽量cache数据并build index,提高吞吐量。
另外要重新设置refresh/flush的时间,对于日志型集群,吞吐量的优先级更高,而业务集群更需要近似实时的查询能力,场景差异性较大。
index.translog.flush_threshold_ops: 800000
index.translog.flush_threshold_size: 512mb
index.translog.flush_threshold_period: 30m
index.translog.interval: 30s
index.translog.sync_interval: 5s
index.refresh_interval: 20s
高写入集群一定要重新设置translog相关的配置,默认的translog策略容易导致恢复时间过长的问题,建议根据监控指标设置
index.translog.flush_threshold_ops,尽快将已经存储到磁盘上的数据从translog中移除,负面效果就是磁盘的IO会提高(与索引不同,translog是必须fsync到磁盘上的)。同时,
index.refresh_interval也是关注的重点,增加index.refresh_interval时间可以降低IO/提高吞吐量,但是负面影响就是数据写入后在refresh之前没有办法查询。refresh/flush时间:
- 假设
index.refresh_interval=A,则index.translog.interval=[A, 2A]
批处理集群:
定时导数/补数的集群,都属于这一类,大部分时间用于查询,仅仅在某个时间段进行写入操作,短时间内写入大量数据。
这一类集群需要遵循以下几步操作:
- 更新待写入索引的settings,
index.refresh_interval设置为-1。
curl -XPUT "http://es.example.com:9200/your_index/_settings" -d '
{
"index" : {
"refresh_interval" : -1
}
}'
导入数据,推荐用bulk API。
调用
_refresh API刷新buffer。
curl -XPOST "http://es.example.com:9200/your_index/_refresh"
调用
_flush API同步到磁盘。
curl -XPOST "http://es.example.com:9200/your_index/_flush"
默认情况下Elasticsearch会通过定时refresh去build倒排索引,但是在执行批量导数任务的场景中并不需要这种近似实时的能力。
强制关闭refresh会提高吞吐量,待全部数据导入完毕后,手工refresh,然后再利用flush将数据刷新到磁盘上,并清空translog(会加快恢复)。
索引配置评估准则
单个分片大小控制在 30-50GB
集群总分片数量控制在 3w 以内
1GB 的内存空间支持 20-30 个分片为佳
一个节点建议不超过 1000 个分片
索引分片数量建议和节点数量保持一致
集群规模较大时建议设置专用主节点
专用主节点配置建议在 8C16G 以上
如果是时序数据,建议结合冷热分离+ILM 索引生命周期管理
合理的Index Mapping
特殊字段:如Boolean、IP、时间等
字符串:尽量使用keyword,默认的text会被analyze。
- keyword最大32766字节。
- 在仅查询的情况下,如果有 range 查询需求,使用 numeric,否则使用 keyword。
调整refresh间隔:
refresh_interval: 30s,默认的1秒会导致大量segment产生,影响性能。调整translog刷新机制为异步
创建新索引时,可以配置每个分片中的Segment的排序方式,index sorting是优化检索性能的非常重要的方式之一
查询
尽量使用filter而不是query。
- 使用filter不会计算评分score,只计算匹配。
如果不关心文档返回的顺序,则按
_doc排序。避免通配符查询。
不要获取太大的结果数据集,如果需要大量数据使用Scroll API。
关于数据聚合去重:
- Terms 指定字段聚合 + TopN:合理设置聚合的TopN,聚合结果是不精确的,是取每个分片的Top Size元素后综合排序后的值。
- ES5以后的新特性Collapse:按某个字段进行折叠,这个Collapse只针对query出来的结果,只能用在keyword或者numeric类型。
- ES6以后支持分页的聚合:Composite Aggregation,可以获取全量的聚合数据,只能用于Terms、Histogram、Date histogram、GeoTile grid。
field data cache
indices.fielddata.cache.size(node级别):节点用于 fielddata 的最大内存,如果 fielddata 达到该阈值,就会把旧数据交换出去。
该参数可以设置百分比或者绝对值。默认设置是不限制。
- 所以强烈建议设置该值,比如 30%。
之前遇到的问题是fielddata内存占满导致node oom 崩溃。