 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
延迟消息
延迟等级
官方默认设置了18个延迟等级。
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
发送延迟消息:
- 按照默认顺序1-18数字就对应上面的延迟时间。
Message msg = new Message(TOPIC, TAG, "OrderID188", "Hello world".getBytes(StandardCharsets.UTF_8));
//设置延迟等级
msg.setDelayTimeLevel(3);
producer.send(msg);
基本原理
延迟消息都会被存储到 RocketMQ 的一个内部 Topic
SCHEDULE_TOPIC_XXXX当中。
SCHEDULE_TOPIC_XXXX总共有 18 个 MessageQueue:
- 对应延迟消息的 18 个等级,根据指定的
DelayTimeLevel来决定选择哪个 MessageQueue。- 有一个定时任务,每100ms执行一次判断
SCHEDULE_TOPIC_XXXXTopic中的MessageQueue的消息是否到达延迟时间。- 到达延迟时间,将
SCHEDULE_TOPIC_XXXX中的消息投递到消息最初需要投递的Topic中。
为什么不支持任意时间?
RocketMQ并不支持任意时间的延迟,个人觉得主要的原因还是因为性能。如果提供任意时间,就会涉及到消息的排序,会有一定的性能损耗。
事务消息
Apache RocketMQ在4.3.0版中已经支持分布式事务消息。
RocketMQ采用了2PC的思想来实现了提交事务消息,同时增加一个补偿逻辑来处理二阶段超时或者失败的消息。
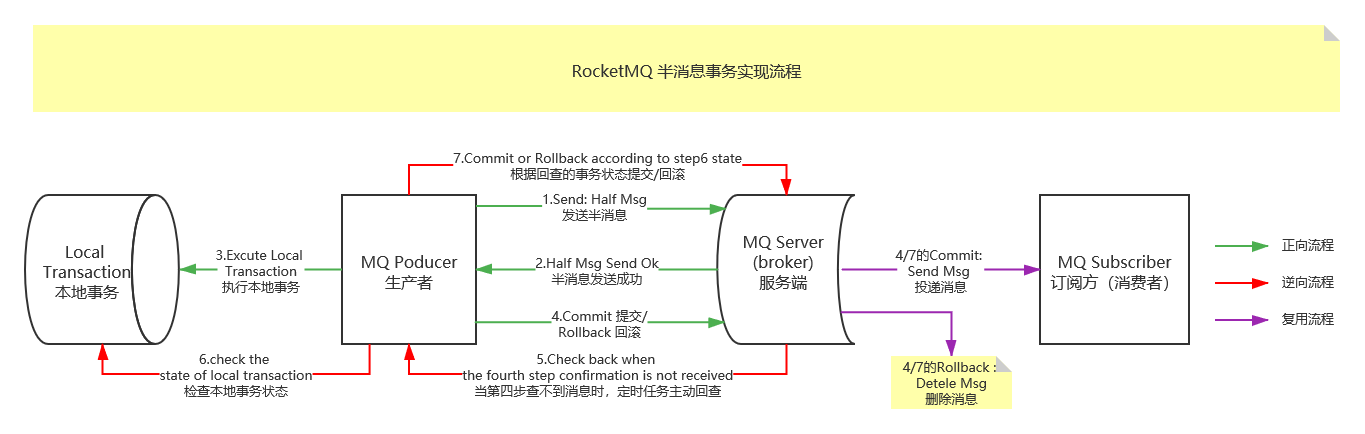
基本流程
第一阶段:
- 发送 Message,
Half Message,即半事务消息。- 此类型的
Message是不会被Consumer消费。第二阶段:如果半事务消息投递成功,则会开始执行本地事务。
分为如下三种
Case:
本地事务执行成功:
- 会向
Broker发送commit消息,被commit过后的Message才能被Consumer消费到。本地事务执行失败:
- 会向
Broker发送rollback消息,Broker则会将刚刚投递的半事务消息删除,从而保证上下游数据的一致性。如果
Producer实例或者网络出现了问题,Producer没能及时地将本地事务执行的结果通知Broker。
Broker会通过扫描发现某条Message长时间处于半事务消息状态。
Broker会主动地向Producer询问此Message对应的事务状态。
基本设计
采用2PC两阶段设计:
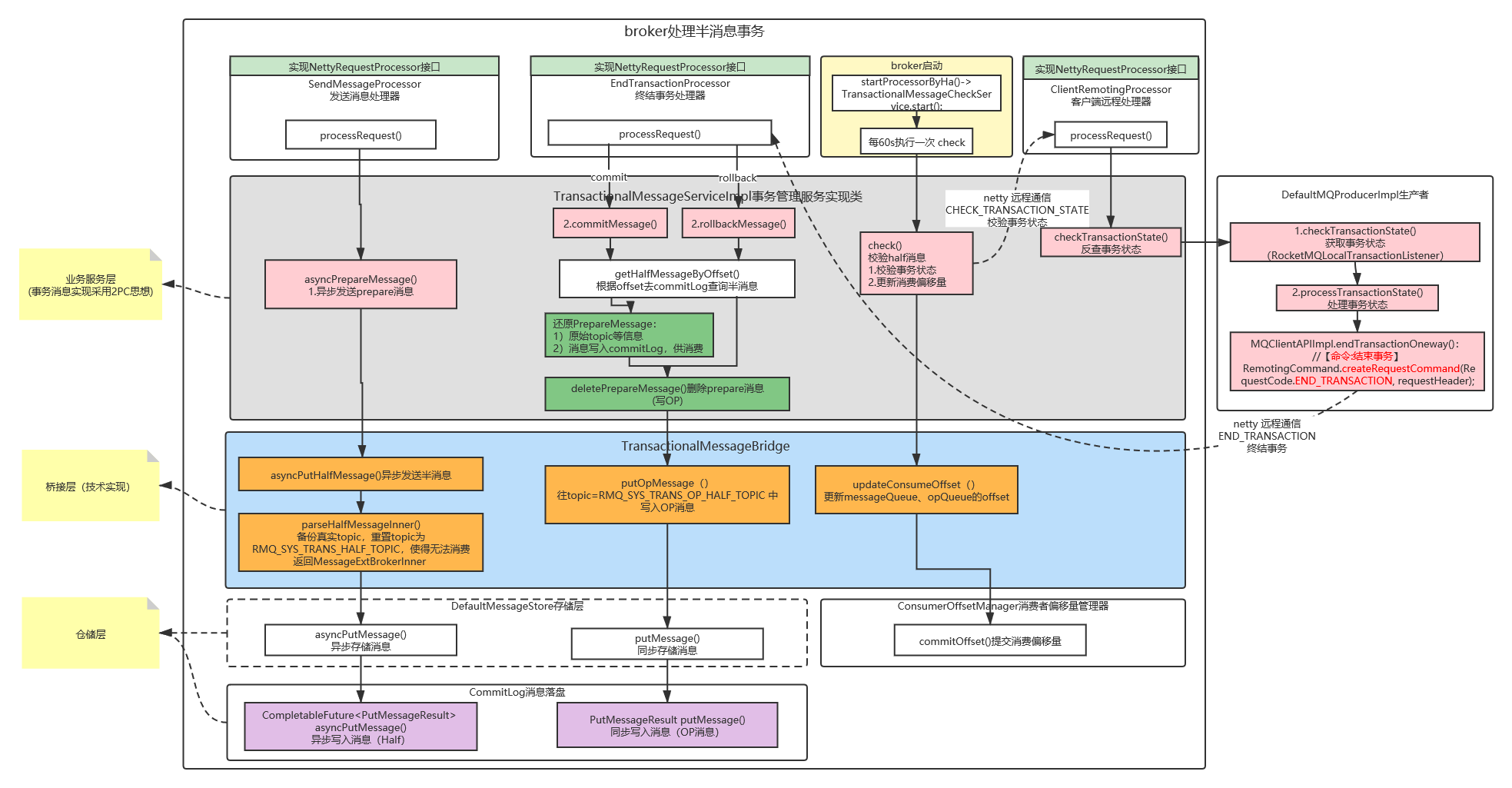
将
Message原本真实的Topic和MessageQueue进行备份。
- 放入到
PROPERTY_REAL_TOPIC、PROPERTY_REAL_QUEUE_ID中保存。将消息投递到一个内部
Topic中RMQ_SYS_TRANS_HALF_TOPIC,该队列专门存储事务消息。所有的
Half Message全部都写入到queueId为 0 的MessageQueue。因为一个
Topic下只有 1 个MessageQueue:
- 这个
Topic下的所有Message就是全局有序的,它们会按照先来后到的顺序被消费。如果本地事务执行成功进行
Commit,则将RMQ_SYS_TRANS_HALF_TOPIC队列中的消息投递到真实的Topic中,供后续流程执行。
- 并删除这条
Half Message,但删除也是假删除,只是给Message打上一个删除的Tag。如果本地事务执行失败进行
rollback,则直接删除这条Half Message,但删除也是假删除。如果本地事务迟迟没有返回结果 (默认时间是6s),则会触发事务回查机制
- 执行回查之前需要校验检查次数是否到达了最大值(需要手动设置,没有默认值)。
- 或者是当前
Half Message存在是否超过了Message保存的上限,即 3天。- 如果满足上面条件中的一种
Half Message会被放进TRANS_CHECK_MAX_TIME_TOPICTopic 当中。- 一旦判定为需要执行事务回查逻辑,那么当前这条
Half Message就算已经被消费了。- 在没达到最大的校验次数之前,都还需要将其投递到事务队列当中,以便下次重试时再次执行
Check逻辑。- 如果回查成功则删除投递的
Half Message。
消息重试
重试时间
消息消费失败后,并不会立即重试,而是有一个递增的时间间隔来进行重试,重试次数默认16次。
只比延迟消息的时间间隔等级少了前两个,延迟消息总共有 18 个等级。
- 而消息重试使用了原延迟消息的第
3 - 18等级
10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
基本原理
重试的
Message,RocketMQ的做法并不是将其投递回原Topic,而是重试队列。每个
ConsumerGroup都有自己的重试队列:
- 其名称是由特定的前缀拼接上
ConsumerGroup所组成,默认%RETRY%+消费者组名称。- 所以在
Consumer启动时,就会同时消费其ConsumerGroup对应的重试队列和普通队列。消费失败的
Message,Consumer会将其投回Broker:
- 相当于这条
Message已经被消费掉了,之后重试的只是内容相同、但实际不是同一条的Message。- 然后会校验重试的次数,如果达到16次则会进入死信队列 ,组成为
%DLQ%+消费者组名称。- 未达到最大重试次数,则会根据重试间隔时间等级将其投递到延迟队列
SCHEDULE_TOPIC_XXXX中。- 然后等到了延迟等级对应的时间之后,再投递到
ConsumerGroup所对应的重试队列当中,供后续消费。
消息存储
整体架构:
RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于一个
CommitLog中)。针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构。
Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至
CommitLog中。
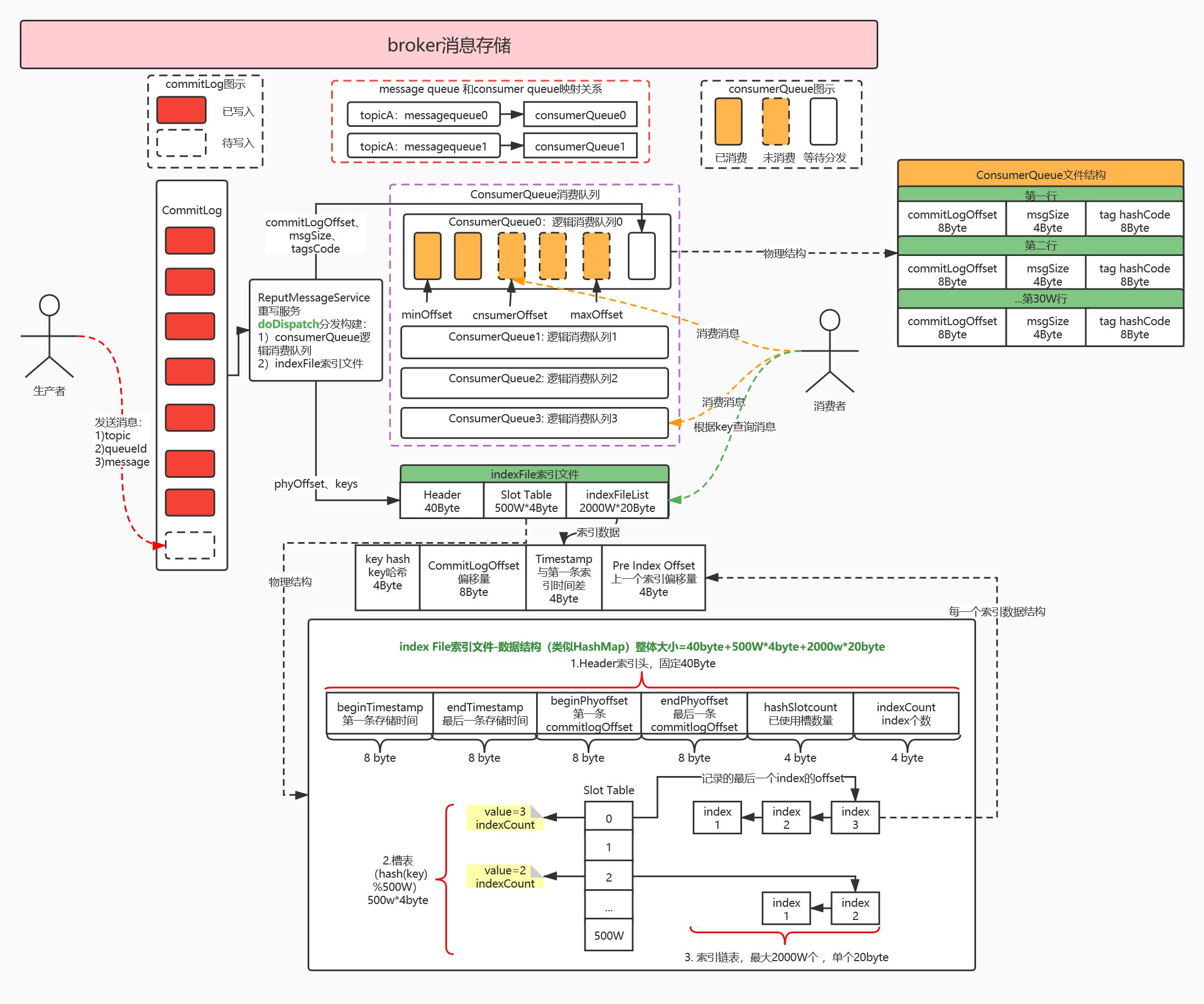
核心步骤:
1、首先,生产者根据topic发送消息,消息存储在commitLog中,1G一个文件,当文件满了,写入下一个文件。
2、其次,ReputMessageService重写消息服务执行2个分发操作:
- 创建ConsumerQueue逻辑消费队列:
- 参数:commitLogOffset 物理偏移量、msgSize 消息长度、tagsCode tag哈希。
- 创建IndexFile索引文件:
- 以创建时的时间戳命名。
3、最后,消费者根据topic、tag拉取消息消费,根据key查询消息。
重要文件:
commitLog消息日志:
- 消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容。
consumequeue逻辑消费队列:
- 存储了commitLog的起始物理offset,目的是提高消息消费的性能。
indexFile索引文件:
- 提供了一种可以通过key或时间区间来查询消息的方法。
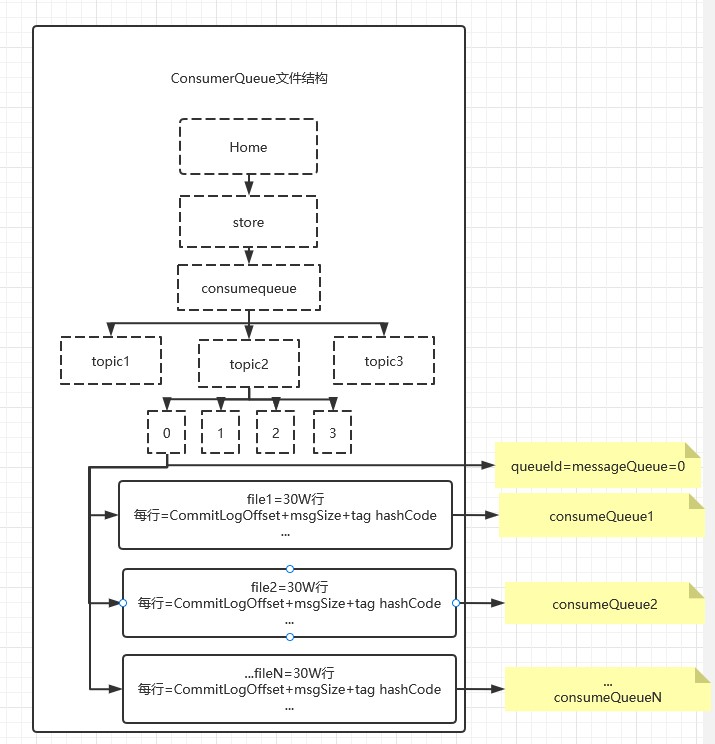
consumequeue文件:
consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M。
- 默认一个topic对应4个queueId,即4个messageQueue。
每个messageQueue文件夹下有多个consumeQueue,所以:messageQueue 1:N consumeQueue
通信机制
通信架构图
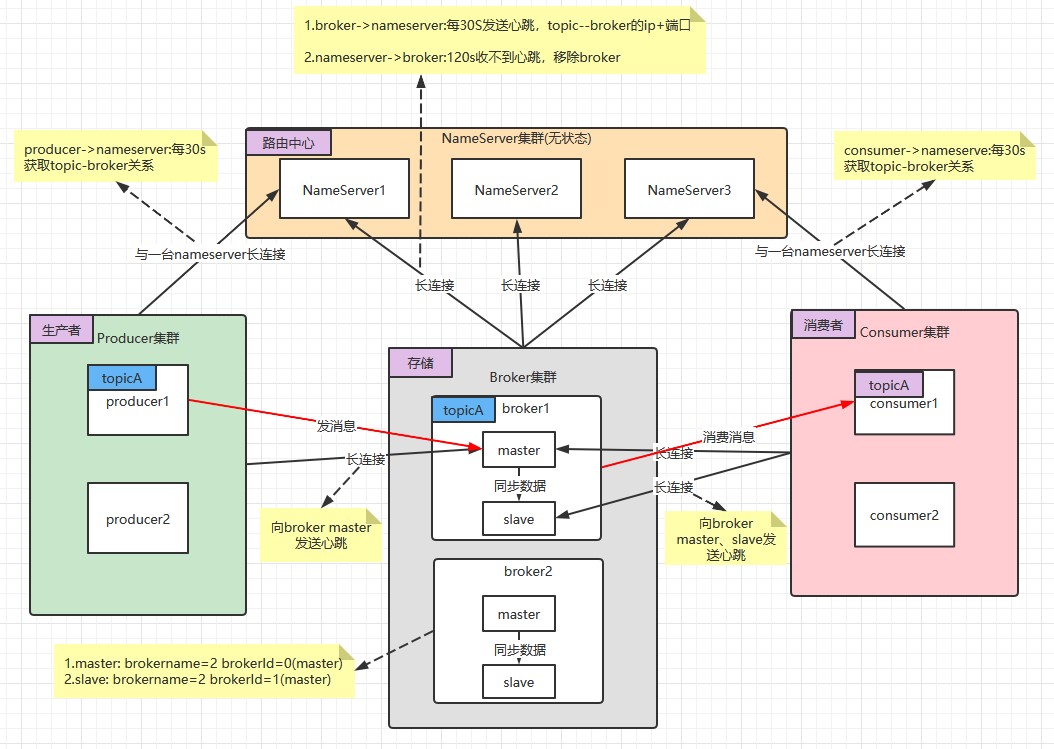
基本通讯流程如下:
- Broker启动后需要完成一次将自己注册至NameServer的操作,随后每隔30s时间定时向NameServer上报Topic路由信息。
- 消息生产者Producer作为客户端发送消息时候,需要根据消息的Topic从本地缓存的
TopicPublishInfoTable获取路由信息。
- 如果没有则更新路由信息会从NameServer上重新拉取,同时Producer会默认每隔30s向NameServer拉取一次路由信息。
- 消息生产者Producer根据获取的路由信息选择一个队列(MessageQueue)进行消息发送。
- Broker作为消息的接收者接收消息并落盘存储。
- 消息消费者Consumer根据获取的路由信息,并再完成客户端的负载均衡后,选择其中的某一个或者某几个消息队列来拉取消息并进行消费。
为了实现客户端与服务器之间高效的数据请求与接收:
RocketMQ-Remoting包自定义了通信协议并在Netty的基础之上扩展了通信模块。