 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
MongoDB是一款开源、跨平台、分布式,具有大数据处理能力的文档存储数据库。
MongoDB用于记录文档结构的数据,比如JSON、XML结构的数据。
适用场景
数据量大,读写操作频繁,数据价值较低,对事务要求不高。
数据结构
存储结构
文档(Document) :
- MongoDB 中最基本的单元,由 BSON 键值对组成,类似于关系型数据库中的行(Row)。
集合(Collection) :
- 一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
数据库(Database) :
- 一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
SQL与MongoDB常见术语对比 :
| SQL | MongoDB |
|---|---|
| 表(Table) | 集合(Collection) |
| 行(Row) | 文档(Document) |
| 列(Col) | 字段(Field) |
| 主键(Primary Key) | 对象 ID(Objectid) |
| 索引(Index) | 索引(Index) |
| 嵌套表(Embeded Table) | 嵌入式文档(Embeded Document) |
| 数组(Array) | 数组(Array) |
文档
MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
- 字段的值可能包括其他文档、数组和文档数组。
- https://www.mongodb.com/docs/manual/reference/bson-types/

文档的键是字符串,除了少数例外情况,键可以使用任意 UTF-8 字符:
- 键不能含有
\0(空字符),这个字符用来表示键的结尾。.和$有特别的意义,只有在特定环境下才能使用。- 以下划线
_开头的键是保留的(不是严格要求的)。
BSON 是 Binary JSON的简称,是 JSON 文档的二进制表示,支持将文档和数组嵌入到其他文档和数组中,还包含允许表示不属于JSON 规范的数据类型的扩展。
BJSON 的遍历速度优于 JSON,这也是 MongoDB 选择 BSON 的主要原因,但 BJSON 需要更多的存储空间。
集合
MongoDB 集合存在于数据库中,没有固定的结构,也就是 无模式 的,这意味着可以往集合插入不同格式和类型的数据。
- 通常情况插入集合中的数据都会有一定的关联性。

集合不需要事先创建,当第一个文档插入或者第一个索引创建时,如果该集合不存在,则会创建一个新的集合。
集合名可以是满足下列条件的任意 UTF-8 字符串:
- 集合名不能是空字符串
""。- 集合名不能含有
\0(空字符),这个字符表示集合名的结尾。- 集合名不能以
system.开头,这是为系统集合保留的前缀。
system.users集合保存着数据库的用户信息。system.namespaces集合保存着所有数据库集合的信息。- 集合名必须以下划线或者字母符号开始,并且不能包含
$。
数据库
数据库用于存储所有集合,而集合又用于存储所有文档。
一个 MongoDB 中可以创建多个数据库,每一个数据库都有自己的集合和权限。
数据库名可以是满足以下条件的任意 UTF-8 字符串:
- 不能是空字符串
""。- 不得含有
' '(空格)、.、$、/、\和\0(空字符)。- 应全部小写。
- 最多 64 字节。
数据库名最终会变成文件系统里的文件。
数据类型
String:存储变长的字符串
Number:存储整数或浮点型小数
Boolean:存储true、flase两个布尔值
Date:存储日期和时间
Array:可以存储由任意类型组成的数组
Embedded-Document:可以将其他结构的文档,嵌套到一个文档的字段中
Binary:存储由0、1组成的二进制数据,如图像、音/视频等
Code:MongoDB支持直接存储JavaScript代码
Timestamp:存储格林威治时间(GMT)的时间戳
GeoJSON:存储地理空间数据
Text:存储大文本数据
事务
3.0版本中,引入WiredTiger存储引擎,开始支持单文档事务
4.0版本中,开始支持多文档事务,以及副本集(主从复制)架构下的事务
4.2版本中,开始支持分片集群、分片式多副本集架构下的事务类比
MySQL,MongoDB支持了分片集群中的事务,而MySQL只支持主从集群下的事务,并不支持分库环境下的事务
MongoDB不适用于强事务的场景,原因如下:
MongoDB的事务必须在60s内完成,超时将自动取消(因为要考虑分布式环境)涉及到事务的分片集群中,不能有仲裁节点
事务会影响集群数据同步效率、节点数据迁移效率
多文档事务的所有操作,必须在主节点上完成,包括读操作
索引
官方文档:https://www.mongodb.com/docs/manual/indexes
早版本的
MongoDB中,索引底层默认使用B-Tree结构
4.x版本后,MongoDB推出了V2版索引,默认使用变种B+Tree来作为索引的数据结构(和MySQL索引的数据结构相同)复合索引:
- 指基于多个字段创建的索引
唯一索引:
- 基于唯一索引查找数据时,找到第一个满足条件的数据,就会立马停止匹配
部分索引:
- 使用字段的一部分开创建索引,要结合
partialFilterExpression选项来实现TTL索引:
- 可以基于它实现过期自动删除的效果
- 主要依靠
expireAfterSeconds选项来创建,不过只能在Date、ISODate类型的字段上,建立TTL索引为什么
TTL索引必须基于Date类型的字段创建?
- 因为
MongoDB会使用该字段的值,作为计算的起始时间- 如果在一个
Date数组类型的字段上建立TTL索引,MongoDB会使用其中最早的时间来计算过期时间
Explain工具
执行
explain命令,输出了特别多的信息,主要关注stage这个值,类似于MySQL-explain的type字段代表着本次语句的查询类型,该字段可能会出现以下值:
COLLSCAN:扫描整个集合进行查询IXSCAN:通过索引进行查询COUNT_SCAN:使用索引在进行count操作COUNTSCAN:没使用索引在进行count操作FETCH:根据索引键去磁盘拿具体的数据SORT:执行了sort排序查询LIMIT:使用了limit限制返回行数SKIP:使用了skip跳过了某些数据IDHACK:通过_id主键查询数据SHARD_MERGE:从多个分片中查询、合并数据SHARDING_FILTER:通过mongos对分片集群执行查询操作SUBPLA:未使用索引的$or查询TEXT:使用全文索引进行查询PROJECTION:本次查询指定了返回的结果集字段(投影查询)
集群
MongoDB副本集群源自于主从集群,但在主从的基础上做了很大拓展,其中总共有三种节点角色:
Primary主节点:拥有读写能力,为集群内的副本节点,提供数据拷贝的支持Replicate副本节点:拥有读能力,数据完全拷贝自主节点,即主从概念中的从节点Arbiter仲裁节点:不具备读写能力,用于故障恢复,提供故障检测、选举投票能力仲裁节点作用等同于哨兵节点,但它并不是副本集群必须存在的节点。
- 因为主节点、副本节点都拥有投票能力,它的存在只是为了维护集群内的平衡,如集群节点为偶数时,可以添加一个仲裁节点,让集群保持奇数特性,确保每轮选举一次就能推出新主,避免多轮无效竞选的现象出现。
分片
以往的副本集会受到硬件配置的限制,如果写性能出现瓶颈,只能依靠拉高
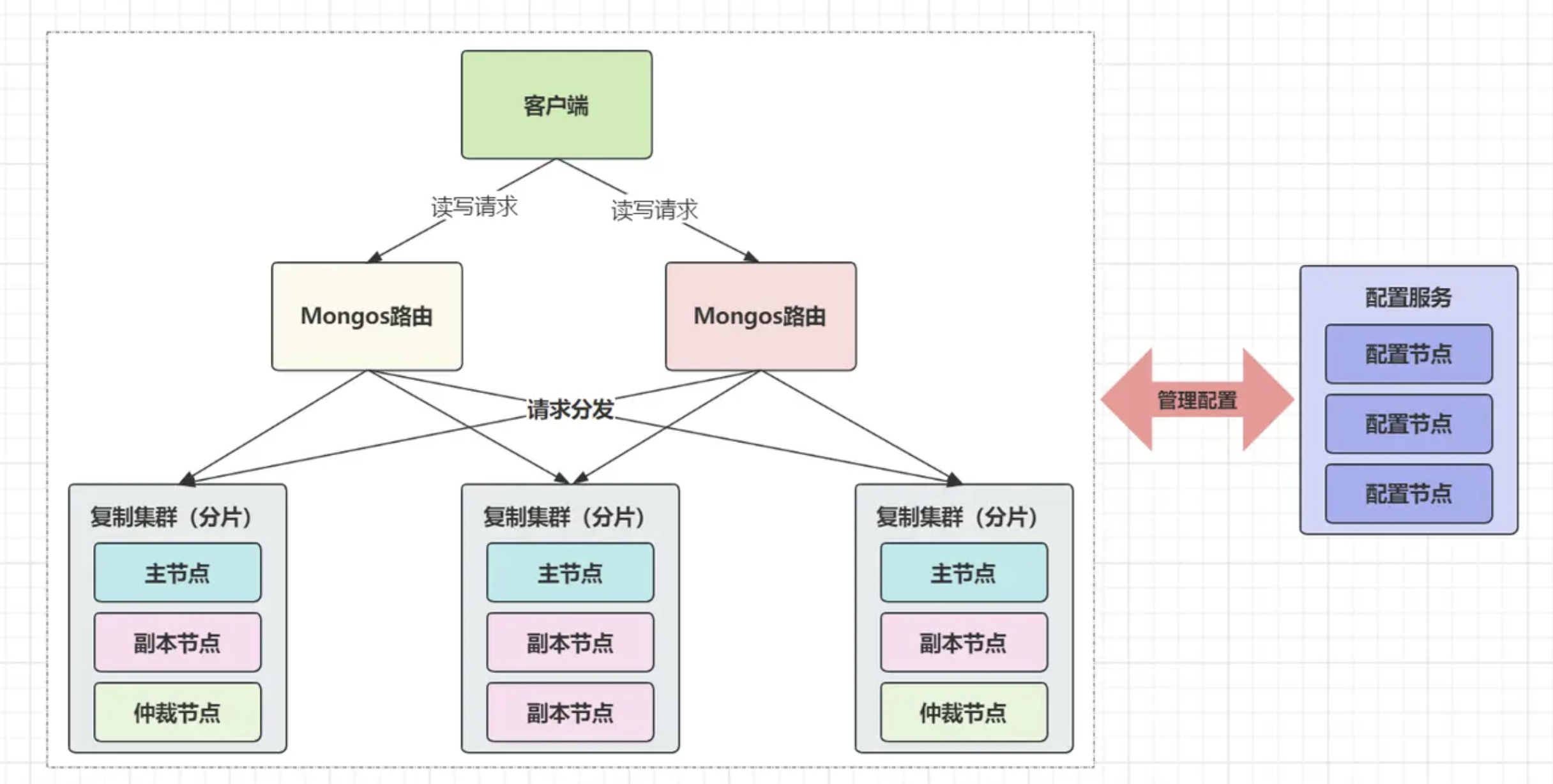
CPU、内存配置来提升性能,而分片集群无需考虑这点,毕竟整个集群都是由不同节点组合对外服务,如果性能出现瓶颈,只需要继续增加分片节点即可,相较于副本集群,分片集群的上限更高。分片集群总共有三种角色:
Router路由:负责接收、分发客户端的读写请求,类似于代理中间件Shard分片:存储数据、处理读写请求的具体节点Config配置:存储路由、分片节点的元数据和配置信息路由可以由一或多个
mongos节点组成,config同理,而shard则并非单独的mongodb节点,而是一个个的replicaSet复制集(副本集群)。当一个写入请求出现时,
Mongos会找到配置的分片键,再使用已配置的分片规则进行计算,从而得出本次数据要落入的分片,最后将该写入请求分发到对应的分片即可。
在集群的分片动态伸缩(数量发生变化)时,会自动触发数据迁移机制,由
MongoDB内部来自动维护数据的平衡,无需任何外力介入!这个功能,无论在
Redis、还是分库分表中,都需要开发者手动完成数据迁移,维护成本特别高。
集群原理
自动切主:
成为主节点的依据是:获得集群内大多数节点的投票(节点数量一半以上的票数)。
集群初始化时:由于其他节点还未添加进集群,所以集群内只有执行初始化的这一个节点,它会给自己投一票,此时就只有它自己,所以它会理所当然的成为集群内的第一代主节点,如果集群后续期间一直正常,则不会触发新一轮的选举。
整个集群内部的工作阶段:
故障检测:当一个节点感知到其他节点不可用时,会先发起通信向其他可用节点进行二次确认
故障处理:如果检测到主节点不可用,从节点会将自己转换为候选人,并向其他成员宣布
选举开始:轮次号加一,开启一轮新的选举,每个候选人节点开始向其他成员发送拉票请求
投票开始:在一个新的选举轮次中,每个节点只能投一票,可以投给自己或者其他节点
投票结束:所有节点已投票,或抵达本轮选举的时间限制后,将获得大多数投票的节点立为新主
主从切换:新主会向其他节点发送 上位 消息,其他节点更新自己的配置,接受新主上位
数据同步:完成主从切换后,从节点以新主为数据基准,校验自身数据是否完整,有缺失则同步
上述每一步都是由
MongoDB集群自动完成,无需任何外力介入
故障检测:
检测出一个集群节点是否故障,主要依靠心跳机制来完成,集群每个成员会以
10s一次为频率,定期向其他成员发出心跳包,从而告知其他节点自己还活着。当某个节点不再发出心跳时,其他节点将无法收到心跳包,此时会有一或多个节点率先发现问题,将会判定这个没有心跳的节点出现故障。
为了避免网络波动、延迟、故障带来的误判,率先发现问题的节点,会向集群内的其他成员发起通讯,从其他成员那里二次确认,是否收到了 故障节点 的心跳?
- 如果其他成员收到了,当前节点不会进行额外处理。
- 如果其他成员也未收到,当前节点会通知所有成员,故障节点已经下线。
- 如果其他节点均未回复,当前节点会认为自己网络出现了问题,或者整个集群不可用,当前节点会停止工作,尝试重连恢复。
- 还有一种情况,当从节点去主节点同步数据时,如果发现自己无法连接到主节点时,这时从节点也会试图向其他节点发起通信,二次确认主节点是否故障。
故障处理:
其余节点收到故障节点下线的通知后,集群内所有存活的节点,会判断此次下线的节点身份,如果是从节点或仲裁节点,存活节点只会修改自身的集群配置,将下线的节点从集群中剔除。
如果此次下线的是主节点,集群内的所有从(副本)节点,会将自己转换为候选人角色,并通知其他节点自己想成为新主。
如果集群内有仲裁节点,仲裁节点收到主节点下线的消息后,并不会将自己转变为候选人,因为仲裁节点只有投票权,没有竞选权!
选举机制
当主节点下线、并且集群内出现候选人时,整个集群会开启新的选举轮次(
term),每个轮次都会拥有一个唯一的轮次号(标识)集群内第一个成为候选人的节点,会递增轮次号,同时率先向其他节点发出选举请求,并把自己的票投给自己
新一轮的选举可能由好几种原因触发:
- 通过心跳机制,检测到主节点不可用、并向其余节点已确认主节点下线的情况
- 从节点同步数据,无法正常连接主节点
- 主节点优先级降低,或具有较高优先级的新节点加入集群
- 开发者在主节点上手动执行
rs.stepDown()命令时
投票开始
新一轮的选举开始后,当集群内的其他从节点收到拉票请求时,可以选择给其他节点投票,或者把票投给自己、向集群宣布自己也想成为新主,并向其余节点发出拉票请求。
如果收到拉票请求的节点,角色属于仲裁节点,它无法将票投给自己,只能选择投给其他节点。
集群内存在多个候选人时,仲裁节点投票时,会遵循先到先得的原则,先收到谁的拉票请求,就把自己的票投给对应节点。
如果同时收到多个候选人拉票时,此时则会通过
oplog操作日志来判断哪个节点的数据最新,该值越高的节点享有越高的竞票权。并不是所有从节点,在收到其他从节点拉票时,会把票投给自己、转变为新的候选人开始拉票。
- 只有当收到的拉票请求,其数据比自己老时,才会将票投给自己。
oplog:从节点的操作日志,用于记录主节点的写操作,一个从节点的操作日志越新,说明数据和旧主越接近。
投票结束
当集群内所有存活节点都已投票后,投票阶段将会结束,但如果集群内有节点迟迟不投票,此时选举会陷入僵局,所以每轮选举都有时间限制,如果超出了该限制还未投票的节点,将会被视为弃权。
投票阶段结束后,集群各个从节点会交换各自的票数,只有当获得大多数节点投票的从节点,才有资格成为新主,具体的数字为:集群节点数量的一半+1。
- 如果集群的可用节点小于数量的一半时,整个集群将会陷入不可写入状态,只处理读请求。
某些情况下,投票结束后的状况会更极端一点,比如两个从节点,获得的票数相同,推选谁成为新主?
- 此时则会比对两个从节点的
oplog,也就是看谁的数据更完整,谁就会成为新主。如果两个节点的票数、
oplog一模一样,谁作为新主?
MongoDB给每个节点设计了priority优先级的概念,每个节点的优先级默认为1,仲裁节点的为0,表示没有竞选权。特殊情况,有
A、B两个节点票数相同,但A的oplog最新,B的priority值最高,谁会成为新的主节点?
- 是
A,因为如果数据落后的B成为了新主,那么数据比它更新的A节点,还需要把多出来的那部分数据删掉,显然并不合理。如果两个节点的票数、
oplog、priority完全相同,谁会成为新主?
- 都不会,而是会触发一轮新的选举过程,重复前面的步骤,直到选出新主为止。
- 这也是为什么建议集群节点数量保持在奇数的原因,节点数量为奇数时,几乎不会出现票数持平的现象。
如果集群从节点数量为偶数,得加入一个仲裁节点,或者将某个节点的优先级调高,保证极端情况下,不会由于票数持平而触发重新选举。
主从切换
新主会向其他成员发送:自己成为新主,以及选举轮次号,其余节点收到后,会先对比轮次号,是不是自己投票过的那轮选举。
如果不是,说明期间触发过新的选举,而自己没有参与进去,此时该节点会否定这次的新主,又会触发新的选举。
如果轮次号与自己投票的相同,收到信息的节点则会认可新主,接着变更自己的配置,将原本的旧主标为下线状态,竞选胜利的从节点标为新主。
数据同步
在主从切换完成后,新的主节点会向所有从节点发送
oplog,以此来同步数据,其余从节点会拿自身的oplog与之比对,如果发现不完整,则会主动去新主上拉取缺少的数据,从而确保集群内所有节点的数据一致性。
- 如果触发了选举过程,集群将会陷入不可用状态,只有当选举、数据同步完成后,才会恢复对外部的数据读写服务。
常用操作
常用命令
查询所有数据库:
show dbs;或show databases;切换/创建数据库:
use 库名;查看目前所在的数据库:
db;查看
MongoDB目前的连接信息:db.currentOp();查看当前数据库的统计信息:
db.stats();删除数据库:
db.dropDatabase("库名");查看库中的所有集合:
show collections;或show tables;显式创建集合:
db.createCollection("集合名");查看集合统计信息:
db.集合名.stats();查看集合的数据大小:
db.集合名.totalSize();删除指定集合:
db.集合名.drop();