 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
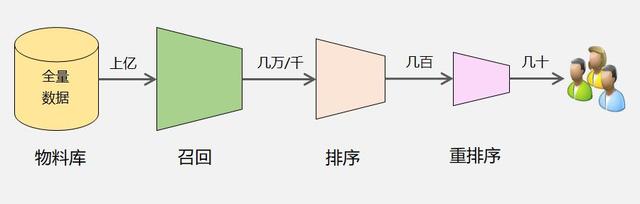
推荐系统本质上就是一个信息过滤系统,通常分为:召回、排序、重排序这3个环节。
每个环节逐层过滤,最终从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户。
应用场景
推荐系统的应用场景通常分为以下两类:
- 基于用户维度的推荐:
- 根据用户的历史行为和兴趣进行推荐,比如淘宝首页的猜你喜欢、抖音的首页推荐等。
- 基于物品维度的推荐:
- 根据用户当前浏览的标的物进行推荐,比如打开京东APP的商品详情页,会推荐和主商品相关的商品给你。
搜索、推荐、广告
搜索:
- 有明确的搜索意图,搜索出来的结果和用户的搜索词相关。
推荐:
- 不具有目的性,依赖用户的历史行为和画像数据进行个性化推荐。
广告:
- 借助搜索和推荐技术实现广告的精准投放,可以将广告理解成搜索推荐的一种应用场景,技术方案更复杂,涉及到智能预算控制、广告竞价等。
整体架构
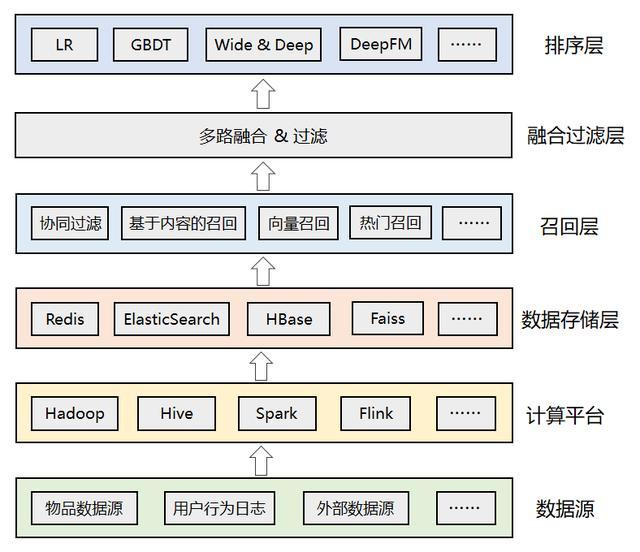
各层的主要作用如下:
- 数据源:
- 推荐算法所依赖的各种数据源,包括物品数据、用户数据、行为日志、其他可利用的业务数据、甚至公司外部的数据。
- 计算平台:
- 负责对底层的各种异构数据进行清洗、加工,离线计算和实时计算。
- 数据存储层:
- 存储计算平台处理后的数据,根据需要可落地到不同的存储系统中,比如Redis中可以存储用户特征和用户画像数据,ES中可以用来索引物品数据,Faiss中可以存储用户或者物品的Embedding向量等。
- 召回层:
- 包括各种推荐策略或者算法,比如经典的协同过滤,基于内容的召回,基于向量的召回,用于托底的热门推荐等。
- 为了应对线上高并发的流量,召回结果通常会预计算好,建立好倒排索引后存入缓存中。
- 融合过滤层:
- 触发多路召回,由于召回层的每个召回源都会返回一个候选集,因此这一层需要进行融合和过滤。
- 排序层:
- 利用机器学习或者深度学习模型,以及更丰富的特征进行重排序,筛选出更小、更精准的推荐集合返回给上层业务。
从数据存储层到召回层、再到融合过滤层和排序层,候选集逐层减少,但是精准性要求越来越高。
因此也带来了计算复杂度的逐层增加,这个便是推荐系统的最大挑战。
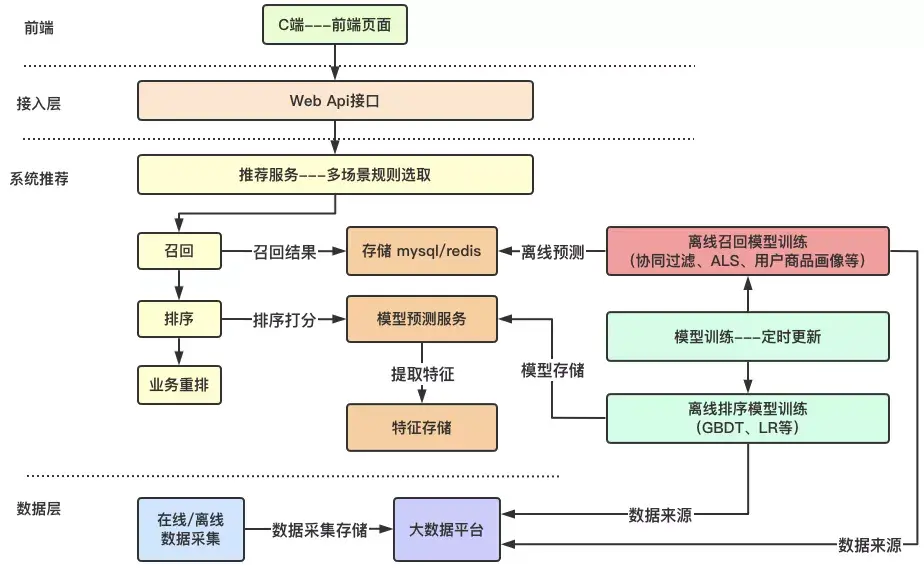
我们通过在终端进行埋点,收集用户行为日志,存储到大数据平台。
集合业务数据,收集用户偏好行为数据,如:收藏、点赞、评论等,存储到大数据平台。
基于大数据平台的数据,通过一些算法对数据进行分析,得到一个训练模型。
通过训练出来的模型,就可以获得相关的推荐数据。
把获得的推荐数据保存到mysql/redis等持久化工具中。
特征和算法
对于推荐引擎来说,最核心的部分主要是两块:特征和算法。
特征计算由于数据量大,通常采用大数据的离线和实时处理技术,像Spark、Flink等。
然后将计算结果保存在Redis或者其他存储系统中(比如HBase、MongoDB或者ES),供召回和排序模块使用。
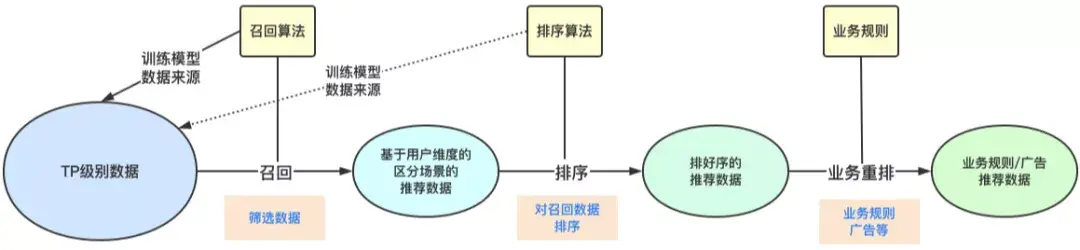
召回算法的作用是:
- 从海量数据中快速获取一批候选数据,要求是快和尽可能的准。
- 这一层通常有丰富的策略和算法,用来确保多样性,为了更好的推荐效果,某些算法也会做成近实时的。
排序算法的作用是:
- 对多路召回的候选集进行精细化排序。
- 它会利用物品、用户以及它们之间的交叉特征,然后通过复杂的机器学习或者深度学习模型进行打分排序,这一层的特点是计算复杂但是结果更精准。
协同过滤算法
协同过滤算法的核心就是找相似,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合。
基于用户的协同过滤:
User-CF,核心是找相似的人。
用户 A 和用户 C 都购买过物品 a 和物品 b,那么可以认为 A 和 C 是相似的,因为他们共同喜欢的物品多。
这样,就可以将用户 A 购买过的物品 d 推荐给用户 C 。
基于物品的协同过滤:
Item-CF,核心是找相似的物品。
物品 a 和物品 b 同时被用户 A,B,C 购买了,那么物品 a 和 物品 b 被认为是相似的,因为它们的共现次数很高。
这样,如果用户 D 购买了物品 a,则可以将和物品 a 最相似的物品 b 推荐给用户 D。
UserCF适用场景
在新闻网站中,用户的兴趣不是特别细化,绝大多数用户都喜欢看热门的新闻。
ItemCF适用场景
在图书、电子商务和电影网站,比如亚马逊、豆瓣、Netflix中,ItemCF 则能极大地发挥优势。