
Dubbo学习总结!
Dubbo学习总结!
月伴飞鱼官网:https://cn.dubbo.apache.org/zh-cn/
搭建Dubbo源码环境
直接从官方仓库 https://github.com/apache/dubbo Fork 到自己的仓库。
1 | git clone git@github.com:xxxxxxxx/dubbo.git |
然后切换分支,因为目前最新的是 Dubbo 3.2 版本。
1 | git checkout -b dubbo-3.2 dubbo-3.2 |
执行 mvn 命令进行编译:
1 | mvn clean install -Dmaven.test.skip=true |
执行下面的命令转换成 IDEA 项目:
1 | mvn idea:idea // 要是执行报错,就执行这个 mvn idea:workspace |
在 IDEA 中导入源码,因为这个导入过程中会下载所需的依赖包,所以会耗费点时间。
配置总线URL
Dubbo 中任意的一个实现都可以抽象为一个 URL,Dubbo 使用 URL 来统一描述了所有对象和配置信息。
protocol:dubbo 协议。username/password:用户名和密码。host/port:172.17.32.91:20880。path:org.apache.dubbo.demo.DemoService。parameters:参数键值对。
1 | dubbo://172.17.32.91:20880/org.apache.dubbo.demo.DemoService?anyhost=true&application=dubbo-demo-api-provider&dubbo=2.0.2&interface=org.apache.dubbo.demo.DemoService&methods=sayHello,sayHelloAsync&pid=32508&release=&side=provider×tamp=1593253404714dubbo://172.17.32.91:20880/org.apache.dubbo.demo.DemoService?anyhost=true&application=dubbo-demo-api-provider&dubbo=2.0.2&interface=org.apache.dubbo.demo.DemoService&methods=sayHello,sayHelloAsync&pid=32508&release=&side=provider×tamp=1593253404714 |
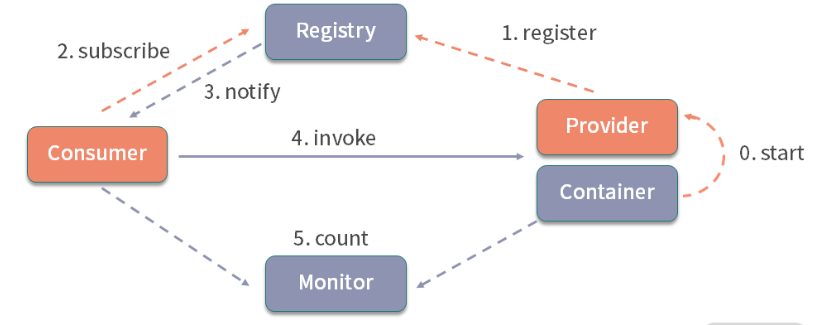
核心架构
Registry:注册中心
负责服务地址的注册与查找,服务的 Provider 和 Consumer 只在启动时与注册中心交互。
注册中心通过长连接感知 Provider 的存在,在 Provider 出现宕机的时候
- 注册中心会立即推送相关事件通知 Consumer。
Provider:服务提供者
- 在它启动的时候,会向 Registry 进行注册操作
- 将自己服务的地址和相关配置信息封装成 URL 添加到 ZooKeeper 中。
Consumer:服务消费者
在它启动的时候,会向 Registry 进行订阅操作。
订阅操作会从 ZooKeeper 中获取 Provider 注册的 URL,并在 ZooKeeper 中添加相应的监听器。
获取到 Provider URL 之后,Consumer 会根据负载均衡算法从多个 Provider 中选择一个 Provider 并与其建立连接
- 最后发起对 Provider 的 RPC 调用。
如果 Provider URL 发生变更,Consumer 将会通过之前订阅过程中在注册中心添加的监听器
- 获取到最新的 Provider URL 信息,进行相应的调整
- 比如断开与宕机 Provider 的连接,并与新的 Provider 建立连接。
Consumer 与 Provider 建立的是长连接,且 Consumer 会缓存 Provider 信息,所以一旦连接建立
- 即使注册中心宕机,也不会影响已运行的 Provider 和 Consumer。
Monitor:监控中心
用于统计服务的调用次数和调用时间。
Provider 和 Consumer 在运行过程中,会在内存中统计调用次数和调用时间
- 定时每分钟发送一次统计数据到监控中心。
SPI机制
Dubbo 按照 SPI 配置文件的用途,分成了三类目录。
META-INF/services/目录:
- 用来兼容 JDK SPI。
META-INF/dubbo/目录:
- 存放用户自定义 SPI 配置文件。
META-INF/dubbo/internal/目录:
- 存放 Dubbo 内部使用的 SPI 配置文件。
Dubbo 将 SPI 配置文件改成了 KV 格式,例如:
1 | dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol |
key:扩展名(也就是 ExtensionName)
- 当我们在为一个接口查找具体实现类时,可以指定扩展名来选择相应的扩展实现。
例如,这里指定扩展名为 dubbo,Dubbo SPI 就知道要使用:
org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol这个扩展实现类
- 只实例化这一个扩展实现即可,无须实例化 SPI 配置文件中的其他扩展实现类。
通信协议
Dubbo协议:
- 缺省协议,采用单一长连接和
NIO异步通讯
- 适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
时间轮定时任务
JDK 提供的简单的定时任务管理:
- 其底层实现使用的是堆这种数据结构
- 存取操作的复杂度都是
O(nlog(n)),无法支持大量的定时任务。时间轮是一种高效的、批量管理定时任务的调度模型。
- 在定时任务量比较大、性能要求比较高的场景中
- 为了将定时任务的存取操作以及取消操作的时间复杂度降为
O(1),一般会使用时间轮的方式。时间轮一般会实现成一个环形结构,类似一个时钟,分为很多槽
- 一个槽代表一个时间间隔,每个槽使用双向链表存储定时任务。
- 指针周期性地跳动,跳动到一个槽位,就执行该槽位的定时任务。
Dubbo 的时间轮实现位于
dubbo-common模块的org.apache.dubbo.common.timer包中。
Dubbo中如何使用定时任务:
在 Dubbo 中,时间轮并不直接用于周期性操作,而是只向时间轮提交执行单次的定时任务
- 在上一次任务执行完成的时候,调用
newTimeout()方法再次提交当前任务,这样就会在下个周期执行该任务。即使在任务执行过程中出现了 GC、I/O 阻塞等情况,导致任务延迟或卡住
- 也不会有同样的任务源源不断地提交进来,导致任务堆积。
Dubbo 中对时间轮的应用:
失败重试:
- 例如,
Provider向注册中心进行注册失败时的重试操作
- 或是
Consumer向注册中心订阅时的失败重试等。周期性定时任务:
- 例如,定期发送心跳请求,请求超时的处理
- 或是网络连接断开后的重连机制。
序列化机制
Apache Avro:
- Avro 依赖于用户自定义的 Schema,在进行序列化数据的时候,无须多余的开销,就可以快速完成序列化。
- 生成的序列化数据也较小,当进行反序列化的时候,需要获取到写入数据时用到的 Schema。
- 在 Kafka、Hadoop 以及 Dubbo 中都可以使用 Avro 作为序列化方案。
FastJson:
- 阿里开源的 JSON 解析库,可以解析 JSON 格式的字符串。
- 它支持将 Java 对象序列化为 JSON 字符串,反过来从 JSON 字符串也可以反序列化为 Java 对象。
- FastJson 比 Jackson 快 20% 左右,但是近几年 FastJson 的安全漏洞比较多。
Fst(Fast-Serialization):
- 100% 兼容 JDK 原生环境,序列化速度大概是JDK 原生序列化的 4~10 倍。
- 序列化后的数据大小是 JDK 原生序列化大小的 1⁄3 左右。
Kryo:
- 目前 Twitter、Yahoo、Apache 等都在使用该序列化技术,特别是 Spark、Hive 等大数据领域用得较多。
- Kryo 的特点是 API 代码简单,序列化速度快,并且序列化之后得到的数据比较小。
Hessian2:
Hessian2 序列化之后的数据可以进行自描述,不会像 Avro 那样依赖外部的 Schema 描述文件或者接口定义
在 Dubbo 中使用的 Hessian2 序列化并不是原生的 Hessian2 序列化
- 而是阿里修改过的
Hessian Lite,它是 Dubbo 默认使用的序列化方式其序列化之后的二进制流大小大约是 Java 序列化的 50%
- 序列化耗时大约是 Java 序列化的 30%,反序列化耗时大约是 Java 序列化的 20%
Protobuf(Google Protocol Buffers):
- 相比于常用的 JSON 格式,Protobuf 有更高的转化效率,时间效率和空间效率都是 JSON 的 5 倍左右。
- Protobuf 可用于通信协议、数据存储等领域,它本身是语言无关、平台无关、可扩展的序列化结构数据格式。
- GRPC 底层就是使用 Protobuf 实现的序列化。
负载均衡
Dubbo 提供了 几种 种负载均衡实现:
- 随机负载均衡:RandomLoadBalance
- 随机的选择一个,是Dubbo的默认负载均衡策略
- 基于 Hash 一致性:ConsistentHashLoadBalance
- 相同参数的请求总是落在同一台机器上
- 基于权重随机算法:RandomLoadBalance
- 基于最少活跃调用数算法:LeastActiveLoadBalance
- 相同活跃数的随机
- 活跃数指调用前后计数差,使慢的
Provider收到更少请求
- 因为越慢的
Provider的调用前后计数差会越大- 基于加权轮询算法:RoundRobinLoadBalance
- 基于最短响应时间:ShortestResponseLoadBalance
源码模块
dubbo-common 模块:
- Dubbo 的一个公共模块,其中有很多工具类以及公共逻辑
dubbo-remoting 模块:
- Dubbo 的远程通信模块,其中的子模块依赖各种开源组件实现远程通信
dubbo-rpc 模块:
- Dubbo 中对远程调用协议进行抽象的模块,其中抽象了各种协议,依赖于 dubbo-remoting 模块的远程调用功能
dubbo-cluster 模块:
- Dubbo 中负责管理集群的模块,提供了负载均衡、容错、路由等一系列集群相关的功能
- 最终的目的是将多个 Provider 伪装为一个 Provider
- 这样 Consumer 就可以像调用一个 Provider 那样调用 Provider 集群了
dubbo-registry 模块:
- Dubbo 中负责与多种开源注册中心进行交互的模块,提供注册中心的能力
dubbo-monitor 模块:
- Dubbo 的监控模块,主要用于统计服务调用次数、调用时间以及实现调用链跟踪的服务
dubbo-config 模块:
- Dubbo 对外暴露的配置都是由该模块进行解析的
dubbo-configcenter 模块:
- Dubbo 的动态配置模块,主要负责外部化配置以及服务治理规则的存储与通知
广播响应
对于一个Dubbo消费者,广播调用多个Dubbo提供者
- 该消费者可以收集所有服务提供者的响应结果。
广播调用所有服务提供者,逐个调用,并且可以完整的返回所有服务提供者的执行结果(正确或异常)
- 并将所有服务提供者的响应结果存于
RpcContext。
服务下线
Dubbo 服务消费端会使用 Zookeeper 里面的 Watch 来针对 Zookeeper 端的
/providers节点注册监听。
- 一旦这个节点下的子节点发生变化,
Zookeeper就会发送一个事件通知 Dubbo Client 端。Dubbo Client 端收到事件以后,就会把本地缓存的这个服务地址删除,完成服务下线。
泛化调用
一般情况下我们通过
RPC调用接口提供方的服务,首先在消费端嵌入提供方的Jar包,从而使用Jar包中的类和方法。在通用的
API网关系统中,考虑到扩展性和维护成本,不会使用服务提供方客户端的JAR包,而是通过泛化调用。其中的原理跟普通的
RPC调用时一致的,网络、序列化、反射这些底层的技术原理一致。
- 区别在于参数和返回值都用
Map来表示。任何一个成熟的
RPC框架都会支持泛化调用,比如Dubbo提供的泛化。泛化接口调用方式主要用于客户端没有
API接口的情况,参数及返回值中的所有入参出参均用Map表示,通常用于框架集成。
- 比如:实现一个通用的
API网关或者服务测试框架。
可通过 GenericService 调用所有服务实现:
1 | import org.apache.dubbo.rpc.service.GenericService; |










{kind=link}