 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}

大家好呀,我是飞鱼。
大家在用 ChatGPT 的 API 时,是按 Token 计费的。
❝
例如,你提问消耗了 100 Token,ChatGPT 根据你的输入,回答了 200 Token,那么一共消费的 Token 数就是 300。
一些文章里面,模型后面带着 8K、32K,甚至 100K,这是指模型能处理的最大 Token 长度。
那什么是大模型中的 Token?
❝
大模型(自然语言模型)处理的信息通常是文本。
但是,计算机直接处理文本是很困难的,因为它只能理解数字和二进制代码。
- 所以,我们需要把文本转换成计算机能理解的格式。
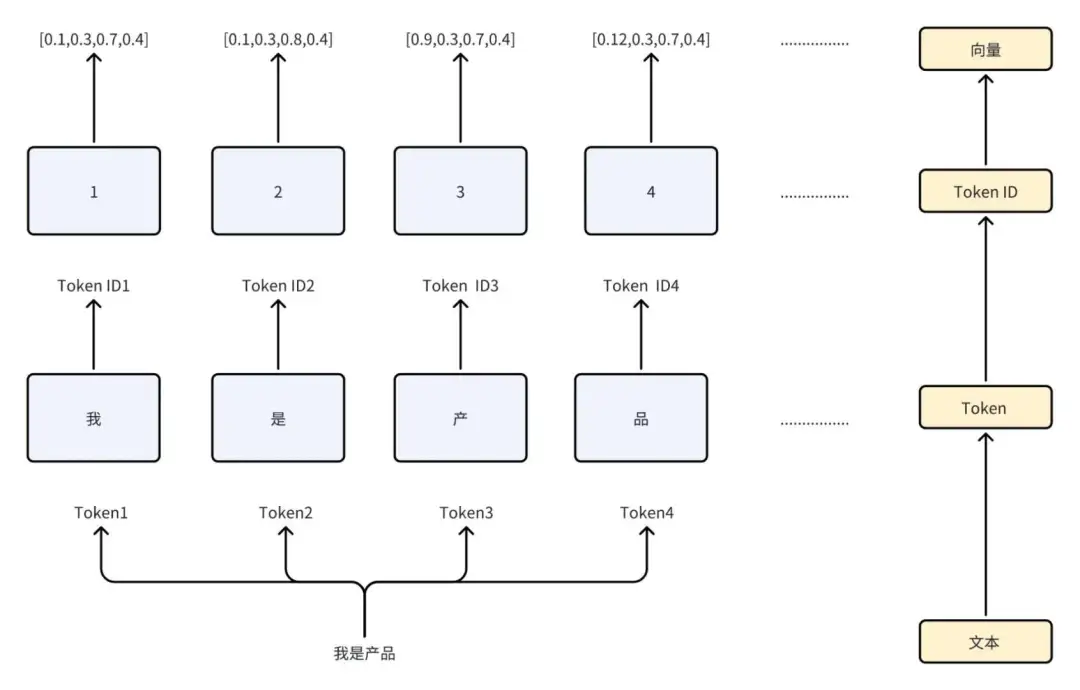
Token 可以理解为对输入文本进行分割和编码时的最小单位,它可以是单词、子词、字符或其他形式的文本片段。
就像我们说话时,一个句子是由很多单词组成的,同样,一个文本也是由很多 Token 组成的。
这些 Token 可以是单词,也可以是标点符号、数字等。
它既会被用作形容某些大模型一次能够受理的 Token 容量以彰显处理能力,也会被用作大模型收费的计价单元。
什么是Tokenizer
❝
Tokenizer 是将文本切分成多个 Tokens 的工具或算法,它负责将原始文本分割成 Tokens 序列。
不同的模型可能会采取不同的技术来进行分词。
因此,即便是同样的数据,不同的模型可能会产生最终不同的 Token 和数量。
最简单的理解,如果把模型理解成一个人,那么不同的人可能会对同样的句子有不同的断句。
常见的 AI 工具 Token 限制:
❝
目前所有的主流大语言模型在对话模式下能处理的 Token 数量都存在限制。
由于这个限制,所以建议大家在信息量大的情况下可以将输入信息转化为英文。
因为通常同样的信息量,使用英文转译占用的 Token 数量要明显少于中文。
每日一题
题目描述
❝
给你一个字符串
s,将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。
示例 1:
输入:s = "Hello"
输出:"hello"
示例 2:
输入:s = "here"
输出:"here"
解题思路
❝
用位运算的技巧:
- 大写变小写、小写变大写:字符 ^= 32
- 大写变小写、小写变小写:字符 |= 32
- 大写变大写、小写变大写:字符 &= 33
代码实现
Java代码:
class Solution {
public String toLowerCase(String str) {
if (str == null || str.length() == 0) {
return str;
}
char[] ch = str.toCharArray();
for (int i = 0; i < str.length(); i++) {
ch[i] |= 32;
}
return String.valueOf(ch);
}
}