 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}

大家好呀,我是飞鱼。
大模型的上下文长度是指:
❝
在使用大模型的时候,给大模型的输入加上输出的字符(Token)总数。
这个数字会被限制,如果超过这个长度的字符会被大模型丢弃。
目前主流大模型支持的上下文长度:
❝
Qwen2.5-Turbo:100万(1M)上下文长度。
GPT-4:4K 到 128K 上下文长度。
KimiChat:128K 到200万(2M)上下文长度。
Claude:200K(2M)上下文长度。
这些模型在上下文长度上的不同支持,使得它们在各种应用场景中表现出不同的优势。
❝
例如,KimiChat 和 Qwen2.5-Turbo 在处理超长文本方面具有明显的优势。
而 GPT-4 和 Claude 则在多轮对话和复杂任务中表现出色。
那怎样让AI大模型变得更加聪明,能够处理更长的上下文信息呢?
提升上下文长度的方法:
❝
稀疏注意力机制:
- 通过选择性地关注文本中的关键部分,而不是全局自注意力,显著减少了计算量。
分块处理与上下文缓存:
- 采用分块处理策略,将长文本分成多个小段进行处理,然后通过上下文缓存技术将各段的上下文信息有效融合。
- 减少了单次处理的数据量的同时通过缓存机制保持了上下文的连贯性。
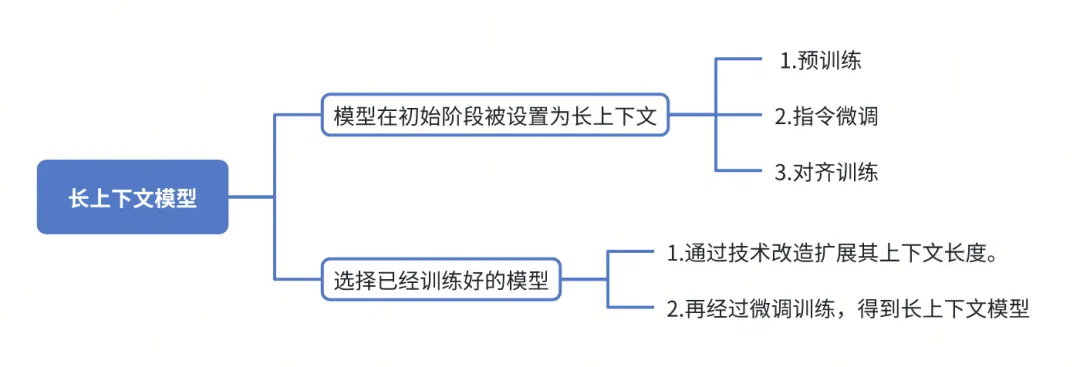
想要得到一个长上下文的大模型,一般有两种途径:
❝
1、大模型在初始阶段被设置为长上下文,然后经过预训练,指令微调,对齐训练等方式。
2、选择已经训练好的大模型,通过技术改造扩展其上下文长度,然后再进行微调训练。
当 LLM 支持的上下文越来越长,RAG 还有意义吗?
❝
长文本的优势在于:当处理复杂任务时,所能支持的上下文 Token 更多。
- 但劣势在于受注意力限制,可能导致输出结果的不准确。
RAG 的优势在于:支持更大量级的数据,并且可以针对性地抽取相关数据进行模型分析,节约 Token 成本。
就好比:LLM 是一部手机,长文本能力是手机内存大小,RAG 是一个应用或者一个外挂能力。
在实际应用的时候如何选择,取决于你对输出内容准确度的要求和处理问题所需要的上下文 Token 的长度。
有啥其他补充的内容,欢迎在评论区留言讨论。
❝
想看技术文章的,可以去我的个人网站:http://hardyfish.top/
- 目前网站的内容足够应付基础面试(
P6)了!
每日一题
题目描述
❝
给你两个二进制字符串
a和b,以二进制字符串的形式返回它们的和。
示例 1:
输入:a = "11", b = "1"
输出:"100"
示例 2:
输入:a = "1010", b = "1011"
输出:"10101"
解题思路
❝
整体思路是将两个字符串较短的用 0 补齐,使得两个字符串长度一致,然后从末尾进行遍历计算,得到最终结果。
代码实现
Java代码:
class Solution {
public String addBinary(String a, String b) {
StringBuilder ans = new StringBuilder();
int ca = 0;
for(int i = a.length() - 1, j = b.length() - 1;i >= 0 || j >= 0; i--, j--) {
int sum = ca;
sum += i >= 0 ? a.charAt(i) - '0' : 0;
sum += j >= 0 ? b.charAt(j) - '0' : 0;
ans.append(sum % 2);
ca = sum / 2;
}
ans.append(ca == 1 ? ca : "");
return ans.reverse().toString();
}
}