 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}

AI 的终极目标不是取代人类,而是让机器学会思考,人类学会协作。
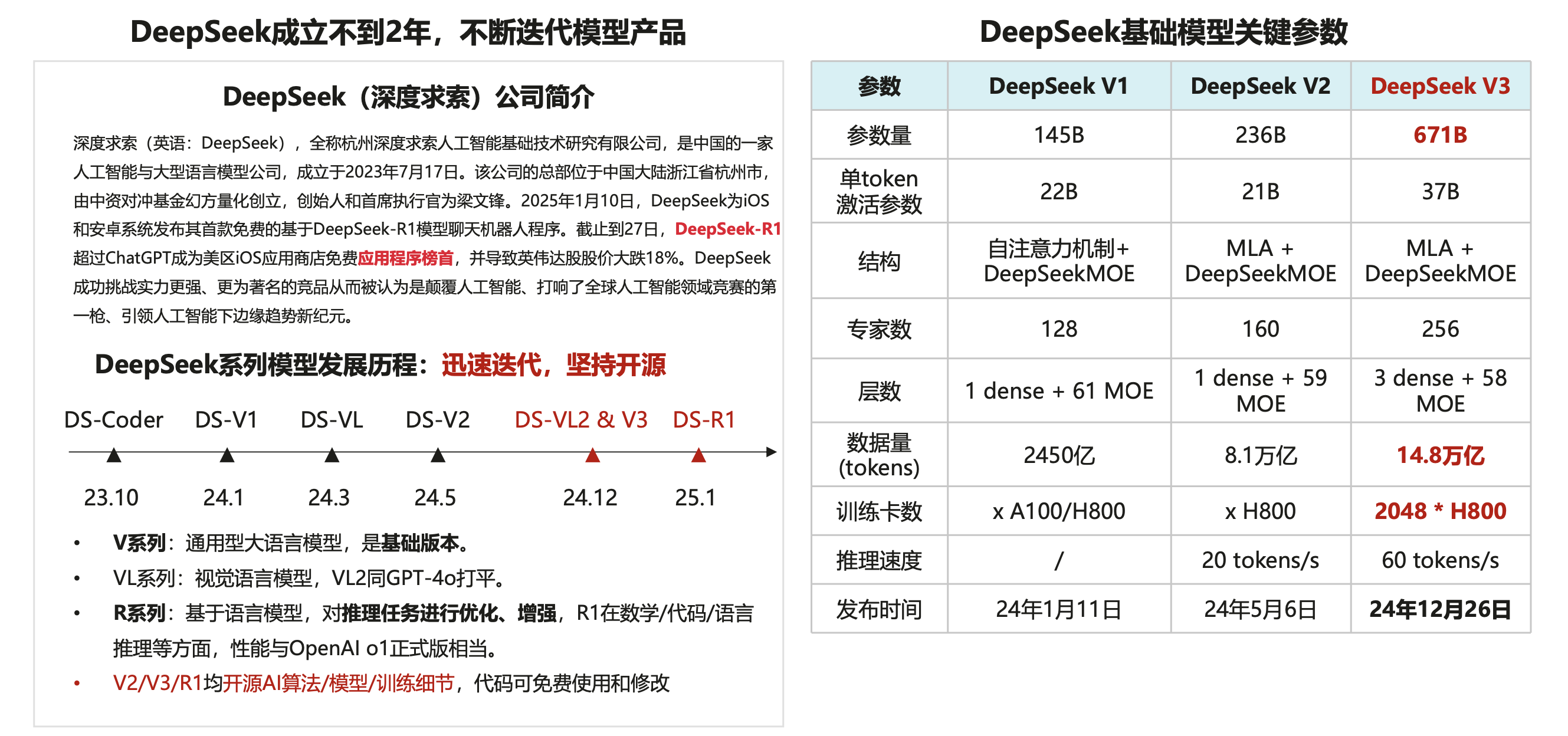
基本介绍
DeepSeek是幻方量化旗下的一家大模型企业,成立于2023年7月份,致力于探索人工智能本质。根据此前的信息,幻方量化有1万多张A100显卡,在美国显卡禁令之前用于量化投资。
主要产品线
最新版本包含两个主要产品线:
- DeepSeek V3:基础模型系列,提供通用 AI 能力。
- DeepSeek R1:专注于推理和编程能力。
DeepSeek 相关模型已经开源,以下是不同模型的开源地址:
DeepSeek Coder:代码大模型,仓库地址:https://github.com/DeepSeek-AI/DeepSeek-Coder
DeepSeek LLM:通用大语言模型,仓库地址:https://github.com/DeepSeek-AI/DeepSeek-LLM
DeepSeek-R1,仓库地址:https://github.com/deepseek-ai/DeepSeek-R1
DeepSeek-R1模型
DeepSeek-R1在多个高难度基准测试中表现与OpenAI O1-1217相当,但训练成本更低。与传统的
SFT+RL方法不同的是,他们发现即使不使用SFT,也可以通过大规模RL显著提高推理能力。此外,通过包含少量冷启动数据进行
SFT就可以进一步提高性能。
DeepSeek-R1-Zero:
- 不用
SFT直接进行RL,也能取得不错的效果。
DeepSeek-R1:
- 加入少量
CoT数据进行SFT作为冷启动,然后再进行RL,可以取得更优的性能,同时回答更符合人类偏好。用
DeepSeek-R1的样例去蒸馏小模型,能取得惊人的效果。
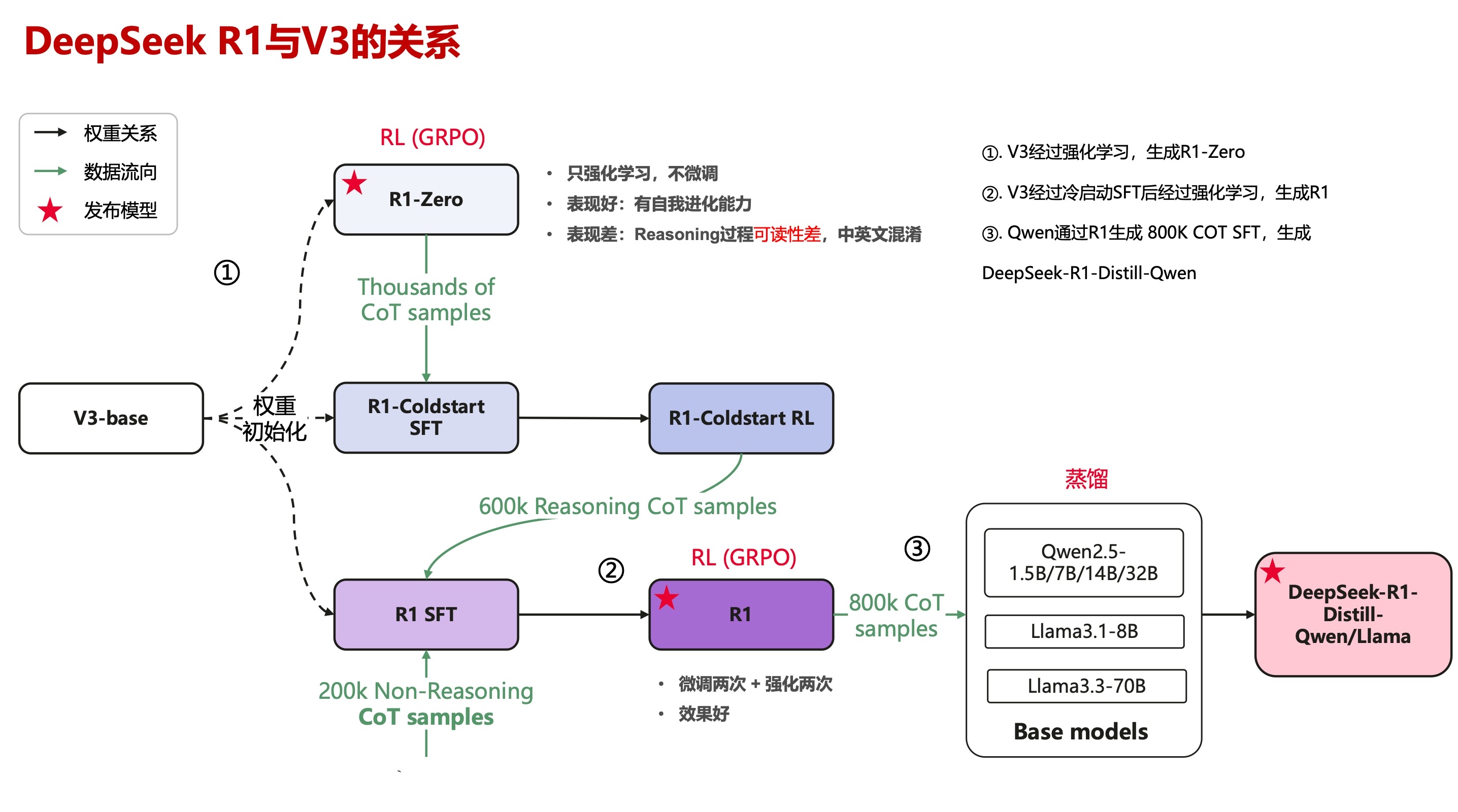
DeepSeek-R1与V3的关系:
DeepSeek-R1是基于DeepSeek-V3的进一步优化,通过强化学习和蒸馏技术提升其推理能力。
DeepSeek满血版与蒸馏版:
| 版本 | 参数规模 | 性能表现 | 适用场景 | 部署成本 | 响应速度 |
|---|---|---|---|---|---|
| 满血版 | 6710亿参数 | 复杂推理能力强,支持详细思考过程 | 科研、高级数据分析、自然语言生成 | 高 | 较慢 |
| 蒸馏版 | 1.5B~32B | 推理能力适中,无详细思考过程 | 小型企业、实时交互场景 | 中 | 快 |
| 量化版 | 压缩后的小模型 | 推理速度快,精度略有下降 | 移动端、边缘设备 | 低 | 很快 |
DeepSeek的满血版(像 671B 参数的完整版)拥有最强大的性能,但需要极其昂贵的硬件设备来运行。
- 如果自行部署,可能需要支付高昂的费用。
蒸馏版通过一种叫做知识蒸馏的特殊训练方法,训练出学生模型。
基本使用
网页版:
移动端:
- 可以直接在各大应用商店搜索
DeepSeek,或者在网页端直接扫码下载。服务状态监控:https://status.deepseek.com/
- 一般来说,当服务状态为红色时,会较频繁的出现:"服务器繁忙,请稍后再试"的提示。
官方提示词库:
官方提供了13个
DeepSeek提示词样例,可以作为参考:
联网搜索:
目前
DeepSeek的预训练数据更新到2024年7月。联网搜索使
DeepSeek不仅能依赖它自己的知识库,还能根据互联网实时搜索相关内容来回答问题。联网搜索模式基于
RAG(检索增强生成)。
学习资料
论文链接:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
清华大学104页《DeepSeek:从入门到精通》:
DeepSeek和ChatGPT对比
DeepSeek优势
成本优势:
- 训练成本低,如
DeepSeek基座模型完整训练一次仅需550万美元。- 调用接口成本也只有GPT相关接口的几十分之一,有人戏称它是大模型界的拼多多。
中文处理能力强:
- 对中文语法、成语、文化背景理解更深入。
- 在中文文本生成、摘要、情感分析等任务中表现自然,中文准确率可达92.5%。
核心特点与创新
高效的训练方法:打破传统局限
DeepSeek-R1的训练方式与传统的监督微调(SFT)不同,它采用强化学习(RL)进行训练。这种创新的训练方法不仅显著降低了模型的训练成本,还使得
DeepSeek-R1能够自主开发出更为高级的推理能力。通过强化学习,
DeepSeek-R1能够在多种复杂任务中展现出超强的推理能力,尤其在数学推理和编程方面的表现尤为突出。卓越的性能:与顶级模型媲美
DeepSeek-R1展现出了与OpenAI o1相当,甚至超越的推理能力。开源与低成本:AI技术的普及化
DeepSeek-R1采取了开源策略,且采用MIT许可证,允许全球开发者进行自由修改和优化。多阶段训练管道:更强的推理能力
DeepSeek-R1还采用了多阶段训练管道,结合冷启动数据、强化学习和监督数据。
- 这种训练策略提升了模型在处理复杂任务时的表现。
特别是在需要深度推理的场景中,
DeepSeek-R1能够提供更加精确和高效的解决方案。
LLM推理新策略:
通过强化学习(
RL)提升大型语言模型(LLM)的推理能力。仅依靠强化学习而不是过分依赖监督式微调的情况下,增强
LLM解决复杂问题的能力。
DeepSeek 相对于 GPT 等主流大模型的区别:
GPT等主流大模型是指令型大模型。这类大模型需要我们给它说下比较详细的流程,它的回答才会让我们满意。
去年在
ChatGPT这类指令型大模型很火的时候,出现了很多提示词模板,甚至诞生了提示词工程师这一岗位。而
DeepSeek R1属于推理型大模型。这类模型不需要我们列出太详细的流程,太详细的流程反而会降低它们的性能,限制它们的发挥。
DeepSeek R1在发表的论文中也提到:DeepSeek R1对提示词很敏感,为获得最佳效果,建议用户直接描述问题。指令型大模型和推理型大模型,这就像两个员工:
- 一个是需要你事无巨细地安排工作任务、每个步骤都不能落下(指令型AI)。
- 一个很机灵,只要你说明要求、目的,他就能自己思考怎么做(推理型AI)。
基础技巧
提问加上背景描述:
需要向
DeepSeek R1说清楚:
- 我是谁(如我一个互联网打工人)。
- 我当前的水平(如我是自媒体小白)。
- 我想让
DeepSeek充当的角色(如你是一名自媒体运营专家)等。有时
DeepSeek回答的内容可能不是你想要的,这时可以增加约束条件,来限制、优化它回答的内容。即:背景+需求+约束条件。
如:我家小孩读初一(交待背景),怎样提高他的英语水平(提出需求),不需要考虑口语问题 (约束条件)。
学会说人话:
问到一些专业领域的问题时,
DeepSeek的回答会掺杂很多专业名词来解释问题。只需要在提示词中加上说人话、大白话、通俗易懂等。
告别提示词:
DeepSeek可以完全不用准备提示词,只要简单明了地描述你的需求,DeepSeek就能理解并给出精准的答案。与
DeepSeek的对话,尽量使用简单、直白的语言,越是接地气的表达,DeepSeek就越能发挥其最大潜力。
DeepSeek的理解能力非常强,不需要过多的引导,给它一个清晰的问题,它就能提供精准的答复。
小学生沟通方式:
与
DeepSeek对话时,有时可能觉得AI的回答过于抽象。源于传统AI模型过于注重结构化表达。
DeepSeek可以给它一个提示:比如:我是一名小学生,请用小学生能听懂的话解释什么是大模型。
活用上传附件:
DeepSeek的推理模型,不仅能联网,还支持上传附件。
推理+上传附件,可以做更多本地化、私密化的东西。
比如你自己的知识库或者内部资料,让其基于自有知识库进行推理和思考。
可以通过开启 联网搜索 实时搜索内容,上传附件来精准分析。
对于不能搜索的地址,先手动下载资料后,再上传给
DeepSeek R1帮助分析。
对标模仿能力:
可以让
DeepSeek模仿名人风格,因为它对中文的掌握能力极强,能模仿名人的写作风格。
结合V3和R1:
先跟V3多轮对话,得到要推理的细节和提示词,然后发给R1,让R1再来推理、输出。
这样,就能将
DeepSeek的能力又提升一个等级。
深度思考:
DeepSeek虽然对标GPT-o1,但是GPT-o1线性罗列,像个高级文档工具。
DeepSeek深度思考,像个思考伙伴。可以通过三个核心提示词,继续激发它的深度思考能力。
请在你的思考分析过程中同时进行批判性思考至少10轮,务必详尽
请在你的思考分析过程中同时从反面考虑你的回答至少10轮,务必详尽
请在你的思考分析过程中同时对你的回答进行复盘至少10轮,务必详尽
持续追问:
运用持续追问的技巧,能够帮你快速搞清楚一个复杂问题,大致步骤如下:
提出一个概括性的问题。
基于回答内容进行深入追问。
继续挖掘具体细节。
让
DeepSeek把对话整理成详细的清单格式。
不适合做什么
长文本内容:
- 现在
DeepSeek模型上下文长度最长为 6 万 4 千个Token。- 最大输出长度为 8 千个
Token,默认输出长度为 4 千个Token。
多模态模型
Janus Pro是DeepSeek开发的一个开源多模态人工智能框架。它通过集成视觉和语言处理能力,提供了高性能的多模态任务处理能力。
在线体验: https://deepseek-januspro.com/
Janus-Pro-7B 多模态 AI 模型,它在理解和生成方面取得了显著的进步。
这意味着它不仅可以处理文本,还可以处理图像等其他模态的信息。
官方卡顿解决方案
解决在使用
Deepseek的过程中,遇到 服务器繁忙 提示的问题。
硅基流动:
注册硅基流动:https://cloud.siliconflow.cn/i/RLCR0CvJ
- 新建API密钥:选择左边的导航栏,找到API密钥,点进去,再点右上角的新建API密钥。
结合Chatbox AI保存上下文
Chatbox AI一款功能强大的 AI 客户端应用和智能助手。
现在很多搜索工具内部已经集成了 DeepSeek R1 的深度思考模式,可直接使用,如:
国家超算互联网:
https://chat.scnet.cn/#/home秘塔 AI 搜索:
https://metaso.cn/纳米 AI 搜索:
https://www.n.cn/阿里云百炼大模型服务平台:https://bailian.console.aliyun.com/
幻觉问题
AI应用最害怕的就是模型幻觉,同一个问题收到不同的回答是令人绝望的事情。
据
Vectara HHEM人工智能幻觉测试,DeepSeek-R1显示出14.3%的幻觉率。尽管
DeepSeek-R1在推理方面表现卓越,但它的 幻觉率比其前身DeepSeek-V3更高。这意味着
DeepSeek-R1在生成内容时产生的错误信息或与输入不一致的内容比DeepSeek-V3要多得多。
为什么R1幻觉这么厉害?
模型越自由,可能幻觉越多。
由于
DeepSeek是推理型模型。当模型通过长思维链进行推理时,它可能会从不同的角度考虑问题,而这些角度并不总是与现实一致,这就导致了幻觉的发生。
DeepSeek如何思考
如果用一个比喻来描述
DeepSeek,它大概就像是你的一位非常博学多才的朋友。不仅读过浩如烟海的书籍,更神奇的是,他能瞬间在脑海中建立起各种知识之间的联系。
这就是现代大语言模型的工作方式,而支撑这种能力的核心,是 2017 年
Transformer架构。Transformer
Transformer最厉害的本事,就是它的注意力机制。当你在看一本书时,普通人需要从头读到尾,而
Transformer就像是一个超级读者。
- 能够一眼就找到文本中最关键的信息,并迅速理解它们之间的关联。
DeepSeek的思考方式也有其独特之处,它就像是一位即兴演讲大师。
- 每说出一个词都经过精密计算,既要保证内容连贯,又要富有创意。
蒸馏模型
DeepSeek-R1在通过拒绝采样和SFT时的数据对小模型进行SFT未经过RL阶段,已经能够取得较好的效果。通过小模型进行
SFT+RL训练相比,蒸馏较好性能模型的输出去做SFT会有更好效果,且成本也会低很多。要实现效果好的小模型,要具备把模型做大的能力。
训练出一个效果好的大参数模型,然后再对其蒸馏,效果要远优于直接训小模型。
本地部署
安装Ollama:
下载地址:https://ollama.com/download。
访问:https://ollama.com/search,选择要安装的模型。
点击选择
Deepseek-R1,进入模型参数界面:
- 这里的数字越大,参数越多,性能越强,所需要的配置也就越高,1.5b代表模型具备15亿参数。
- 若要运行14b参数模型,需要大约11.5G显存,也就是你的电脑显卡最好要达到16G。
安装模型:
以
1.5b参数为例,选择1.5b参数后,执行命令:ollama run deepseek-r1:1.5b。详细地址:
https://ollama.com/library/deepseek-r1:1.5b下载成功后,就可以与模型对话啦。
此时大模型安装在你的电脑上,就算断网也可以继续用,也不用担心数据泄露。
使用模型:
当你关闭电脑后,下次若再想使用本地模型时,只需要启动了
ollama,同时打开命令行界面,输入
ollama run deepseek-r1:1.5b即可。因为你之前已经下载过,这次无需下载,可以直接和模型聊天。
本地模型搭建UI界面:
使用
ChatBox AI,访问:https://chatboxai.app/zh。下载后,选择使用自己的
API Key或者本地模型。
- 比如选择本地跑的
deepseek-r1:1.5b模型。
Ollama默认使用 端口11434 提供本地服务。当在本地运行
Ollama时,可以通过这个访问其 API 服务:http://localhost:11434。
应用场景
DeepSeek之所以受到业内的追捧,主要在于其创新的算法和高性价比。总之:大模型成本降低,对整个行业的影响很大。
基础电信运营商
中国电信
视频会议系统接入
DeepSeek后,可以把会议内容。包括参会人员的语音发言、演示的PPT内容同步形成会议纪要并归纳总结成条理清晰的摘要。
中国移动
通过中国移动云平台的算网大脑,自动化部署在中国移动云平台的算力基础上。
把中国移动云平台的建设运营和运维的成本降低,最终实际上给用户带来的好处是它服务成本会下降。
中国联通
将充分利用自身强大的网络基础设施和海量用户数据,深度挖掘
DeepSeek大模型的潜力。为用户提供更丰富的智能应用场景,推动整个通信产业的智能化升级。
芯片、智算中心转型升级
DeepSeek大幅降低了大模型训练成本,大模型训练不再需要那么多的高端芯片和数据中心。长期来看,AI应用的普及,会推动智算中心向高效+绿色方向升级。
应用实战
本地知识库
搭建本地知识库
DeepSeek-R1本地部署配置要求:https://github.com/deepseek-ai/DeepSeek-R1?tab=readme-ov-file
| 模型规模 | 最低 GPU 显存 | 推荐 GPU 型号 | 纯 CPU 内存需求 | 适用场景 |
|---|---|---|---|---|
| 1.5B | 4GB | RTX 3050 | 8GB | 个人学习 |
| 7B、8B | 16GB | RTX 4090 | 32GB | 小型项目 |
| 14B | 24GB | A5000 x2 | 64GB | 专业应用 |
| 32B | 48GB | A100 40GB x2 | 128GB | 企业级服务 |
| 70B | 80GB | A100 80GB x4 | 256GB | 高性能计算 |
| 671B | 640GB+ | H100 集群 | 不可行 | 超算/云计算 |
安装
Ollama:参考前文:本地部署。
安装 AnythingLLM
官方网址:https://anythingllm.com/desktop
创建知识库
点击工作区旁边的上传按钮,可以将文件上传到工作区中。
使用配置好知识库的
Deepseek R1模型:
- 这里需要在聊天设置中配置相关的聊天提示,模型才能够更好的理解你的任务。
基础原理
DeepSeek发布的V3、R1-Zero、R1三大模型,代表了一条从通用基座到专用推理的完整技术路径。
V3 是起点:作为通用基座模型,提供基础语言能力。
R1-Zero 是过渡实验体:通过纯
RL训练验证推理能力,但语言混乱不可用。R1 是终极形态:融合冷启动、
RL锻造、数据反哺、人类偏好四阶段,兼顾能力与实用性。
技术差异:
| 维度 | DeepSeek-V3 | R1-Zero | DeepSeek-R1 |
|---|---|---|---|
| 定位 | 通用基座模型 | 纯 RL 训练的推理实验模型 | 多阶段优化的商用推理模型 |
| 训练方法 | 预训练 + SFT | 纯强化学习(GRPO 算法) | SFT → RL → SFT → RL与SFT混合训练 |
| 数据依赖 | 通用语料 + 标注数据 | 数学/代码数据(无需标注) | RL 生成数据 + 人类偏好数据 |
| 推理能力 | 基础问答 | 强推理但语言混杂 | 强推理 + 语言规范 |
| 可用性 | 通用场景 | 实验性(不可直接商用) | 全场景适配(客服、编程等) |
| 开源状态 | 开源 | 未开源 | 开源 |
DeepSeek-R1训练过程
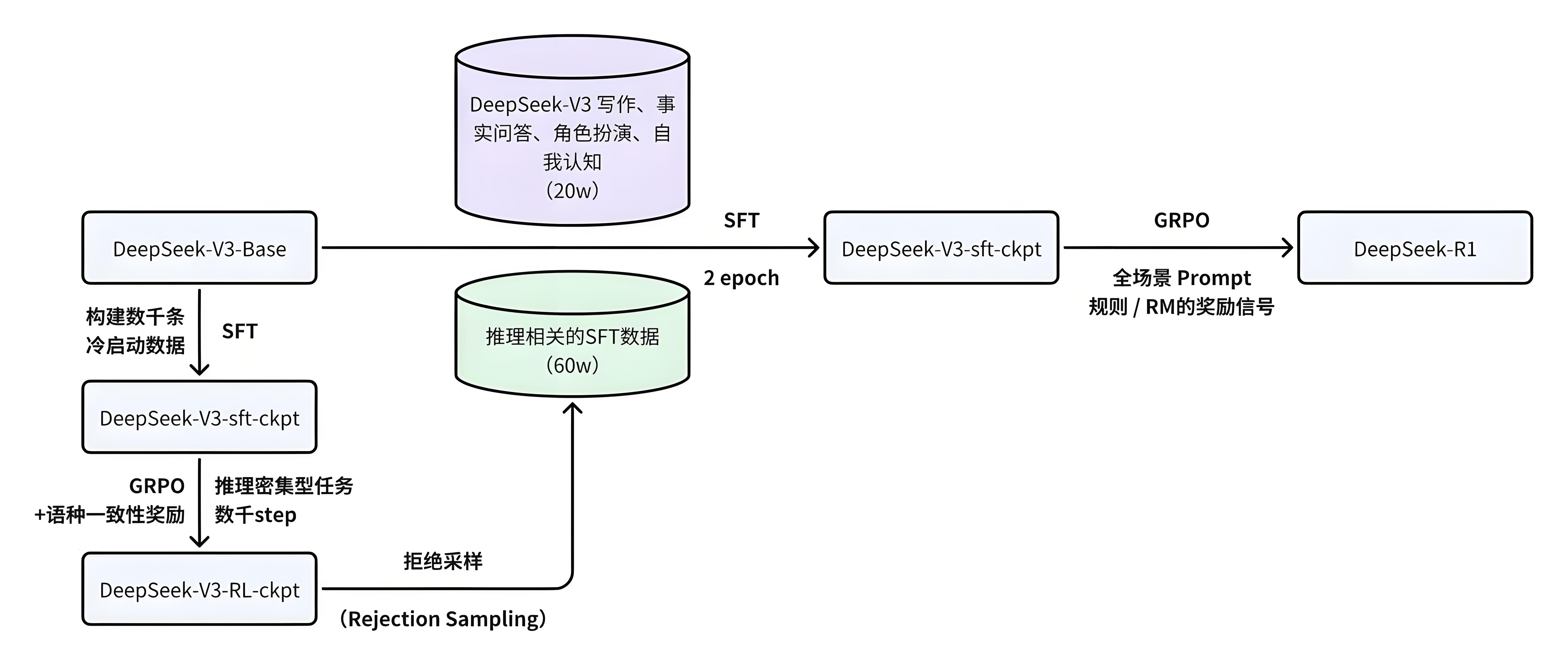
冷启动(抄作业)阶段:
这个阶段,
DeepSeek-R1还只是个新手。通过抄作业,学习少量高质量的
CoT(思维链)数据。这些数据告诉
DeepSeek-R1什么是正确的推理过程。这个阶段的核心矛盾是:如何在最小化人工干预的前提下,建立可扩展的推理范式。
DeepSeek的方案像给模型安装脚手架,既约束探索方向,又不限制创新空间。
RORL(实战演练)阶段:
RORL(推理导向的强化学习)。这个阶段,
DeepSeek-R1不再只是抄作业,而是要自己解题。它会尝试各种推理路径,并通过
GRPO(Group Relative Policy Optimization)算法来评估自己的表现。
GRPO就像一位裁判,根据DeepSeek-R1的答题情况打分,并指导它如何改进。这个阶段,
DeepSeek-R1主要依靠规则奖励(Rule-based Reward)来修炼。
重构(自创武功)阶段:
经过实战演练,
DeepSeek-R1已经具备了一定的推理能力。接下来,它开始自创武功,生成高质量的训练数据。
这个阶段,
DeepSeek-R1会利用拒绝采样(Rejection Sampling)和CoT提示(CoT Prompting)来生成数据。拒绝采样就像筛选器,确保生成的数据符合要求。
CoT提示则像模板,帮助DeepSeek-R1生成各种类型的SFT数据。
最终进化(融会贯通)阶段:
这个阶段,
DeepSeek-R1将之前学到的所有招式融会贯通。它会再次进行
SFT微调,并引入人类偏好奖励(Human Preference Reward),让自己的推理能力更上一层楼。
DeepSeek R1训练流程,大大简化了强化学习的训练复杂度,使强化学习在模型效果提升上更加平民化。
突破创新带来大模型新范式
DeepSeek-R1通过从模型结构到训推全流程的极致工程优化,带来大模型新范式。
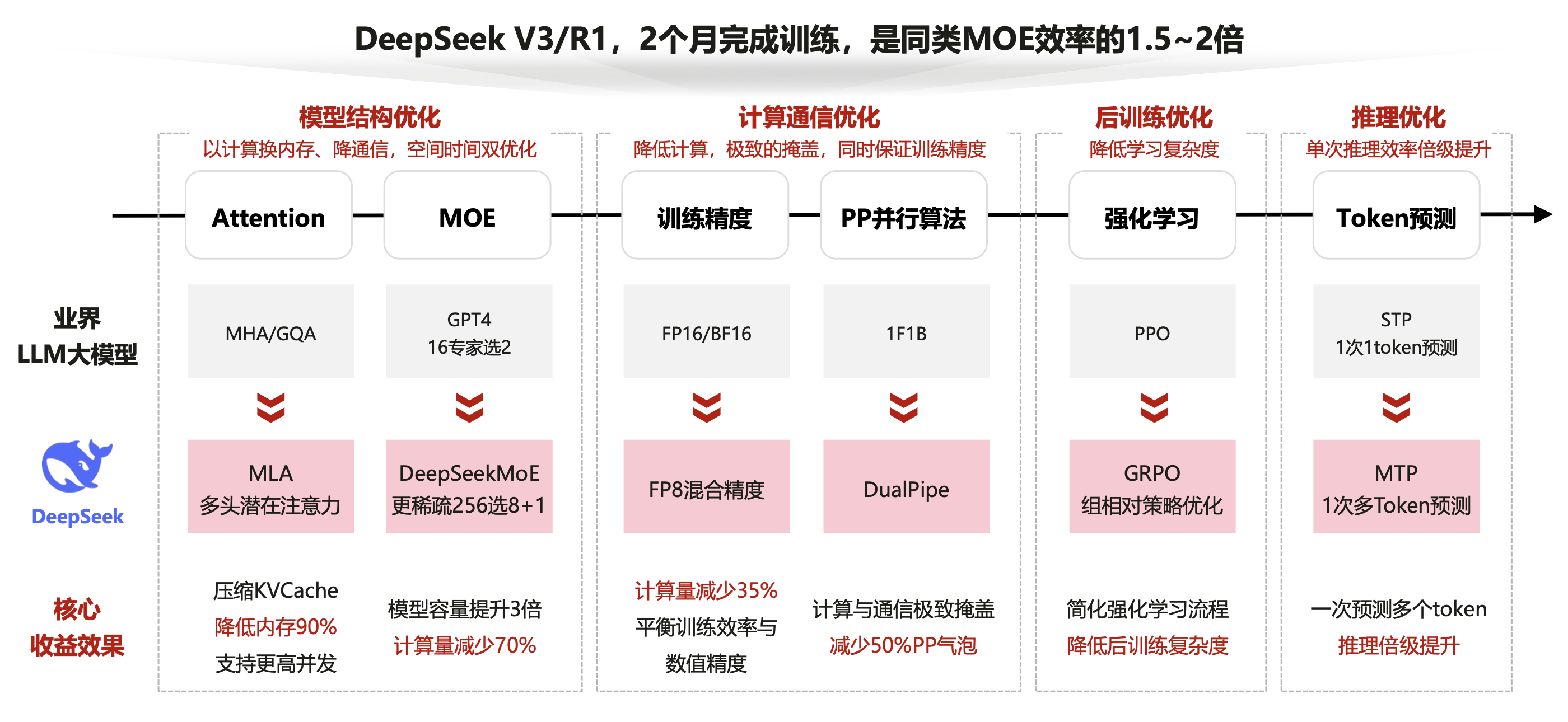
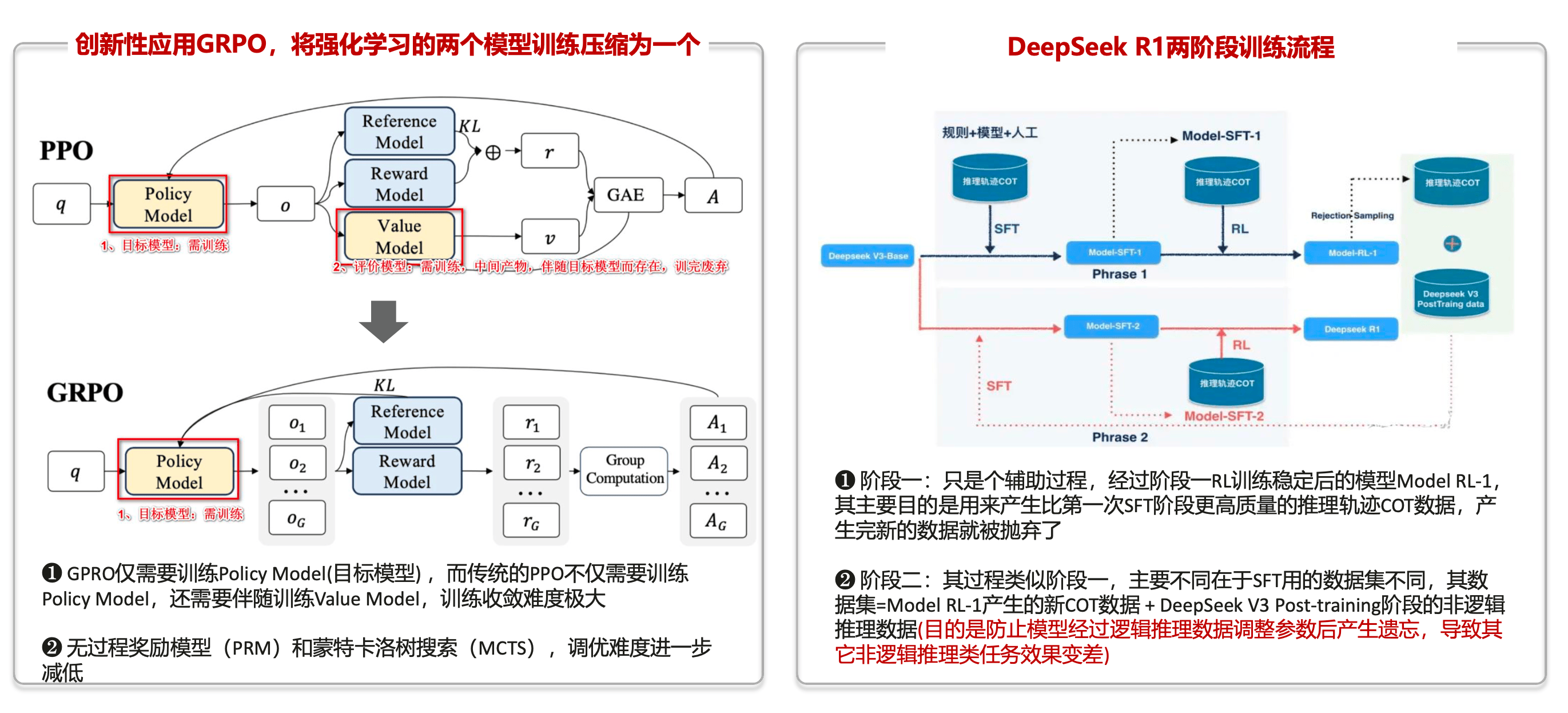
创新性应用GRPO
创新性应用
GRPO,将强化学习流程的两个模型训练简化为一个模型的训练。
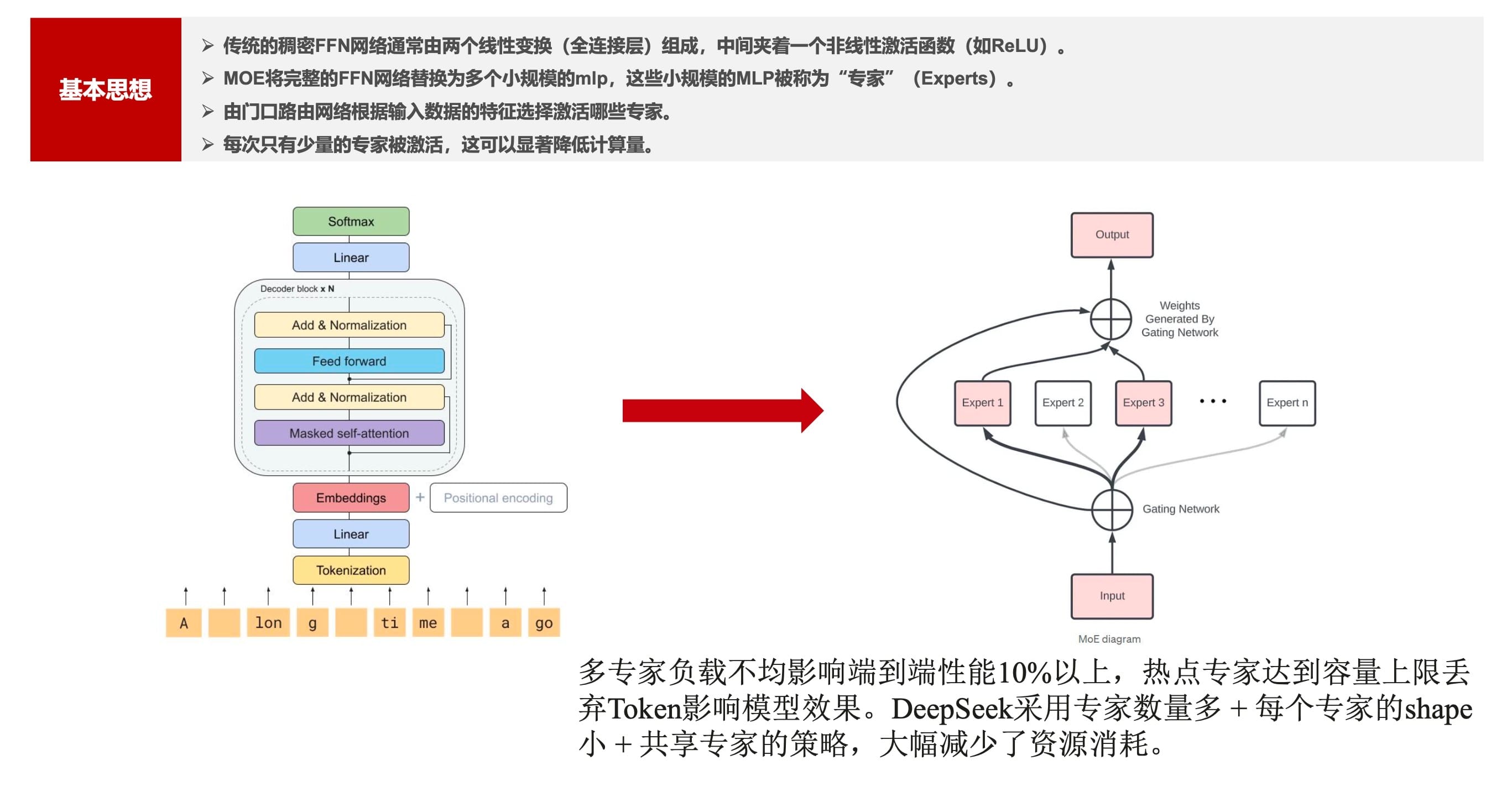
MOE结构创新
多专家负载不均影响端到端性能10%以上,热点专家达到容量上限丢 弃
Token影响模型效果。
DeepSeek采用专家数量多 + 每个专家的Shape小+共享专家的策略,大幅减少了资源消耗。
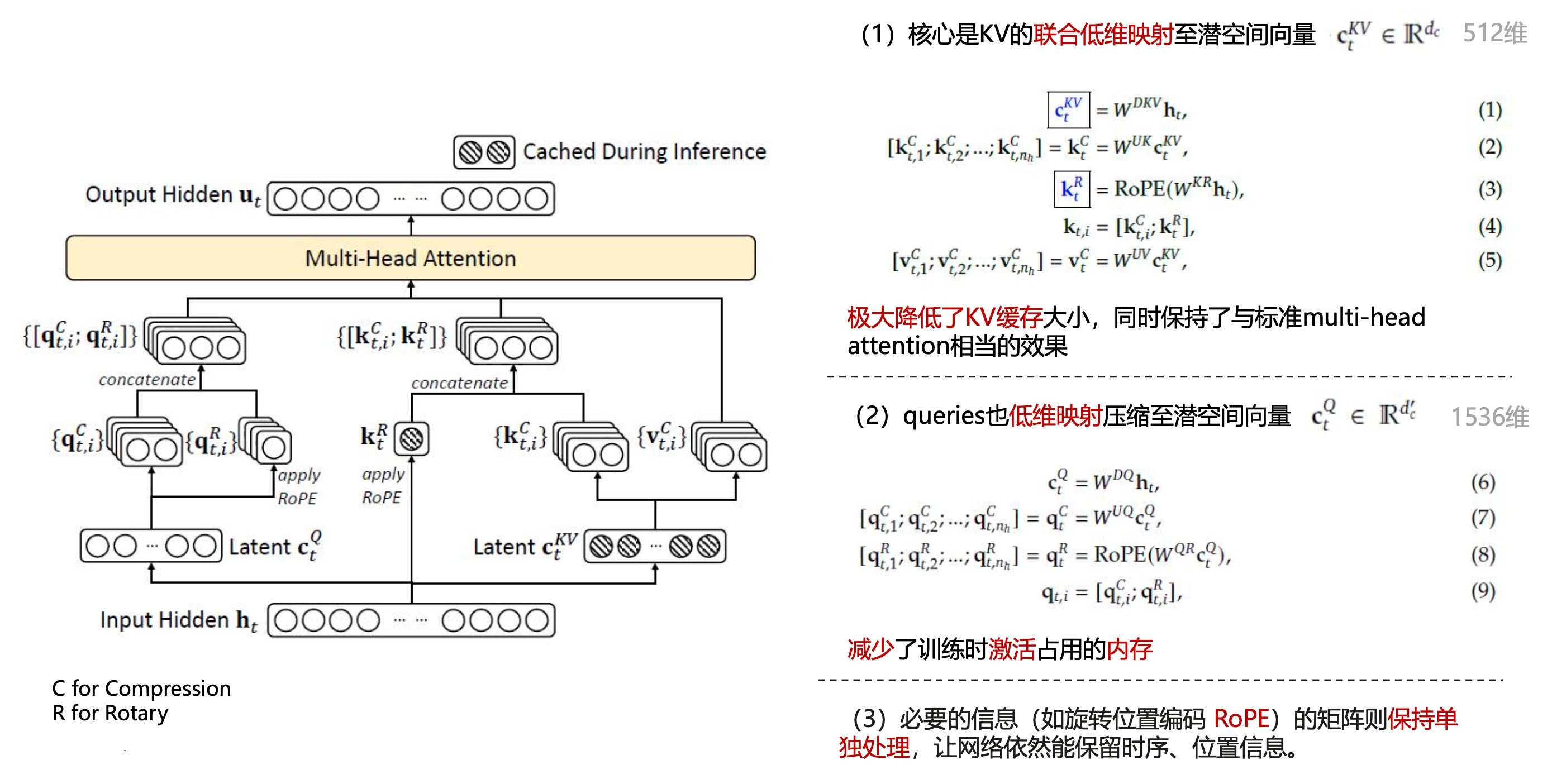
MLA(KV压缩)
在
DeepSeek模型中,多头潜在注意力(Multi-Head Latent Attention,MLA) 是一种关键技术。
- 旨在通过低秩压缩方法优化注意力机制的计算效率和内存使用。
MLA通过对键(Key)和值(Value)进行低秩联合压缩。显著减少了推理过程中的键值缓存(
KV Cache),在保持模型性能的同时降低了内存占用。
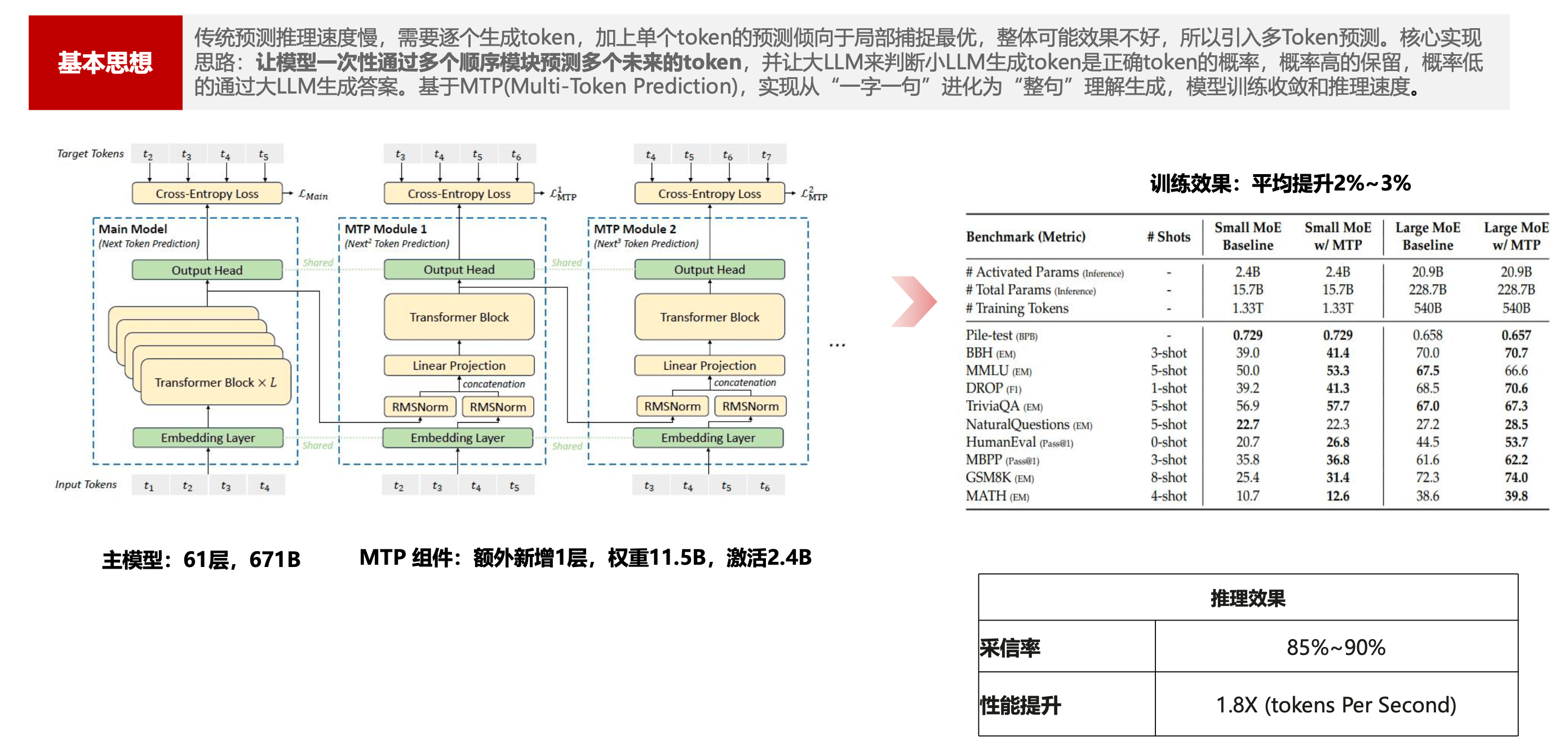
MTP(多Token预测)优化
传统预测推理速度慢,需要逐个生成
Token,加上单个Token的预测倾向于局部捕捉最优。
- 整体可能效果不好,所以引入多
Token预测。核心思路:
让模型一次性通过多个顺序模块预测多个未来的
Token,并让大LLM来判断小LLM生成Token是正确Token的概率。
- 概率高的保留,概率低的通过大LLM生成答案。
基于MTP,实现从一字一句进化为整句理解生成,模型训练收敛和推理速度。
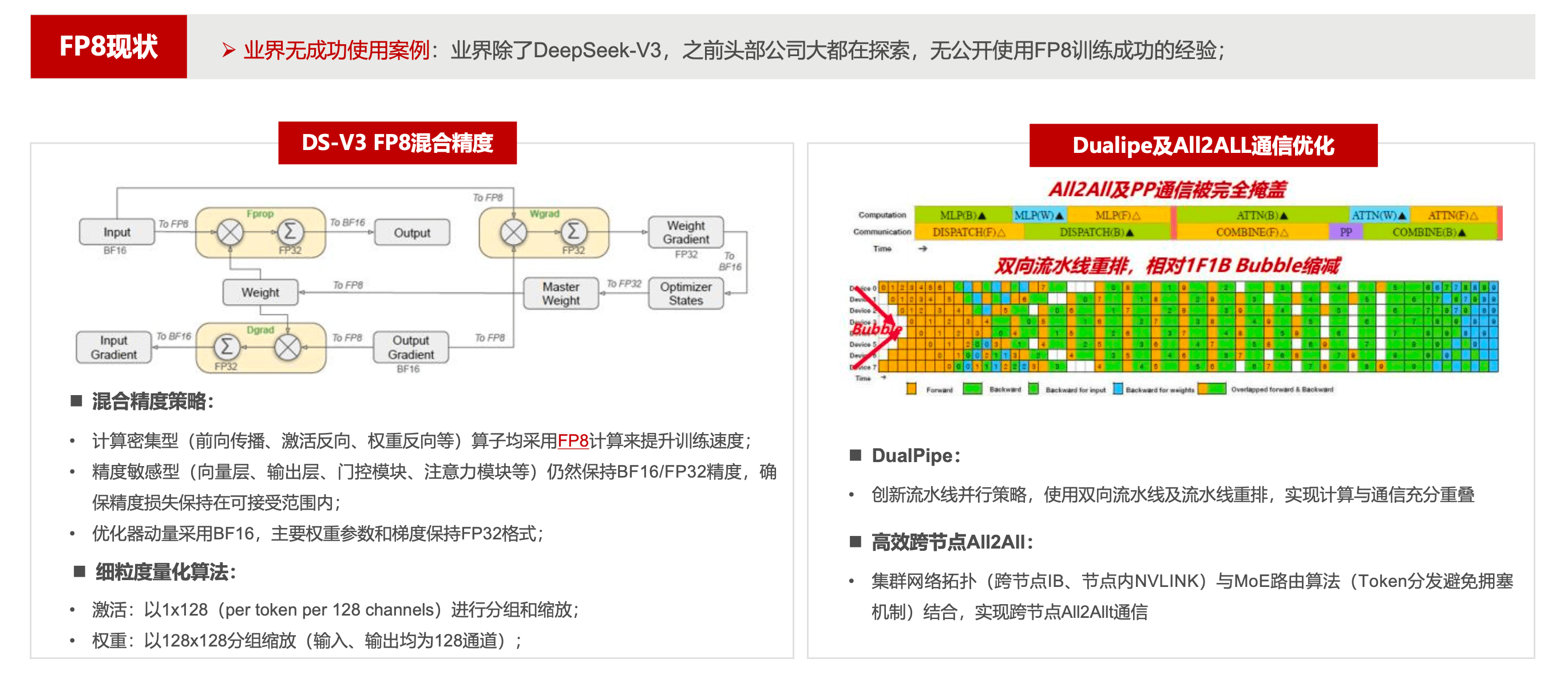
使用FP8混合精度
大规模训练上首次使用FP8混合精度,结合
Dualpipe通信优化。
知识蒸馏技术
DeepSeek在模型优化中创造性应用了渐进式分层蒸馏技术(Progressive Hierarchical Distillation)。通过将175B教师模型蒸馏到13B学生模型,在保持90%性能水平的同时,推理成本降低至1/8。
这种大模型智慧,小模型效率的解决方案,已在移动端智能助手场景实现规模化应用。
| 蒸馏阶段 | 知识迁移方式 | 效果提升 |
|---|---|---|
| 结构蒸馏 | 注意力模式迁移 | 保留95%架构特性 |
| 特征蒸馏 | 隐层表征对齐 | 推理速度提升2.3倍 |
| 逻辑蒸馏 | 决策路径优化 | 任务准确率+12.7% |