 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}

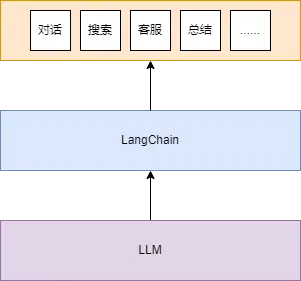
LangChain是一套面向大模型的开发框架。他主要拥有 2 个能力:
可以将
LLM模型与外部数据源进行连接。允许与
LLM模型进行交互。
LangChain Libraries是一个整合了各种Prompt的工具包。使用这个工具包,开发者能更专注于业务逻辑和业务实现。
快速入门:https://www.alang.ai/langchain/101/
参考教程:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng
发展版本:https://github.com/langchain-ai/langchain/releases
官方文档:https://python.langchain.com/v0.2/docs/how_to/
LangChain应用场景
使用
LangChain可以让大模型基于本地知识库进行问答,适用场景:智能客服。分析结构化数据,适用场景:数据分析、数据洞察等等。
LangChain安装
安装LangChain:
pip install langchain
快速开始
LangChain可以通过 API 提供的模型(如OpenAI)和本地开源模型(如Ollama)等集成。使用
OpenAI提供的API做示例。首先需要导入
LangChain x OpenAI集成包。
pip install langchain-openai
初始化模型:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
开始使用:
llm.invoke("介绍一下李白?")
输出如下:
AIMessage(content='李白(701年-762年),字太白,号青莲居士,唐朝时期伟大的浪漫主义诗人,被后人誉为“诗仙”。他出生于今天的陕西省凤翔县,自幼聪明好学,擅长诗词歌赋,一生创作了大量的诗歌,其作品风格豪放奔放,语言优美,富有想象力,具有极高的艺术价值。李白的诗歌题材广泛,包括山水田园、历史人物、神话传说、饮酒抒怀等,他的诗歌充满了浪漫主义色彩,表现出对自由、理想和自然的热爱。他的代表作有《静夜思》、《将进酒》、《庐山谣》、《早发白帝城》等,这些作品在中国文学史上占有重要地位。李白的一生充满了传奇色彩,他曾游历过许多地方,与当时的文人墨客交往甚广,他的诗歌也深受人们的喜爱。然而,他的生活并不平稳,曾多次遭遇政治挫折,但他始终保持乐观豁达的态度。晚年,李白因病返回故乡,最终在安徽当涂去世。李白的诗歌对中国文学产生了深远影响,他的作品被后世广为传颂,成为中国古代诗歌的瑰宝。 ')
使用提示模板来指导它的响应。
提示模板用于将原始用户输入转换为更好的
LLM输入。
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是世界级的历史人物研究人员,擅长用一句话输出回答。"),
("user", "{input}")
])
将它们组合成一个简单的 LLM 链:
chain = prompt | llm
调用它并提出相同的问题,理论上它应该输出一句介绍李白的话。
chain.invoke({"input": "请介绍一下李白?"})
输出如下:
AIMessage(content='李白,唐朝浪漫主义诗人,被誉为“诗仙”。 ')
模型的输出是一条消息,添加一个简单的输出解析器,将聊天消息转换为字符串。
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
将其添加到上一个链中:
chain = prompt | llm | output_parser
调用它并提出相同的问题,答案现在将是一个字符串(而不是
AIMessage)。
李白,唐朝浪漫主义诗人,被誉为“诗仙”。
核心组件
模型I/O封装:包括模型封装和模型的输入/输出封装:
LLMS:大语言模型(生成式语言模型)。
Chat Models:一般基于 LLMS,但按对话结构重新封装(对话式语言模型)。
PromptTemple:提示词模板。
OutputParser:解析输出(文本、代码)。
数据连接封装:
调用大模型的时候经常需要和第三方数据交互,包括文档的加载、处理、检索、存储。
记忆封装:文本上文、历史记录的管理:
Memory这里不是物理内存,从文本的角度,可以理解为上文、历史记录或者说记忆力的管理。
架构封装:
Chain:实现一个功能或者一系列顺序功能组合。
Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的Chain/Tool,最终完成用户指定的功能。
可以理解为Agent可以根据动态的帮我们选择和调用Chain或者已有的工具。
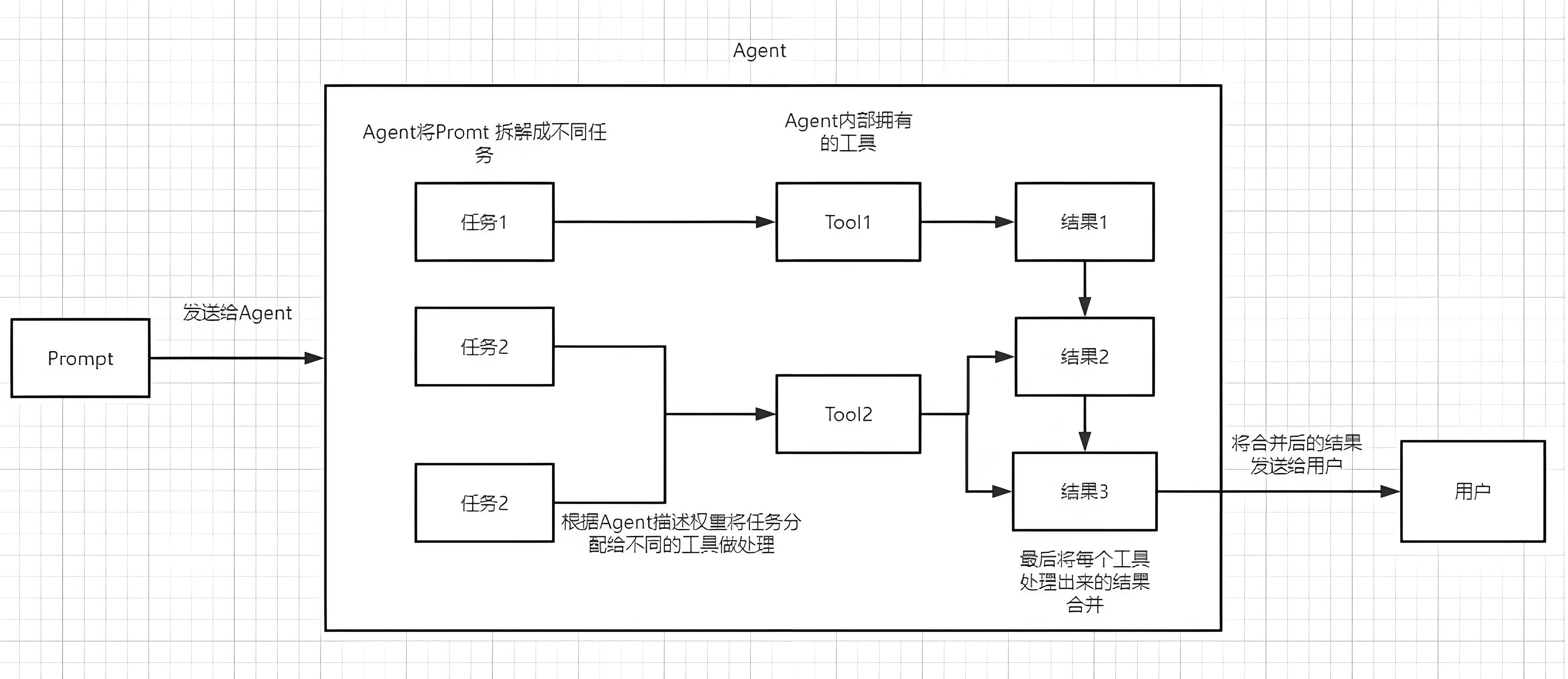
Retrieval Chain
怎么让LLM正确回答它没学习过的相关知识的问题?
需要为
LLM提供额外的上下文,可以通过检索来做到这一点。当有太多数据无法直接传递给
LLM时,检索非常有用,然后可以使用检索器仅获取最相关的部分并将其传递。在此过程中,将从
Retriever中查找相关文档,然后将它们传递到提示符中。
Retriever可以由任何东西支持:
- SQL 表、互联网、文档等,但在这种情况下,将填充一个向量存储并将其用作检索器。
创建用于将文档列表传递给模型的链:
设置一个链,该链接受一个问题和检索到的文档并生成一个答案。
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""仅根据提供的上下文回答以下问题:
<上下文>
{context}
</上下文>
问题: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
传入文档信息:
传入文档信息可以选择手动传入,也可以选择从指定文档(网页、PDF、文档等等)加载。
手动传入文档信息:
from langchain_core.documents import Document
document_chain.invoke({
"input": "数据空间研究院是谁出资建立的?",
"context": [Document(page_content="合肥综合性国家科学中心数据空间研究院是由安徽省人民政府发起成立的事业单位,是新一代信息技术数据空间领域的大型新型研发机构,致力于引领网络空间安全和数据要素创新技术前沿和创新方向,凝聚一批海内外领军科学家团队,汇聚相关行业大数据,开展数据空间基础理论、体系架构、关键技术研究以及相关能力建设,打造大数据发展新高地,推进“数字江淮”建设,为数字中国建设贡献“安徽智慧”“合肥智慧”。")]
})
Conversation Retrieval Chain
如何将这条链转化为一条可以回答后续问题的链?
可以继续使用
create_retrieval_chain函数,但需要更改两件事:
- 检索方法现在不应该只针对最近的输入,而是应该考虑整个历史。
- 最后的
LLM链同样应考虑整个历史。
整个的流程大概是:
检索文档找到关联的文档(一条或者多条),基于文档和历史对话进行问答,得到问题的答案。
如果如果还要继续进行问答,往
chat_history中添加新的问答对即可。
为了更新检索,将创建一个新的链:
该链将接收最近的输入(
input)和会话历史(chat_history),并使用LLM生成搜索查询。
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up in order to get information relevant to the conversation")
])
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
有了这个新的检索器,可以创建一个新的链来继续对话,并牢记这些检索到的文档。
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever_chain, document_chain)
测试一下效果:
chat_history = [
HumanMessage(content="《让子弹飞》什么时候在大陆上映的?"),
AIMessage(content="《让子弹飞》的大陆上映时间是2010年12月16日。")
]
retrieval_chain.invoke({
"chat_history": chat_history,
"input": "那韩国上映时间呢?"
})
Agent
Agent(代理)是目前比较火热的智能体的基础。
构建代理时要做的第一件事是确定它应该有权访问哪些工具。
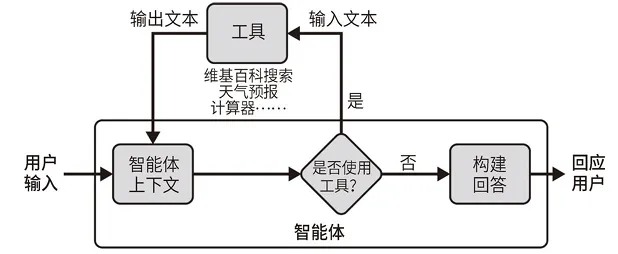
智能体安排的步骤如下所述:
智能体收到来⾃⽤户的输⼊。
智能体决定要使⽤的⼯具(如果有的话)和要输⼊的⽂本。
使⽤该输⼊⽂本调⽤相应的⼯具,并从⼯具中接收输出⽂本。
将输出⽂本输⼊到智能体的上下⽂中。
重复执⾏步骤 2 〜步骤 4 ,直到智能体决定不再需要使⽤⼯具,此时, 它将直接回应⽤户。
举例:将授予代理对两个工具的访问权限:
基于百度文库的《让子弹飞》电影信息。
LangChain内置的Agent——llm-math,用于复杂的数学计算。
问《让子弹飞》的相关问题,LangChain使用第一个Agent回答问题。
问数学计算,LangChain使用第二个Agent回答问题。
创建一个代理:
from langchain import hub
from langchain.agents import create_react_agent
from langchain.agents import AgentExecutor
# 这里获取一个内置prompt,为了方便
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
调用代理:
如果你的
LangChain将verbose设置称True,会完整输出执行的中间过程。会有一个明显的
COT过程。
agent_executor.invoke({"input": "让子弹飞的导演是谁"})
问一个数学计算问题:
agent_executor.invoke({"input": "8 的立方根是多少?乘以 13.27,然后减去 5。"})
跟Agent进行对话:
from langchain_core.messages import HumanMessage, AIMessage
chat_history = [
HumanMessage(content="让子弹飞是谁导演的"),
AIMessage(content="让子弹飞是姜文导演的。")
]
agent_executor.invoke({
"chat_history": chat_history,
"input": "这部电影什么时候上映的?"
})