 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}

为什么需要微调?
我们平常接触到的大模型如 GPT、DeepSeek 等都是基于海量的通用数据训练而成的。
它们具备非常强大的语言理解和生成能力,能够处理多种自然语言任务。
但是,这些模型在某些特定领域或任务上的表现可能并不理想,或者说还能够做到表现的更好。
长文本&知识库&微调的区别
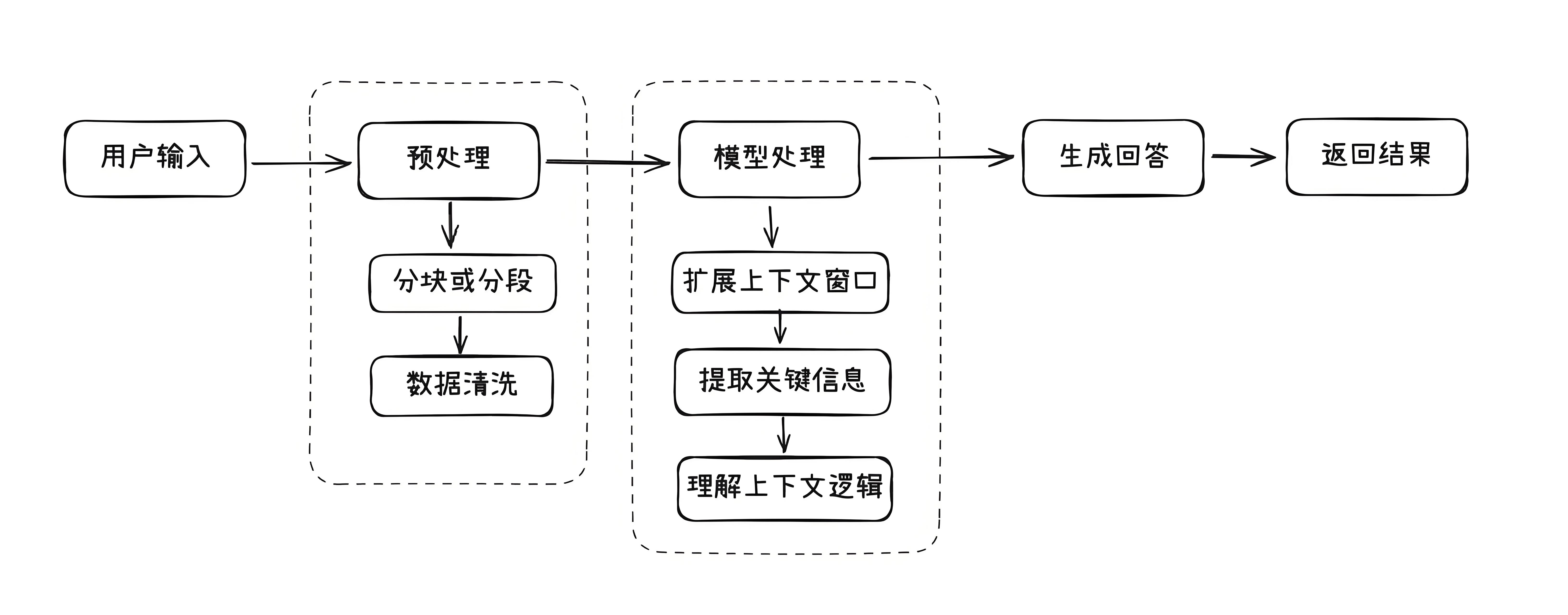
长文本:
模型需要处理很长的文本内容,理解其中的细节和逻辑,然后给出准确的答案。
比如,模型要读完一篇长篇小说,然后回答关于小说情节的问题。
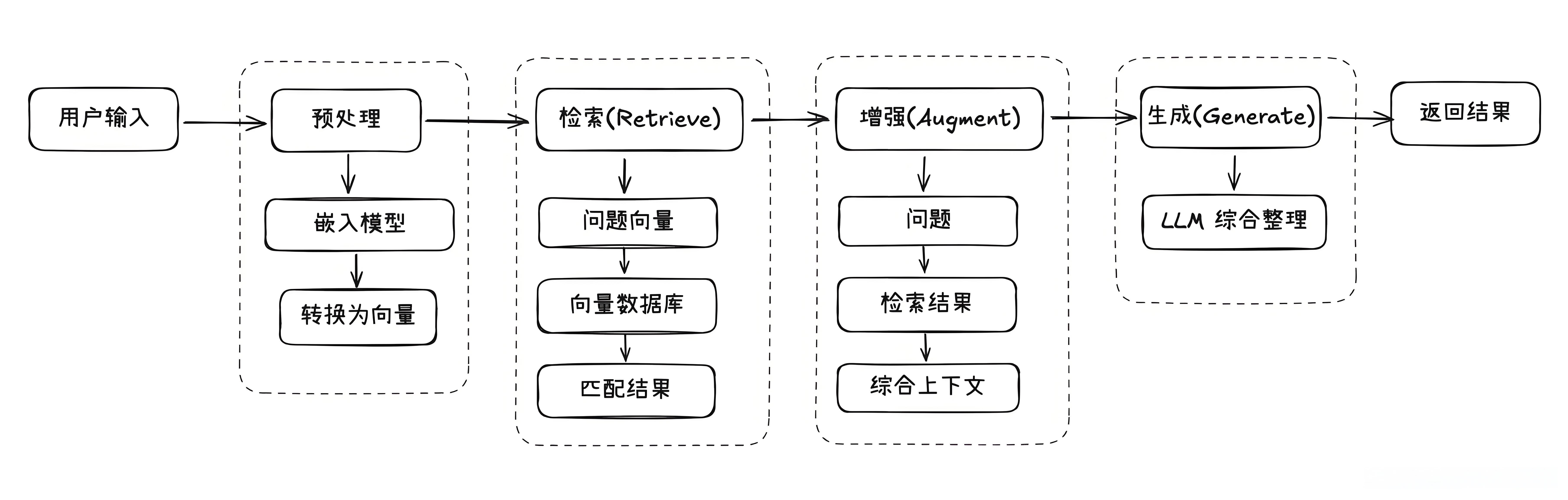
知识库:
知识库就像是一个巨大的资料库,模型可以在里面查找信息,然后结合这些信息来回答问题。
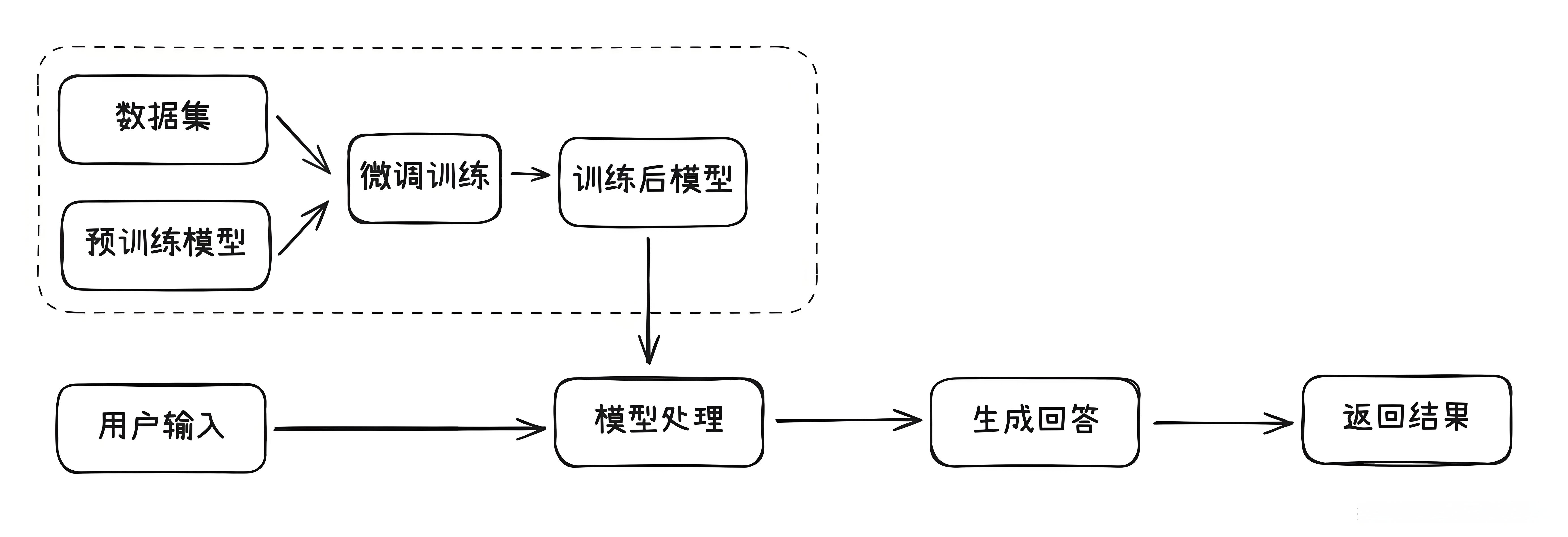
微调:
微调是让模型提前学习一些特定的知识,比如某个领域的专业术语或者特定任务的技巧。
这样它在考试(也就是实际任务)中就能表现得更好。
比如,你让模型学习了医学知识,那么它在回答医学相关的问题时就能更准确。
| 对比维度 | 长文本处理 | 知识库 | 微调 |
|---|---|---|---|
| 核心目标 | 理解和生成长篇内容 | 提供背景知识,增强回答能力 | 优化模型在特定任务或领域的表现 |
| 优点 | 连贯性强,适合复杂任务 | 灵活性高,可随时更新 | 性能提升,定制化强 |
| 缺点 | 资源消耗大,上下文限制 | 依赖检索,实时性要求高 | 需要标注数据,硬件要求高 |
| 适用场景 | 写作助手、阅读理解 | 智能客服、问答系统 | 专业领域、特定任务、风格定制 |
| 额外数据 | 不需要,但可能需要优化上下文长度 | 需要知识库数据 | 需要特定领域的标注数据 |
| 重新训练 | 不需要,但可能需要优化模型 | 不需要,只需更新知识库 | 需要对模型进行进一步训练 |
| 技术实现 | 扩大上下文窗口 | 检索+生成(RAG) | 调整模型参数 |
| 数据依赖 | 无需额外数据 | 依赖结构化知识库 | 需要大量标注数据 |
| 实时性 | 静态(依赖输入内容) | 动态(知识库可随时更新) | 静态(训练后固定) |
| 资源消耗 | 高(长文本计算成本高) | 中(需维护检索系统) | 高(训练算力需求大) |
| 灵活性 | 中(适合单次长内容分析) | 高(可扩展多知识库) | 低(需重新训练适应变化) |
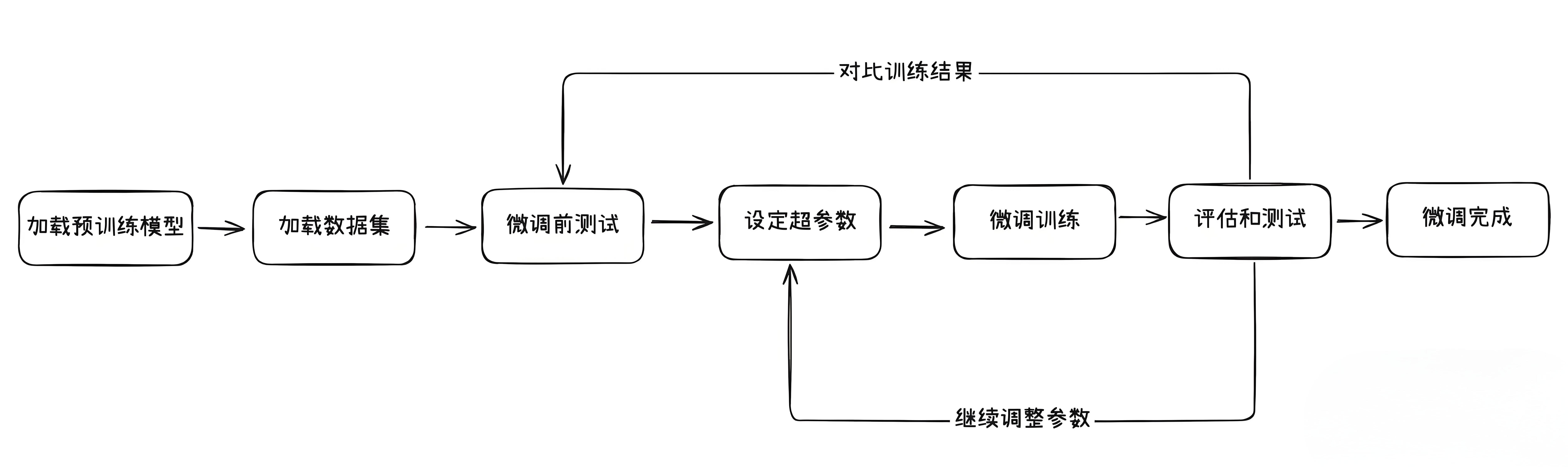
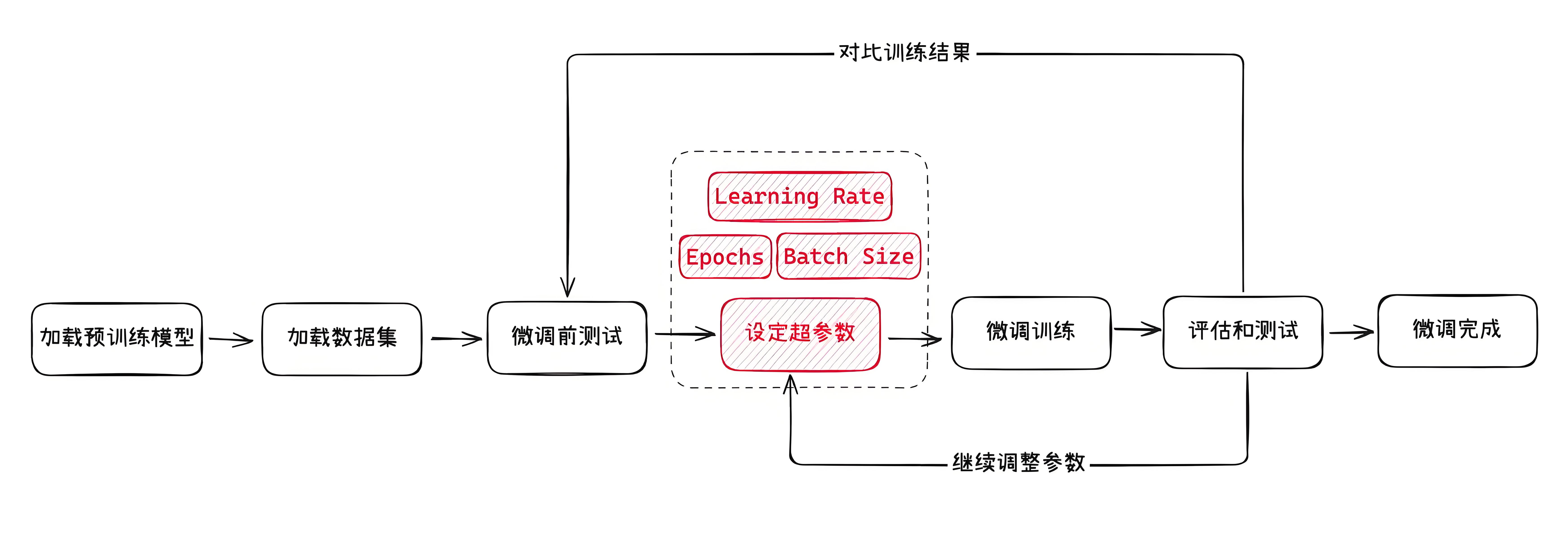
微调基本流程
以下是一个常见的模型微调的过程:
- 选定一款用于微调的预训练模型,并加载。
- 准备好用于模型微调的数据集,并加载。
- 准备一些问题,对微调前的模型进行测试(用于后续对比)。
- 设定模型微调需要的超参数。
- 执行模型微调训练。
- 还使用上面的问题,对微调后的模型进行测试,并对比效果。
- 如果效果不满意,继续调整前面的数据集以及各种超参数,直到达到满意效果。
- 得到微调好的模型。
预训练模型
预训练模型就是我们选择用来微调的基础模型,就像是一个已经受过基础教育的学生,具备了基本的阅读、写作和理解能力。
这些模型(如
GPT、DeepSeek等)已经在大量的通用数据上进行了训练,能够处理多种语言任务。选择一个合适的预训练模型是微调的第一步。
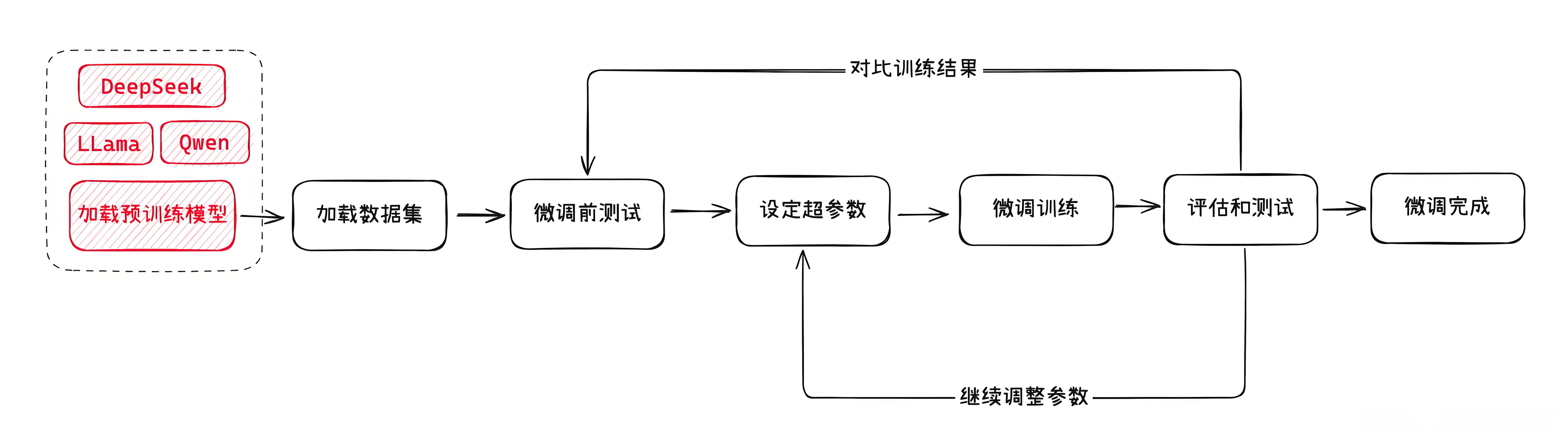
一般来说,为了成本和运行效率考虑,都会选择一些开源的小参数模型来进行微调。
比如
Mate的llama、阿里的qwen,以及最近爆火的DeepSeek(蒸馏版)。
数据集
数据集就是我们用于模型微调的数据,它包含了特定领域的知识和任务要求。
这些数据需要经过标注和整理,以便模型能够学习到特定领域的模式和规律。
比如,如果我们想让模型学会算命,就需要准备一些标注好的命理学知识作为数据集。
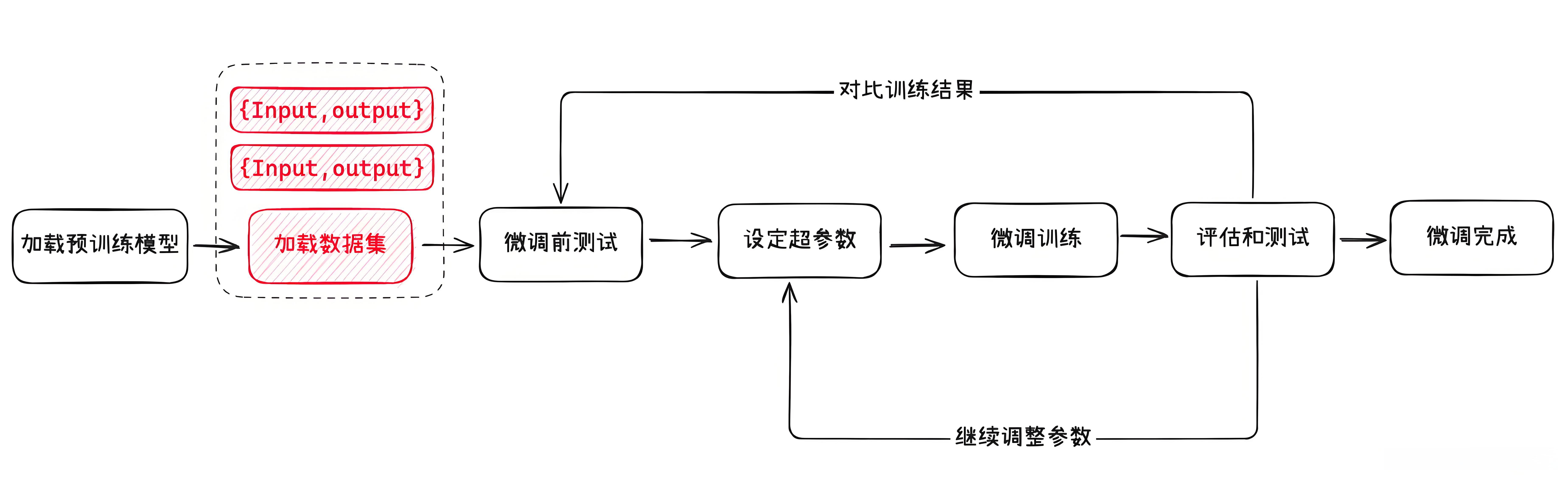
一般情况下,用于模型训练的数据集是没有对格式强要求的。
比如常见的结构化数据格式:JSON、CSV、XML 都是支持的。
可以获取公开数据集的网站:
Hugging Face:是AI模型和数据共享的中心。也可以选择国内的一些类似社区,比如
GitCode的 AI 社区。
超参数
超参数就像是你在给模型制定的教学计划和策略。
如果你选择的超参数不合适,模型的性能也可能不理想。
通过平台微调大模型
目前市面上很多 AI 相关平台都提供了在线微调模型的能力。
比如以最近比较火的硅基流动为例:https://cloud.siliconflow.cn/
进入硅基流动后台的第二项功能就是模型微调。
选择预训练模型:
尝试新建一个微调任务,选择
Qwen2.5-7B。
准备数据集。
验证数据集:
数据集上传完成后,下一步就是输入一个微调后模型的名字,以及设置验证数据集。
验证数据集就是从我们的整体数据中划分出来的一部分数据。
- 它通常占总数据的一小部分(比如 10%~20%)。
这部分数据在训练过程中不会被用来直接训练模型,而是用来评估模型在未见过的数据上的表现。
简单来说,验证数据集就像是一个模拟考试,用来检查模型是否真正学会了知识,而不是只是背诵了训练数据。
超参数设置:
训练轮数(Number of Epochs)
Epoch是机器学习中用于描述模型训练过程的一个术语,指的是模型完整地遍历一次整个训练数据集的次数。换句话说,一个
Epoch表示模型已经看到了所有训练样本一次。学习率(Learning Rate)
决定了模型在每次更新时参数调整的幅度,通常在 (0, 1) 之间。
- 也就是告诉模型在训练过程中学习的速度有多快。
学习率越大,模型每次调整的幅度就越大,学习率越小,调整的幅度就越小。
批量大小(Batch Size)
是指在模型训练过程中,每次更新模型参数时所使用的样本数量。
它是训练数据被分割成的小块,模型每次处理一个小块的数据来更新参数。
微调后调用
微调完成后,我们可以得到一个微调后模型的标识符。
后续我们可以通过接口(/chat/completions)即可直接调用微调后的模型。
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "用当前语言解释微调模型流程"},
]
response = client.chat.completions.create(
model="您的微调模型名",
messages=messages,
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')