 支付宝打赏
支付宝打赏  微信打赏
微信打赏 {kind=link}
Transformer原理
Transformer架构及流程图
Transformer架构用红框分为3大部分,输入、编解码、输出。
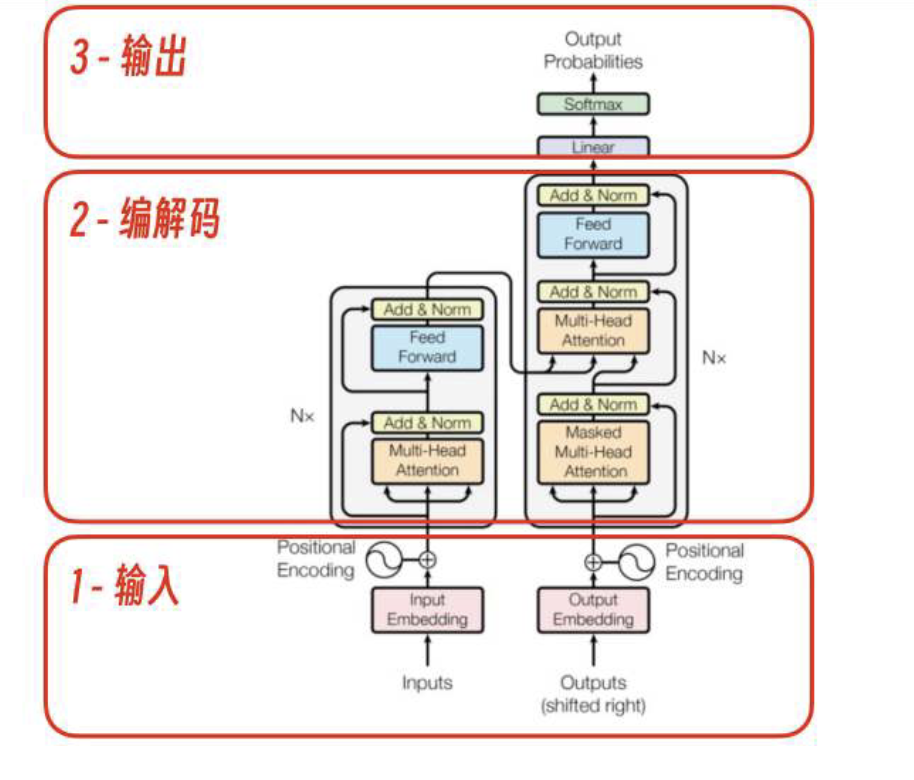
业务视⻆的逻辑流程
Transformer是怎么做到通过输入一段文本,GPT模型就能预测出最可能成为下一个字的字的呢?
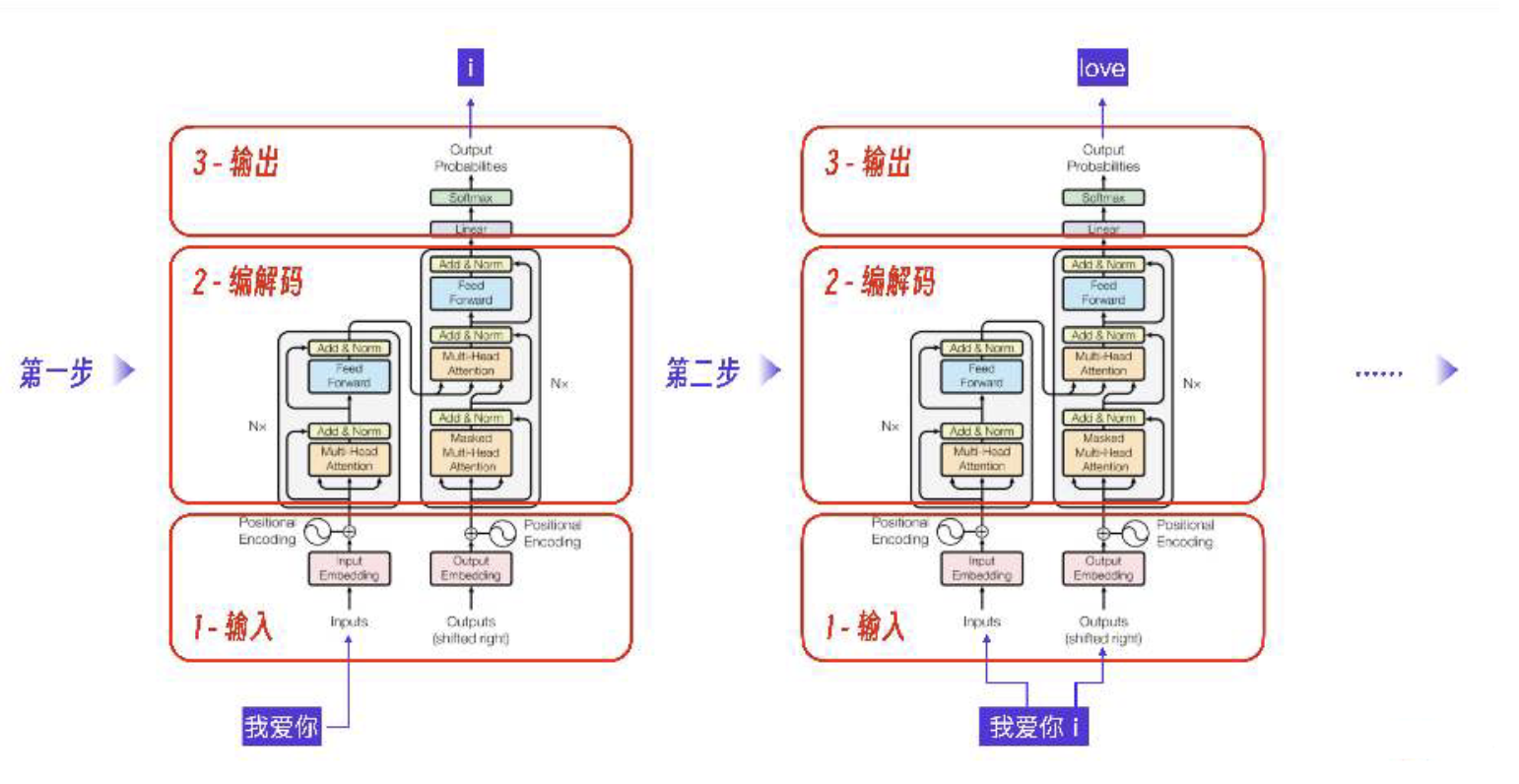
第一步,当Transformer接收到我爱你这个输入,经过1-输入层,2-编解码层,输出下一个字符i。
第二步,此时的输入变为了我爱你加上第一步的输出i,Transformer预测的输出是love。
总的来说,就是Transformer架构的输入模块接收用户输入并做内部数据转换,将结果输出给编解码模块。
编解码模块做核心算法预测概率,输出模块根据计算得到的概率向量查词表得到下一个输出字符。
矩阵计算
Transformer架构里的所有算法,其实都是矩阵和向量计算。
Transformer核心算法和结构
最核心的三个算法和结构:Token词表,Embedding向量,Self-Attention算法。
Token和Token词表
Token在Transformer里会作为基本运算单位,用户的输入我爱你和i转换成Token表示就是[我,爱,你,#i]。
注意,Transformer里的每个Token并不仅仅只有一个序号,而是会用一个Embedding向量表示一个Token的语义。
Embedding向量
Transformer架构输入部分第一个流程就是Embedding。
这个过程理解为:Token挨个去词表抽取相应的Embedding。
Self-Attention算法
大模型做预测的时候,会关心或者叫注意当前自己这个句子里的那些重要的词。
这个思想正是自注意Self-Attention这个算法的命名来源。
自注意力机制(Self-Attention)是编解码模块的第一步,也是最重要的一步。
- 目的是计算输入的每个Token在当前句子里的重要性,以便后续算法做预测时更关注那些重要的Token。
ChatGPT
大模型领域有一个词叫智能涌现,指的是当模型数据和参数达到一定规模时,大模型自发出现新的能力或行为。
这些能力或行为并不是在模型设计初期就有过明确计划或预测的,ChatGPT就是一个典型的例子。
ChatGPT的Transformer
ChatGPT没有完全遵照Transformer原始的Encoder-Decoder结构,而是在工程上做了一个创新。
- ChatGPT只用了Transformer原始架构里的解码器部分。
从结果看,这种架构选择使得GPT模型非常擅⻓生成连贯的、上下文相关的文本,并在许多自然语言生成任务中表现出色。
ChatGPT的数据与训练
按照模型训练的先后顺序,可以分为预训练Pre-train,模型微调Fine-Tuning,强化学习RLHF这三个阶段。
预训练Pre-train
ChatGPT的预训练过程就是拿数据集不断地输入Transformer,调整参数的过程。
- 本质还是利用随机梯度下降法,使用数据进行有监督训练。
监督学习的目标,是通过给定的输入(ChatGPT的输入文本)和输出(ChatGPT的输出文本)数据来学习一个函数(含1750亿参数),使得对于新的输入数据,可以预测其对应的输出。
我们知道监督学习的训练数据需要预先经过人工标注,但在ChatGPT预训练过程中却不需要这样预处理数据。
- 这和Transformer的特性有关,Transformer的目标本质上是一个文字接⻰的游戏。
仅仅学会文字接⻰的学生还不能算拥有智能,要喂给ChatGPT足够的数据,它才能出现智能涌现。
好在这些数据都可以方便地获取到,最主要的数据来源是通过爬虫获取的互联网文本数据集。
- 专业的新闻数据集和书籍数据集,ChatGPT类的大模型使用的都是这些公开数据集。
特别注意:
OpenAI 在发表的GPT-2.0论文中就已经强调。
在训练模型过程中,只有高质量的数据才能让模型获得好的效果,低质量的数据只会导致模型学习到垃圾信息。
ChatGPT对训练数据的处理包括了垃圾信息过滤、数据去重、低质语料过滤等一系列精心的数据组织和整理。
- 最终才让ChatGPT做到了相对比较聪明的效果。
模型微调 Fine-Tuning
要让ChatGPT获得专业能力,就需要在预训练模型的基础上做模型微调(Fine-Tuning)。
具体的模型训练过程和预训练是一样的,只是数据不同。
现在ChatGPT只需要在预训练模型的基础上加入这些数据集的训练就可以了。
唯一需要做的只是在数据上加入一个任务指令。
翻译:他每天早上六点起床,然后去跑步。
Hewakesupatsixoʼclockeverymorningandthengoesforarun.
翻译:我们需要更多的信息来做出决定。
Weneedmoreinformationtomakeadecision.
翻译:我们可以在下周开会讨论这个问题吗?
Canwemeetnextweektodiscussthisissue?
例子中的翻译指令就是大模型下面的翻译任务,因此这种微调方法被称为指令微调。
经过专业数据的指令微调之后,大模型同时具备了通用的世界理解能力和专业能力。
除了专业的翻译能力,ChatGPT的编程能力涌现实际上和ChatGPT使用了大量GitHub的开源代码作为数据集有关系。
如果算力足够,ChatGPT还可以通过微调加入各种专业能力,这个过程就像学习某个大学专业一样。
不过,如果仅仅是专业能力很强,还不足以找到工作。
OpenAI在将ChatGPT开放给公众之前,还需要做人类对⻬,其目的是要保证ChatGPT输出的内容对人类没有危害。
- 使用的技术叫强化学习。
强化学习RLHF
可以把强化学习过程理解为一份工作入职前的价值观和行为规范的培训,GPT-3.5是一个具有通用能力的人。
ChatGPT是一个能跟人类配合更好,更没有危害的工作人。
具体怎么做的?
要对每一次用户和ChatGPT会话生成的内容做一个评价反馈是非常困难的。
ChatGPT抛弃传统监督的方法:
- 采用RLHF(Reinforcement Learningfrom Human Feedback,人工反馈的强化学习)来克服这个难点。
第一步,OpenAI找了很多人类数据标注员,针对常⻅的任务写出提问和回答。
- 注意,这些提问和回答都是人类编写的,然后用这些数据对预训练的大模型继续指令微调。
第二步,单独制作一个神经网络模型,模拟人类,给 ChatGPT模型的输出结果打分。
- OpenAI找了很多人不停地使用ChatGPT,并且对同一个问题的不同回答给予评分。
通过几十万条人工标注的评价数据,就可以训练出一个reward模型,它相当于一个人类价值观评判员。
接下来开始RLHF训练。
其过程可以理解为让大模型自己左右互搏,随机给自己提问,通过reward模型评价自己的回答,进一步调整参数。
- 最终获得和人类对⻬的大模型。
ChatGPT还巧妙地利用了用户的反馈继续强化学习。
如果你用过ChatGPT,可能都遇到过就是ChatGPT会让你从两个回答中选一个。
- 这其实就是利用你来对结果做人类评价。
MOE架构
它通过训练N个小的专家模型、多个模型协作来达到整体上更强的智能,这种架构可以降低训练成本。
Ollama
Ollama构建了一个开源大模型的仓库,统一了各个大模型的开发接口。
- 让普通开发者可以非常方便地下载,安装和使用各种大模型。
本质上,Ollama是一套构建和运行大模型的开发框架,它采用的模型量化技术进一步降低了大模型对显存的需求。
模型量化
模型量化技术调整了每个模型参数的精度,从FP16精度压缩到4位整数精度。
- 这样就可以在基本不改变模型能力的前提下,把显存需求降低到原来的1/4到1/3。
于是,经过模型量化的7b大小的大模型就可以借助Ollama在普通人的电脑上运行了。
模型微调
插件开发
如果要给自己的专用大模型增加一个算法能力,比如互联网搜索、代码执行等,需要修改大模型推理部分的代码。
也就是我们平常说的大模型插件开发,一个插件对应一个专有的功能。
提示词
零样本训练zero-shot
如果大模型这个新员工不需要任何示例就能完成能力迁移,那当然是最好的。
少样本训练few-shot
如果zero-shot效果不好怎么办?可以用one-shot给模型提供一个示例。
或者用ew-shot给模型提供几个示例,指导它生成所需的输出。
把AI当人看待:
把AI当人的重要策略就是要相信大模型的逻辑推理能力。
如果你发现它在逻辑推理上表现不好,可以通过提示词引导它一步步深入思考。
- 让它自己对自己思考的每一步做合理的解释,它自然就会变得非常有逻辑。
使用结构化的提示词:
所有的结构化段落都是为了控制大模型,目的是将大模型的创造性控制在符合场景具体要求的范围之内。
结构化的提示词写法:
具体一点来说就是要控制大模型的⻆色认知、整体目标、不能做什么、能力限定。
工作流程、输出格式、示例以及初始化流程等。