
ShardingSphere基本介绍!
ShardingSphere基本介绍!
月伴飞鱼基本介绍
ShardingSphere 由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 这三款产品组成。
Sharding-JDBC:
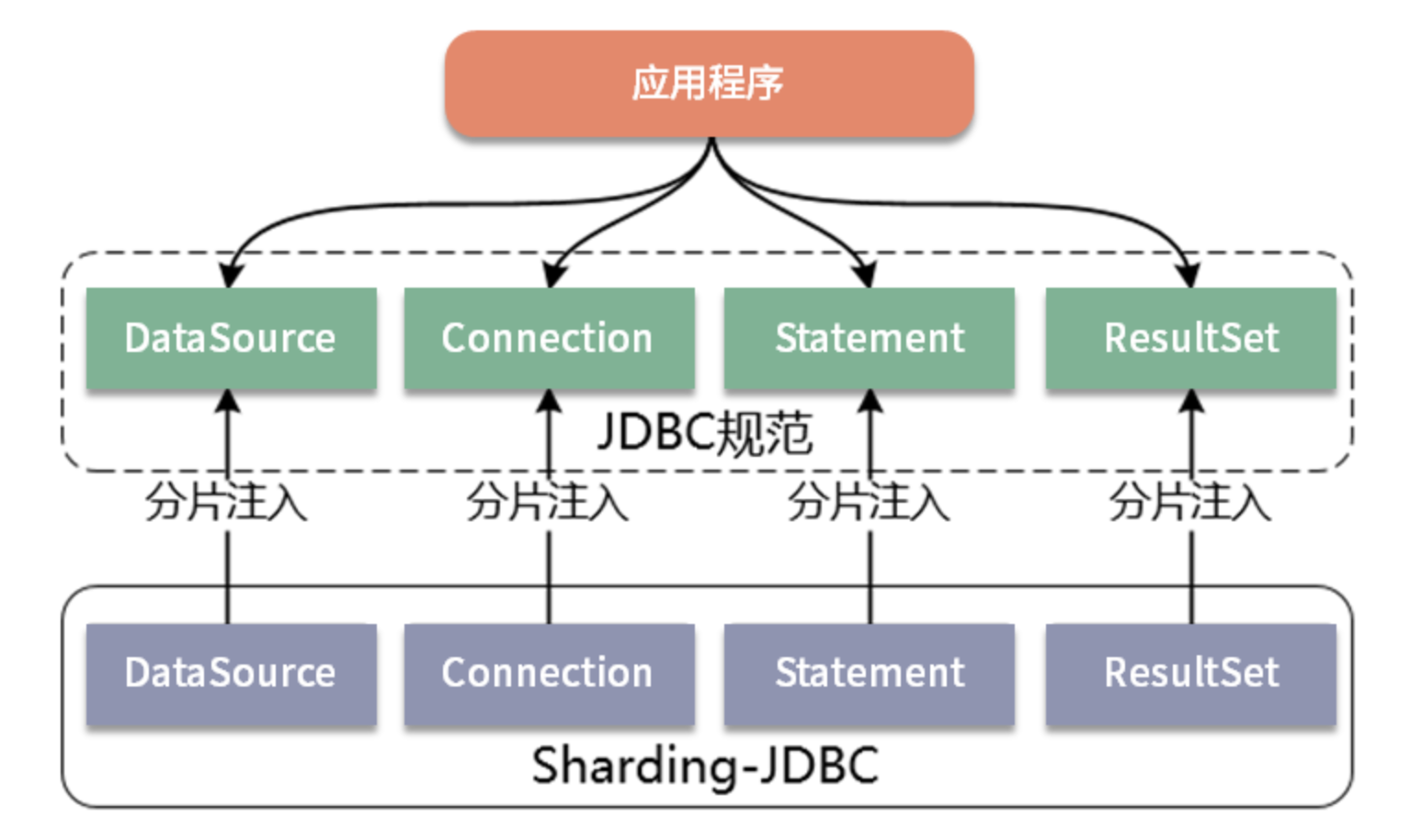
Sharding-JDBC 对外暴露的一套分片操作接口与 JDBC 规范中所提供的接口完全一致。
开发人员只需要了解 JDBC,就可以使用 Sharding-JDBC 来实现分库分表。
Sharding-JDBC 内部屏蔽了所有的分片规则和处理逻辑的复杂性。
Sharding-Proxy:
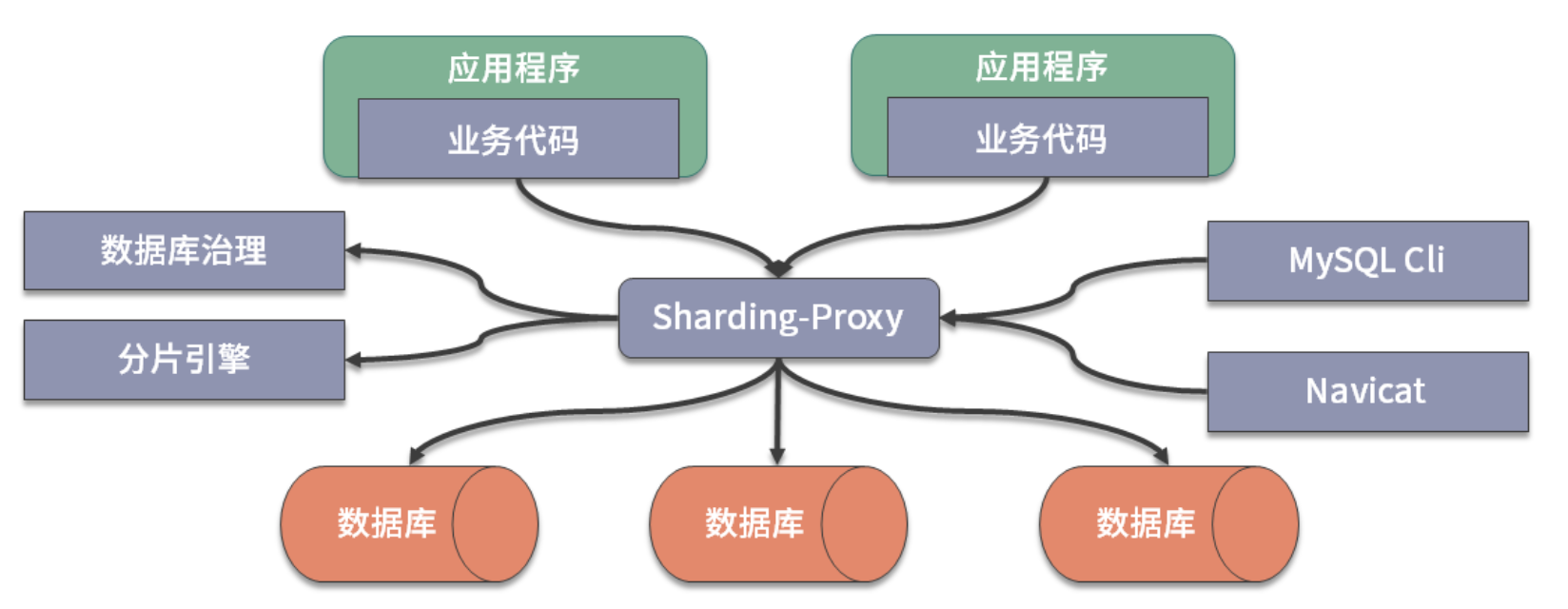
Sharding-Proxy 组件定位为一个透明化的数据库代理端,所以它是代理服务器分片方案的一种具体实现方式。
Sharding-Proxy 专门对数据库二进制协议进行了封装,并提供了一个代理服务端组件。
Sharding-Sidecar:
以 Sidecar 的形式代理所有对数据库的访问。
分库分表解决方案
分成三大类型:即客户端分片、代理服务器分片及分布式数据库。
客户端分片:
- 所谓客户端分片:相当于在数据库的客户端就实现了分片规则。
- 客户端分片结构:重写JDBC协议。
- 这种解决方案的优势在于:
- 分片操作对于业务而言是完全透明的,从而一定程度上实现业务开发人员与数据库中间件团队在职责上的分离。
- 典型的中间件包括阿里巴巴的 TDDL 以及ShardingSphere。
- 因为 TDDL 并没有开源,所以无法判断客户端分片的具体实现方案。
- 而对于 ShardingSphere 而言,它是重写 JDBC 规范以实现客户端分片的典型实现框架。
代理服务器分片:
- 在应用层和数据库层之间添加一个代理层。
- 有了代理层之后,就可以把分片规则集中维护在这个代理层中,并对外提供与 JDBC 兼容的 API 给到应用层。
- 这样,应用层的业务开发人员就不用关心具体的分片规则,而只需要完成业务逻辑的实现。
- 常见的开源框架有阿里的 Cobar 以及民间开源社区的 MyCat。
- 在
ShardingSphere 3.X版本中,也添加了Sharding-Proxy模块来实现代理服务器分片。分布式数据库:
关系型数据库的缺乏分布式环境下面对大数据量、高并发访问的有效数据处理机制。
在分布式环境下,如果想要基于 MySQL 等传统关系型数据库来实现事务将面临巨大的挑战。
以 TiDB 为代表的分布式数据库的兴起赋予了关系型数据库一定程度的分布式特性:
- 在这些分布式数据库中,数据分片及分布式事务将是其内置的基础功能,对业务开发人员是透明的。
- 业务开发人员只需要使用框架对外提供的 JDBC 接口,就像在使用 MySQL 等传统关系型数据库一样。
ShardingJDBC
基本概念
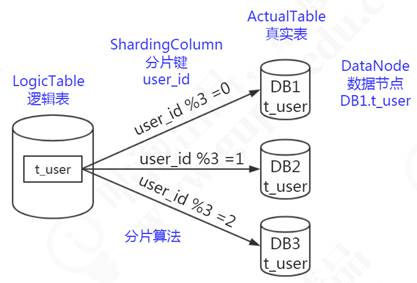
逻辑表:
逻辑表可以理解为数据库中的视图,是一张虚拟表。
可以映射到一张物理表,也可以由多张物理表组成,这些物理表可以来自于不同的数据源。
当针对
t_order表操作时,会根据分片规则映射到实际的物理表进行相关事务操作。
- 逻辑表会在SQL解析和路由时被替换成真实的表名。
1 | spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1} |
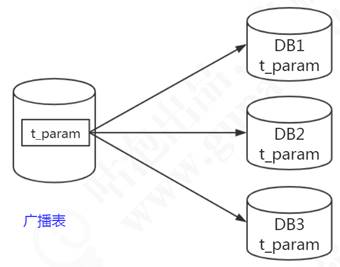
广播表:
广播表也叫全局表,也就是它会存在于多个库中冗余,避免跨库查询问题。
比如省份、字典等一些基础数据,为了避免分库分表后关联表查询这些基础数据存在跨库问题。
- 所以可以把这些数据同步给每一个数据库节点,这个就叫广播表。
1 | # 广播表, 其主节点是ds0spring.shardingsphere.sharding.broadcast-tables=t_configspring.shardingsphere.sharding.tables.t_config.actual-data-nodes=ds$->{0}.t_config |
绑定表:
有些表的数据是存在逻辑的主外键关系的,比如订单表
order_info,存的是汇总的商品数,商品金额。订单明细表
order_detail,是每个商品的价格,个数等等。或者叫做从属关系,父表和子表的关系。
他们之间会经常有关联查询的操作,如果父表的数据和子表的数据分别存储在不同的数据库,跨库关联查询也比较麻烦。
所以能不能把父表和数据和从属于父表的数据落到一个节点上呢?
比如
order_id=1001的数据在node1,它所有的明细数据也放到node1。
order_id=1002的数据在node2,它所有的明细数据都放到node2,这样在关联查询的时候依然是在一个数据库。
1 | # 绑定表规则,多组绑定规则使用数组形式配置spring.shardingsphere.rules.sharding.binding-tables=t_order,t_order_item |
如果存在多个绑定表规则,可以用数组的方式声明:
1 | spring.shardingsphere.rules.sharding.binding-tables[0]= # 绑定表规则列表spring.shardingsphere.rules.sharding.binding-tables[1]= # 绑定表规则列表spring.shardingsphere.rules.sharding.binding-tables[x]= # 绑定表规则列表 |
分片策略
Sharding-JDBC内置了很多常用的分片策略,这些算法主要针对两个维度:
- 数据源分片
- 数据表分片
Sharding-JDBC的分片策略包含了分片键和分片算法:
- 分片键:用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。
- 例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。
- SQL中如果无分片字段,将执行全路由,性能较差。
- 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
- 分片算法:就是用来实现分片的计算规则。
Sharding-JDBC提供内置了多种分片算法,包含四种类型分别是:
- 自动分片算法
- 标准分片算法
- 复合分片算法
- Hinit分片算法
自动分片算法:
自动分片算法,就是根据配置的算法表达式完成数据的自动分发功能,在Sharding-JDBC中提供了五种自动分片算法:
- 取模分片算法
- 哈希取模分片算法
- 基于分片容量的范围分片算法
- 基于分片边界的范围分片算法
- 自动时间段分片算法
取模分片算法:
它会根据分片字段的值和sharding-count进行取模运算,得到一个结果。
1 | # database-mod是自定义字符串名字spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-mod# MOD表示取模算法类型spring.shardingsphere.rules.sharding.sharding-algorithms.database-mod.type=MOD# 表示分片数量spring.shardingsphere.rules.sharding.sharding-algorithms.database-mod.props.sharding-count=2 |
哈希取模分片算法:
和取模算法相同,唯一的区别是针对分片键得到哈希值之后再取模。
1 | # database-mod是自定义字符串名字spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-hash-modspring.shardingsphere.rules.sharding.sharding-algorithms.database-hash-mod.type=HASH_MODspring.shardingsphere.rules.sharding.sharding-algorithms.database-hash-mod.props.sharding-count=2 |
分片容量范围:
分片容量范围,简单理解就是按照某个字段的数值范围进行分片。
(0~199)保存到表0[200~399]保存到表1[400~599)保存到表2。
基于分片边界的范围分片算法:
前面讲的分片容量范围分片,是一个均衡的分片方法,如果存在不均衡的场景。
(0~1000)保存到表0[1000~20000]保存到表1[20000~300000)保存到表2[300000~无穷大)保存到表3。
1 | # BOUNDARY_RANGE 表示分片算法类型spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.type=BOUNDARY_RANGE# 分片的范围边界,多个范围边界以逗号分隔spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.props.sharding-ranges=1000,20000,300000 |
自动时间段分片算法:
根据时间段进行分片。
1 | (1970-01-01 23:59:59 ~ 2020-01-01 23:59:59) 表0[2020-01-01 23:59:59 ~ 2021-01-01 23:59:59) 表1[2021-01-01 23:59:59 ~ 2021-02-01 23:59:59) 表2[2022-01-01 23:59:59 ~ 2024-01-01 23:59:59) 表3 |
标准分片算法:
标准分片策略,它只支持对单个分片健(字段)为依据的分库分表。
行表达式分片算法:
使用 Groovy 的表达式,提供对 SQL 语句中的
=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发:
- 如:
t_user_$->{u_id % 8}表示t_user表根据u_id模 8,而分成 8 张表,表名称为t_user_0到t_user_7
1 | spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.props.algorithm-expression=t_order_$->{order_id % 2} |















{kind=link}